Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Owned by Scott
Words To Film By™ is your film IP incubator, not just another writing group: Learn ► Create ► Fund ► Launch = You can do this, 1000s before you have
Slash taxes, boost cash flow! CCSP-expert led. Free analysis, weekly Q&A. 1-on-1 coaching. Transform your RE investments now! 🚀🔑 CPA, RE, Investor🚀
Memberships
New Society
423 members • $77/m
AI CAPTAINS
131 members • $40/month
Agent Zero
2.7k members • Free
AI Developer Accelerator
11.3k members • Free
Synthesizer: Free Skool Growth
44.3k members • Free
AI Agents by BUSINESS24.AI
941 members • $24/m
START HERE
27 members • Free
58 contributions to Agent Zero

4d •
Agent Zero v2.0 is here 💡What's new and how to upgrade
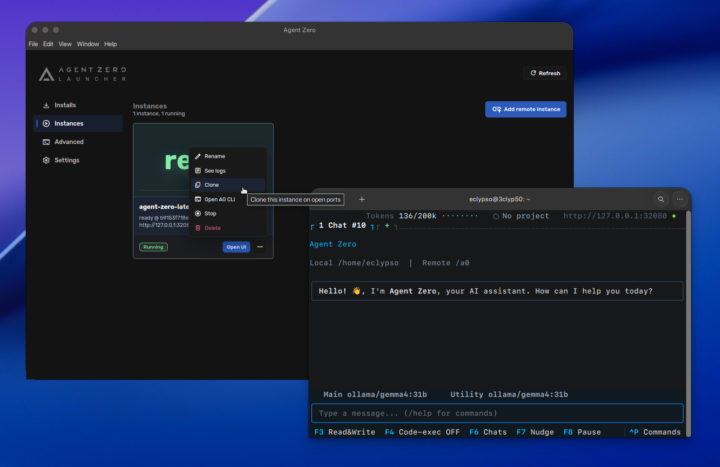
This is our first major release after the UI redesign of the version 1 line, and it's really three things shipping together. 1. A0 Launcher (our new product) A desktop app for Windows, macOS and Linux. It manages your local and remote Agent Zero instances from one place, and, for anyone just starting, it onboards new users with an installer that sets up the container runtime automatically. You don't need to understand Docker to get running. Visit https://www.agent-zero.ai and look right above the install scripts. There is a download link for your platform and a link to a Launcher first run guide. - Mac Intel - https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-macos-x64.dmg - Linux x86 - https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-linux- - Windows x86 - https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-windows-x64.exe ARM64 - Mac Apple Silicon - https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-macos-arm64.dmg - Linux ARM64 - https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-linux-arm64.AppImage - Windows ARM64](https://github.com/agent0ai/a0-launcher/releases/download/v0.9/a0-launcher-0.9-windows-arm64.exe) | 2. Agent Zero Core v2.0 The engine itself: native Responses API transport (with chat-completions fallback), inspectable parallel tool calls, project-scoped MCP configuration with search and scanning, a Skills Scanner for checking packages before import, and a refreshed WebUI across welcome, composer, settings, mobile and the shared canvas. Full changelog at https://github.com/agent0ai/agent-zero/releases

1 like • 4d
Congratulations

Jan 6 •
Agent0: SwarmOS edition "Your personal AI, but it can securely collaborate with your friends' AIs?"
I really think I found something interesting for the future of Agent0, so in this thread I share some of the chaos. Started one way, switching Agent0, Pear Runtime and Hyperswarm = <3 Pivoting from "Fully autonomous machine-control swarm" idea to A private, encrypted multiplayer mode for Agent Zero idea The Pitch - You run your agent locally (like always) - You join a topic/swarm with people you trust - Your agents share research, split tasks, pool knowledge - Everything stays off corporate servers ______________________________ Current state ( older, going towards Fully autonomous machine-control swarm ) Agent Zero: SwarmOS Edition A decentralized, serverless agent swarm powered by Agent0, Pear Runtime and Hyperswarm. This branch extends Agent Zero with a P2P sidecar, enabling autonomous multi-agent collaboration, shared memory, distributed storage, and a real-time visual dashboard ("SwarmOS"). 🌟 Key Features 1. Decentralized Discovery (Hypermind) - Agents automatically discover each other via the Hyperswarm DHT. - Zero Configuration: No central server or signaling server required. - Self-Healing: Peers automatically re-connect if the network drops. 2. SwarmOS Dashboard A React-based "Mission Control" for your agent. - Live Topology: Visualize the swarm network graph in real-time. - Data Layer UI:Local Drive: Browse files stored in the agent's Hyperdrive.Cortex Memory: Watch the agent's "thoughts" stream live from Hypercore. - A2UI: Render custom JSON interfaces sent by other agents. 3. Distributed Data Layer - Shared Memory (Hypercore): An append-only log for agent thoughts and logs. - Distributed File System (Hyperdrive): P2P file storage for sharing artifacts (images, code). - Identity Persistence: Ed25519 key pairs managed via identity.json.

1 like • Mar 17
I don't know if it works completely yet, going into testing now. https://github.com/bybren-llc/rendertrust Would like to see how KTP would work by connecting into a system like this RenderTrust. RenderTrust should have the ability to negotiate securely with another system to receive some kind of service or product let's say.
0 likes • Apr 29
@Bill Wilson Me too. I got picked up on a contract and I've been heads down on it. We should catch up Sir.

Feb 14 •
Agent Zero Skills Demo (launch a Meta Ads campaign)
Thought I'd share. Made a new A0 project and plugged in these skills: https://github.com/coreyhaines31/marketingskills Created and launched a whole sales funnel and Meta ads campaign. Gnarly times!
2 likes • Feb 15
Interesting times indeed. Big updates as A0 drives towards v1.0.0
Feb 6 •
v0.9.8 Testing is out! (New UI, Skills, Git Projects) 🧪
Hey everyone, A huge update just hit the testing branch. We have completely overhauled the UI and the core architecture. Here is what’s new (just a quick summary, the full changelog will follow): 1. UI & UX Overhaul - Message Queue: Don't wait for the agent to finish. Queue your next instructions, and they'll be processed sequentially. - Collapsible Chat: Execution steps are now grouped. Expand to see details, collapse to keep it clean. - Step Detail: Open a modal for deep debugging on any step. - File Editor: You can finally edit files directly in the File Browser UI. 2. The New Skills Architecture We replaced "Instruments" with the SKILL.md Standard. - UI Management: Import and manage skills from a dedicated tab. - Agent or Project Based: You can now import skills specifically for the agent or for the project. 3. Git Projects Agent Zero can now "switch brains" with Git repositories. - Context Isolation: Switch projects, and the agent adapts its context and skills instantly. How to try it: just pull the testing tag: agent0ai/agent-zero:testing. Follow the attached video for Docker Desktop. Please report any bugs you find in a new post!

0 likes • Feb 10
This is a big one. Git projects are clutch
Dec '25 •
Claude Code Harness for Multi-Agent Team Workflows
This is what I run in Claude Code. Goal is to have A0 manage as the overall Orchestrator of Orchestrators, if you will, via Terminals or subagents? We discussed a bit in weekly meet. Maybe this helps someone. Just takes small amount of customization to fit your needs! https://github.com/bybren-llc/wtfb-safe-agentic-workflow What This Is A production-tested Claude Code harness for teams that want structured AI workflows. Built on SAFe methodology (Scaled Agile Framework), adapted for AI agent teams. Works for any team with repeatable processes: Software, Marketing, Research, Legal, Operations. Includes: - 17 Model-Invoked Skills - Domain expertise Claude loads automatically - 23 Slash Commands - Workflow automation for common tasks - 11 SAFe Agent Profiles - Specialized roles with clear boundaries - Three-Layer Architecture - Hooks → Commands → Skills

1 like • Jan 30
@Justin Brown I updated to be a template now that doesn't bring anything but the harness. now includes setup command to help setup to fill in VARs needed to complete the harness setup https://github.com/bybren-llc/safe-agentic-workflow and updated the name
0 likes • Jan 30
@Max Life I'm thinking if you ran a container somehow with Claude Code you could.
1-10 of 58

@cheddarfox
POPM. To become somebody you've never been, you must do things you've never done.
Active 1d ago
Joined Aug 31, 2024
Tampa, FL
Powered by