Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Owned by Eduard
Ziele des SKOOL Playground 🍀 Wachstum 🎲 Sandbox für SK👀 L-Admins 🤖 Hooks, Gamification & AI-Agenten Mach mit! 🚀
Memberships
The AI Advantage
124.9k members • Free
KI Transformation: Claude Code
360 members • Free
CashFlow mit Immobilien
87 members • Free
KI Coding Masterclass
85 members • $87/month
KI Business Agenten
195 members • $97/month
GOOSIFY 🍎🐛🦋🌈⭐️🩷
13k members • Free
AI Automation Society Plus
3.8k members • $99/month
🇩🇪 Berlin IRL
184 members • Free
29 contributions to AI Bits and Pieces

🔥
Apr 14 •
🎯 New Deal Strategy: AI Training for 200 Employees
For all you aspiring solo AI agencies and entrepreneurs out there, you will appreciate this story. I was recently engaged to conduct an “Intro to AI” training for 200 employees. Less than a year ago, I was the president of a tech marketing company on a totally different path. One day, I was presented with a fork in the road opportunity and took the AI path. Today, I run a full AI agency offering AI Opportunity Mapping, AI Readiness Assessments, AI App Prototyping, and enterprise AI workflow and automation solutions. More recently, I’ve also added something I call “strategic workforce resiliency”, a strategy to prepare and future proof your business with AI. How did I get here, by surrounding myself with like minded people in the AI industry. In a community like AI Bits & Pieces where professionals like @Matthew Sutherland @Collin Thomas @Mike AI Consultant @Usman Mohammed @Nick Mohler are building, testing, sharing, and talking through real AI business challenges. It speeds things up. It gives you better pattern recognition. It helps you not just use AI, it teaches you to start building with it. Another thing that has changed for me is how I structure client value. I now include my beginner AI fluency training, AI Bits & Pieces, as a free service when signing a multiple month agreement for corporate clients. That has been a strong move because it raises the baseline AI understanding across the team and it completely avoids the “can you do this for less money” conversation. The discussion becomes about value, capability, and how to actually move the business forward with AI. A lot can change in less than a year when you are in the right room - with the right people. Thank you to the members in this community that help us sharpen the saw for all of us to get better.

2 likes • Apr 16
Congratz
🔥
Apr 10 •
🎉Celebrating 600 Members and Growing!
We just crossed 600 members in AI Bits & Pieces. Consistent growth from day one, fueled by people trying to understand what AI actually means for their work and day-to-day life—and how it can help them stand out in the workforce, business environment, or executive ranks. That’s been the goal from the start. A place for: 🔵 AI Curious — figuring out what this all is 🟢 AI Enthusiasts — using it regularly 🟠 AI Practitioners — applying it to real work 🟣 Enterprise — thinking about scale across teams What’s been interesting isn’t just the number—it’s the mix of people and the conversations starting to take shape. Members are building small things. Members are asking in-depth questions. And members are starting to connect the dots between tools and outcomes. A special shoutout to each and every member, and the people who have supported me from the beginning: @Michele Wacht @Dena Dion @Debra Schmitt @Patti Hoekstra @Mark Zayec @Matthew Sutherland @Jason Hagen @Usman Mohammed @Nick Mohler @Eduard Friesen We have some exciting updates and new offerings for the community designed to help you win the AI game in life, at work, as a business owner, or as an agency. A heartfelt thank you. Michael

1 like • Apr 10
Awesome. Well deserved 🤘
🔥
Mar 12 •
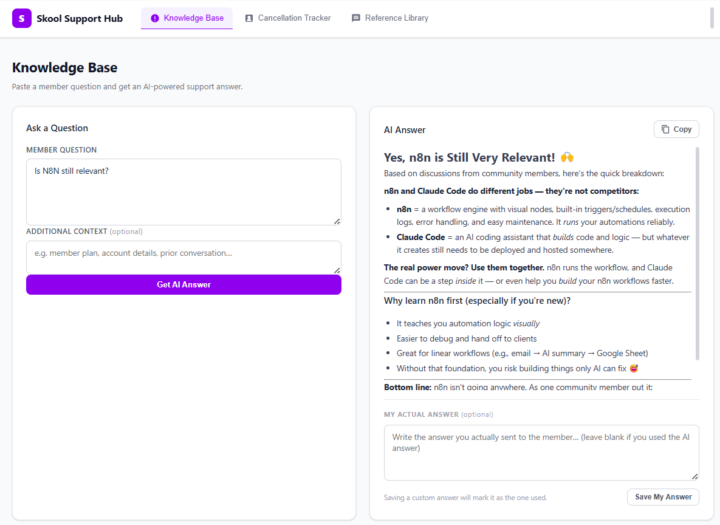
😬 I Was Nervous to Try Claude Code. I Was Wrong to Be. First App Done!
Let me be honest with you. When I first heard people talking about Claude Code — this AI tool that supposedly builds apps for you — my reaction was somewhere between curious and skeptical. Not dismissive. I follow AI closely enough to know that things are moving fast. But nervous. Because I've been burned before by tools that promised to be easy. I'm not a developer. I understand how software works — databases, logic, tables, if-then statements — but I can't write code. I'm a business owner who runs a Skool community, and my day is full enough without adding "learn to code" to the list. So I sat on Claude Code for a while. Watched others talk about it. Told myself I'd try it "when I had time." You know how that story usually ends. 🚀 What Finally Made Me Try It The tipping point was Nate Herk, founder of AIS+. I religiously watch his videos and the new series on Claude Code is fantastic. One video turned into five, five turned into an entire evening of watching a non-developer build real, working tools with nothing but plain English prompts. I couldn't stop watching. And underneath the fascination was a very specific frustration that had been quietly building for weeks. I was copy-pasting the same answers to member DM questions for the tenth time that week. I had no clean system for tracking what questions members were asking. And my templates were scattered across three different Google Docs I could never find quickly enough. Nothing was broken exactly. It was just... exhausting. And watching Nate easily build apps in Claude Code made me realize this was exactly the kind of problem software was supposed to solve. I just hadn't believed I was the kind of person who could build that software. Low code or no code apps using Lovable sure, but a real app - a bridge to far. Nate's videos changed that belief. So I decided to test it. 💡 What I Expected vs. What Actually Happened
0 likes • Apr 7
nice. I subscribed Claude in October 25 ....and it took me 2 months to try Claude code 🤐 Daily discussion of mine with different people "I have ChatGPT premium. I dont need anything else" 🙄
🔥
Apr 4 •
Why the Entire AI Industry is Talking About Claude Code.
If you follow AI news, you've seen it everywhere. Everyone is talking about "Claude Code" and "building without developers." Here's what's happening: People are building custom software by describing what they need in natural language. The barrier between "I need a tool" and "I have a tool" is getting very close to coming down. Where we actually are: To be honest, the current tools will probably be more comfortable for people that program or have programmed at some point in their career. However, people that are "technical", not "programmers" are now starting to build full applications by describing what they need. People like - myself. That's new. And it shows where AI is headed. Soon, the person who knows how to fix the problem will build the solution. With natural language. Here are some real examples: Community manager: Built a tool that tracks member questions and shows what content to create. Content creator: Built a system that writes posts for different social platforms. Support lead: Built a hub where the team gets answer from an AI Agent. These people aren't developers. They just understand their workflows. And that's becoming enough. Why this is different. Past "no-code" tools made you think like a developer. With Claude Code it is becoming more and more like a conversation: - "I need to track cancellations and see why people leave. "Tool gets built. - "Can it show trends over time? "Feature gets added. You're describing, not coding. However, as stated earlier, if you're not technical, this still feels like a stretch. But tools like Claude Code are making the conversation more natural. The barrier isn't gone. But it's thin enough to see through. Why pay attention now? Just six months ago you needed to code. Today you need to understand technical concepts. Six months from now: might just need clear explanation. So no, this is not “anyone can build anything” yet. But it is the first time that people who truly understand a workflow can realistically start turning that understanding into software.
3 likes • Apr 4
[attachment]

Mar 29 •
Cloudflare just made AI security free for everyone
Quick one worth knowing. Cloudflare announced AI Security for Apps is now generally available. The part that matters: AI discovery is free on every plan, including the free tier. What does that mean for you? If you're building anything with AI (chatbots, agents, automations, internal tools), Cloudflare can now automatically find and catalog every AI-powered app running on your infrastructure. It works regardless of which model you're using or where it's hosted. Why this is worth knowing: Most people building AI tools don't think about security until something breaks. Rogue AI tools are a real problem. People spin up AI experiments, connect them to real data, and forget about them. Cloudflare's discovery feature finds those forgotten deployments so you can decide what stays and what goes. The practical takeaway: If you're on Cloudflare (even the free plan), turn on AI discovery. It takes minutes. You can see every AI tool running on your site. That used to cost real money. And if you're building AI tools for clients or your own business, this is a free security layer you can add to any project. "We secured it with Cloudflare AI protection" is a real thing you can say now. In a client meeting, on a project page, wherever it matters. If you're on Cloudflare, go poke around your dashboard. If you're not, this is a good reason to look at it.

2 likes • Mar 30
very g👀d stuf
1-10 of 29
