

Nov '25 •
Was ist eigentlich ein LLM? 🤖
Ihr habt sicher schon mal von "LLM" gehört, wenn es um ChatGPT, Claude oder andere KI-Systeme geht. Aber was bedeutet das eigentlich genau? LLM steht für "Large Language Model" – auf Deutsch: Großes Sprachmodell. Was macht ein LLM? Stell dir vor, jemand hat unvorstellbar viele Texte gelesen – Bücher, Websites, Artikel, Gespräche – und dabei gelernt, wie Sprache funktioniert. Genau das macht ein LLM, nur eben mit Rechenpower statt einem menschlichen Gehirn. Ein LLM: - Versteht Zusammenhänge in Texten - Kann Muster in Sprache erkennen - Generiert neue Texte basierend auf dem, was es gelernt hat - Beantwortet Fragen, schreibt Texte, übersetzt und vieles mehr Warum "Large" (groß)? Das "Large" bezieht sich auf die schiere Größe dieser Modelle: - Sie wurden mit riesigen Textmengen trainiert (oft Terabytes an Daten) - Sie haben Milliarden oder sogar Billionen von Parametern (das sind die "Einstellungen", die beim Training angepasst werden) - Sie brauchen enorme Rechenleistung Beispiele für LLMs Die bekanntesten LLMs sind: - GPT-4 von OpenAI (das Modell hinter ChatGPT) - Claude von Anthropic (mit dem ihr hier gerade arbeitet) - Gemini von Google - Llama von Meta Der Unterschied zu "normaler" Software Ein LLM ist keine klassische Software mit festen Regeln. Es wurde darauf trainiert, Wahrscheinlichkeiten zu berechnen: "Welches Wort kommt als nächstes am wahrscheinlichsten?" Das macht es flexibel, aber auch manchmal unvorhersehbar. Kurz gesagt: Ein LLM ist ein KI-System, das auf riesigen Textmengen trainiert wurde und dadurch gelernt hat, menschliche Sprache zu verstehen und zu generieren. Habt ihr noch Fragen zu LLMs? Schreibt sie in die Kommentare! 👇

Nov '25 •
Token – das Geheimwort der KI
Stell dir vor, du fütterst eine KI mit Text. Aber die KI liest nicht wie wir Wort für Wort – sie zerlegt alles in kleine Häppchen, sogenannte Tokens. Was genau ist ein Token? Ein Token ist die kleinste Einheit, mit der ein KI-Modell arbeitet. Aber Achtung: Ein Token ist nicht automatisch ein Wort! Je nach Sprache und Wortlänge kann ein Token ein ganzes Wort sein, nur ein Wortteil oder sogar ein einzelnes Sonderzeichen. Schauen wir uns das konkret an: Das einfache englische Wort „cat" ist ein einzelner Token. Aber das deutsche Wort „Künstliche" wird in mehrere Tokens zerlegt – etwa „Künst" und „liche". Noch extremer wird es bei zusammengesetzten Wörtern wie „Donaudampfschifffahrtsgesellschaft" – das zerfällt in eine ganze Reihe von Tokens. Warum macht die KI das so? Die Modelle wurden mit riesigen Textmengen trainiert und haben dabei gelernt, welche Zeichenkombinationen häufig vorkommen. Diese häufigen Muster werden zu Tokens. Seltene oder lange Wörter müssen aus mehreren Tokens zusammengesetzt werden. Eine praktische Faustregel: Bei deutschen Texten entsprechen 100 Tokens ungefähr 60-75 Wörtern. Bei englischen Texten kommt man auf etwa 75-80 Wörter pro 100 Tokens, weil englische Wörter im Schnitt kürzer sind. Auch Leerzeichen, Satzzeichen und Zeilenumbrüche verbrauchen Tokens. Selbst Emojis kosten Tokens – manche sogar mehrere! Wie arbeitet die KI mit Tokens? Wenn du einen Prompt eingibst, passiert Folgendes: Zuerst zerlegt ein sogenannter Tokenizer deinen Text in einzelne Tokens. Jeder Token bekommt eine Nummer aus dem „Vokabular" des Modells – einer riesigen Liste aller bekannten Tokens. GPT-4 kennt beispielsweise über 100.000 verschiedene Tokens. Die KI verarbeitet dann nicht deinen Text, sondern diese Zahlenfolge. Sie berechnet für jeden Token Wahrscheinlichkeiten: Welcher Token kommt als nächstes am wahrscheinlichsten? So entsteht die Antwort – Token für Token, wie eine Perlenkette, die Stück für Stück aufgefädelt wird. Das erklärt übrigens auch, warum KI manchmal „halluziniert": Sie wählt immer den statistisch wahrscheinlichsten nächsten Token, auch wenn das Ergebnis inhaltlich falsch ist.

Nov '25 •
KI Training – Was bedeutet das eigentlich?
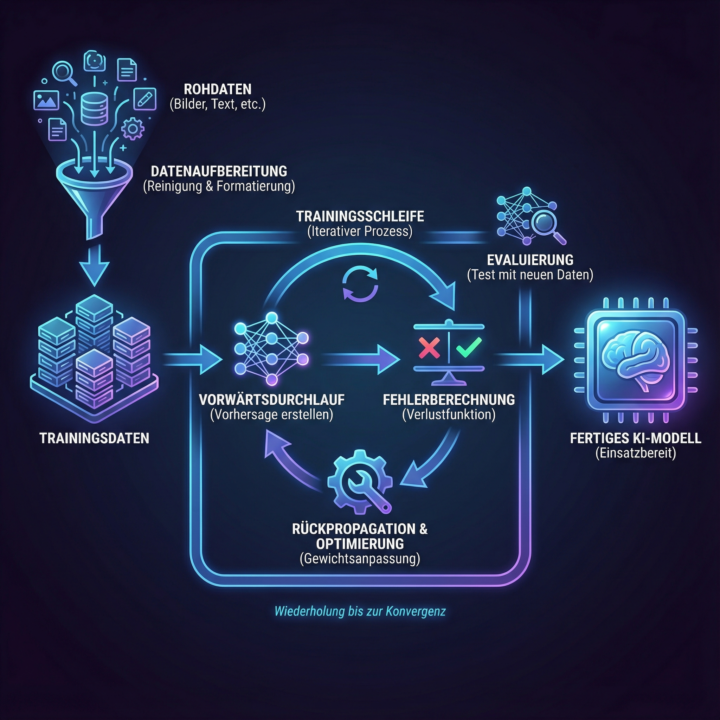
Hey zusammen! 👋 Der Begriff "KI Training" taucht ständig auf – aber was steckt wirklich dahinter? Lass mich das mal auseinanderklamüsern, weil's gleich drei verschiedene Bedeutungen hat: 1. Training VON KI-Modellen 🤖 Das ist der technische Aspekt: Wie lernt eine KI eigentlich? Stellt euch vor, ihr zeigt einem Kind tausende Bilder von Katzen und sagt jedes Mal "Das ist eine Katze". Irgendwann erkennt das Kind Katzen selbst. Bei KI läuft's ähnlich – nur mit Millionen von Beispielen und komplexen Algorithmen. ChatGPT wurde zum Beispiel mit riesigen Textmengen gefüttert und lernte dabei Muster, Zusammenhänge und Strukturen. Das passiert EINMAL vor der Veröffentlichung. Danach ist das Modell "eingefroren". 2. Training FÜR Menschen (KI-Kompetenz aufbauen) 💪 Das ist genau das, was wir hier in der Community machen! Ihr lernt, wie ihr KI-Tools effektiv nutzt. Das umfasst: - Welche Tools gibt's? - Wie prompte ich richtig? - Wo liegen die Grenzen? - Welche Workflows funktionieren? Das ist die "menschliche Superkraft" – zu wissen, wie man KI als Werkzeug meisterhaft einsetzt. 3. Training MIT KI 🎯 KI als persönlicher Trainingspartner nutzen. Beispiele: - Sprachen lernen mit ChatGPT als Konversationspartner - Präsentationen üben und Feedback bekommen - Fachthemen vertiefen durch gezielte Fragen - Neue Skills entwickeln (Coding, Design, etc.) Warum ist das wichtig zu verstehen? Wenn jemand sagt "Die KI wurde falsch trainiert", meint er #1 – das könnt ihr nicht ändern. Wenn jemand sagt "Ich brauche KI-Training", meint er #2 – genau dafür sind wir hier! Und wenn ihr sagt "Ich trainiere mit KI", nutzt ihr #3 – die praktische Anwendung. Mein Tipp: Konzentriert euch auf #2 und #3. Das Training der Modelle (#1) überlasst ihr den Tech-Konzernen. Eure Superkraft liegt darin, die fertigen Tools meisterhaft zu beherrschen! Frage an euch: Wofür nutzt ihr KI als Trainingspartner? Welche Skills baut ihr gerade auf? 👇
6
0
Nov '25 •
❄️ Kennst Du den Begriff "KI Winter"?
Gerade läuft ja überall die Hype-Maschine auf Hochtouren. Jeden Tag neue AI-Features, jeden Tag neue Ankündigungen. ChatGPT hier, Gemini da, Claude dort. Aber wusstest Du, dass es sowas schon mal gab – und dass danach ein eiskalter Winter kam? Der erste KI-Hype startete in den 1960er Jahren. Forscher waren sich sicher: In 20 Jahren haben wir denkende Maschinen! Die Regierungen pumpten Millionen in die Forschung. Und dann... kam nix. Die Computer waren zu langsam, die Algorithmen zu simpel. Ergebnis: Alle Gelder wurden gestrichen. KI-Winter Nummer 1. Runde 2 in den 1980ern: Expertensysteme sollten die Welt revolutionieren! Japan investierte Milliarden ins "Fifth Generation Computer Project". Und wieder: Die Versprechen waren zu groß, die Ergebnisse zu mager. KI-Winter Nummer 2. Die Frage ist: Droht uns jetzt KI-Winter Nummer 3? Meine ehrliche Einschätzung: Nein. Diesmal ist es anders. Warum? - Die Technik funktioniert JETZT schon im Alltag - Milliarden Menschen nutzen sie täglich - Die Rechenkraft ist da - Die Daten sind da - Die praktischen Anwendungen sind real Aber: Es wird eine Ernüchterung geben. Nicht jedes Startup wird überleben. Nicht jedes Feature wird halten, was es verspricht. Und viele Leute werden merken, dass KI kein Zauberstab ist, sondern ein Werkzeug. Was bedeutet das für uns? Genau deshalb ist es so wichtig, JETZT die Grundlagen zu lernen. Zu verstehen, was KI kann – und was nicht. Und die Tools zu beherrschen, die auch in 5 Jahren noch relevant sind. Wie siehst Du das? Kommt der nächste KI-Winter? Oder sind wir diesmal am Anfang von etwas wirklich Großem? 👇 Schreib's in die Kommentare!
Poll
12 members have voted

Nov '25 •
Was ist ein Token? Die Währung der KI-Welt
Stell dir vor, du gehst mit einem Freund in ein Restaurant. Ihr bestellt Pizza – aber bezahlt wird nicht pro Pizza, sondern nach jedem einzelnen Happen, den ihr esst. Klingt verrückt? Willkommen in der Welt der KI-Tokens! Token sind die Buchstaben-Happen der KI Wenn du mit ChatGPT, Claude oder anderen KI-Systemen plauderst, rechnen die im Hintergrund nicht in Wörtern oder Zeichen. Die rechnen in Tokens. Und Tokens sind... nun ja, Happen. Kleine Informationshäppchen. Ein Token ist ungefähr ein Wort. Manchmal auch nur ein Wortteil. Oder ein paar Buchstaben. Die KI zerlegt deine Eingabe in diese Tokens und verarbeitet sie dann nacheinander. Beispiele: - "Hallo" = 1 Token - "Künstliche Intelligenz" = meist 2-3 Tokens - "Superkraft" = oft 1-2 Tokens - "KI" = 1 Token Deutsche Wörter sind oft länger als englische – deshalb verbrauchen wir im Deutschen oft mehr Tokens. Ein "Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz" frisst ordentlich Tokens! Warum ist das wichtig für dich? Weil Tokens die Währung sind, mit der KI-Dienste abrechnen! Jeder Chat-Verlauf hat ein Token-Limit. Bei ChatGPT sind das aktuell etwa 128.000 Tokens für den gesamten Gesprächsverlauf (hin UND her). Claude kann sogar 200.000 Tokens verarbeiten. Was heißt das praktisch? Je länger eure Unterhaltung wird, desto mehr Tokens sammeln sich an. Irgendwann ist das Gedächtnis der KI voll – wie ein Notizblock, auf dem kein Platz mehr ist. Dann "vergisst" die KI die ersten Teile eurer Unterhaltung. Der Praxis-Trick: Token-Bewusstsein entwickeln Wenn du komplexe Projekte mit KI machst, solltest du tokens im Blick behalten: - Kurz und knackig: Formuliere deine Prompts präzise statt romanhaft - Neuer Chat für neue Themen: Starte lieber einen frischen Chat, statt ewig weiterzuplaudern - Kontext gezielt füttern: Gib der KI nur die Infos, die sie wirklich braucht Ein durchschnittlicher Chat-Verlauf verbraucht vielleicht 5.000-10.000 Tokens. Ein mega-ausführliches Briefing mit langem Output? Schnell mal 20.000-30.000 Tokens.

1-5 of 5

skool.com/superkraft-ki
KI verstehen. KI nutzen. Superkräfte aktivieren.
Leaderboard (30-day)
1

+24
2

+20
3

+16
4

+12
5

+8
Powered by