Activity
Mon
Wed
Fri
Sun
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Jorden
We give you the most dominantly unfair advantage in the agency space. The most installed GoHighLevel AI ever.
Build AI agents that run your life — not just answer questions. ClawMakers is where OpenClaw builders share real-world setups.
Memberships
AI Agency Insiders
6 members • Free
LeadIndicator.ai
561 members • Free
2303 contributions to Assistable.ai

2d •
Concurrent Calls Capped at 1?
Has anyone else run into this? I'm on the Enterprise plan which should support up to 20 concurrent calls, but I'm only able to receive one call at a time. When a second call comes in, the caller gets put on hold until the first call ends. Then the second call picks back up. I should be handling at least 2 calls simultaneously, let alone 20. Anyone experience this or find a fix?

0 likes • 7h
@Joel M concurrent is unlimited right now, the function isn’t it the calling flow - check up stream providers like numbers fwding to us

3d •
Does your assistant sometimes just… not reply? 👀
Be honest — it's happened to all of us. Customer messages come in. The assistant is supposed to respond. And sometimes… nothing. No reply. No error. No warning. You only find out when the customer ghosts or complains. The worst part? We have no way to catch it inside GHL. Why? Because GHL has a "Customer Replied" trigger, but there is no "User Replied" trigger. So we can't build a simple safety net like: 👉 Customer replies → wait 5 minutes → did the assistant actually send a message? → if not, alert me. That workflow is impossible today. Which means every missed reply = a lost lead we never even knew about. If this has burned you even once, please go upvote this GHL idea 🙏 🔗 https://ideas.gohighlevel.com/automations/p/user-team-member-replied-trigger-needed The more of us who push, the faster GHL builds it. This affects every single person running Assistable on HL. Let's fix it together. 💪 Drop a 🔥 if your assistant has ever left you hanging.
0 likes • 2d
@Wateeb Khan try taking it off for next campaign just to juxtapose
2 likes • 2d
@Wateeb Khan bump wait time up just a tad Try our key bc it’s highest tier Make sure the tag is the very very first action so we catch it in time

2d •
Sonnet 4.6
If possible to include the LLM Sonnet 4.6 @Jorden Williams ? The performance of Haiku in chat for Spanish is great and also for voice... but I thing Sonnet in Voice it well be awesome, thank you!
2 likes • 2d
We are gonna do Openrouter in v3 so unlimited LLMs
2 likes • 2d
@Victor S. Yeah we got that in

3d •
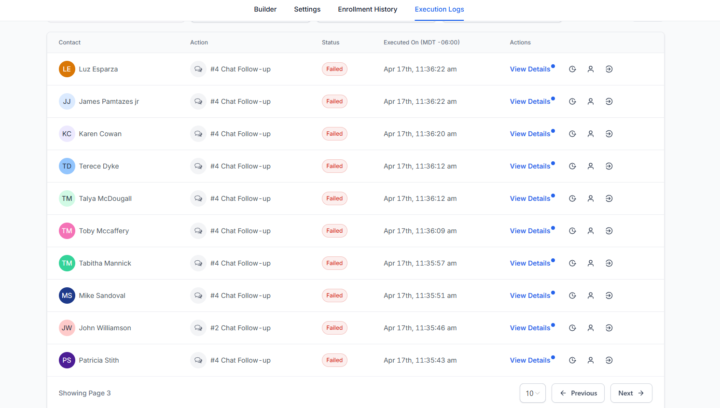
Chat Follow Up Not Working, On ALL accoutnts
Hey guys. Love all the different changes. Everything is going fine in the voice side; however we have noticed that almost every single one of our chat follow-ups has now been failing. This is creating an endless loop of the same message going out over and over and over again. Unfortunately this is not happening on just one of our accounts. This seems to be occurring on every single one of our accounts. What is the best way of getting this rectified inside of the forever follow up drip? @Assistable Ai @Assistable Team @Jorden Williams @Mike Copeland @Bernie White
0 likes • 3d
@Jonathan Ferrell okay looks good - any changes to assistants or anything recently? Tools?
0 likes • 3d
@Jonathan Ferrell hmmmm. What happens when you switch back to OpenAI

6d •
Conversation log view feature request
I'm sure you guys aren't working on like 10 billion fucking things and I'm sure you'd love another feature request. But here goes. I was wondering if there could be a way where we could see and filter in the inbox for the conversations to see only messages where the AI has replied so that we can look in there and get a better pulse of how things are going
1 like • 5d
I like this idea, this is on our drawing board RN
1-10 of 2,303

Active 7h ago
Joined Jan 30, 2024
ENTJ
Boca Grande, FL
Powered by