

4d •
Someone Used AI to Measure Office Stress 😬
Ever wondered which coworker secretly raises your blood pressure? One developer decided to find out. He used Claude Fable 5 to pull heart rate data from his WHOOP tracker, then matched stress spikes with meetings on his calendar. What he got was a surprisingly detailed ranking of coworkers based on which meetings seemed to stress him out the most. It's a funny experiment, but it also shows how easy it has become to build highly personalized tools with AI. A project like this would've been a headache not long ago. Now it's the kind of thing someone can put together over a weekend.

8h •
An open-weights Chinese model just hit #2 on coding — right as the US pulled Claude's best models offline
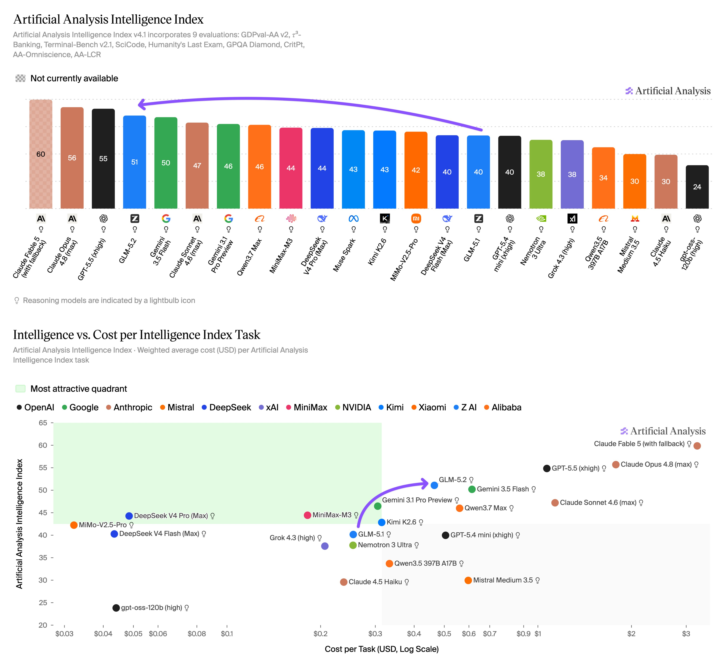
The timing on this is almost too perfect. Let me connect the dots 👇 The news: Z.ai (formerly Zhipu AI) released GLM-5.2 with full MIT-licensed open weights. The benchmarks: → #2 on Code Arena, behind only Fable 5 — ahead of Claude Opus 4.7 AND 4.8 in thinking mode.→ Within ~1 point of Opus 4.8 on agentic coding.→ Beats GPT-5.5 on long-horizon coding benchmarks — at roughly 1/6th the cost.→ Ranks #1 among ALL open-source models. It's a 753B mixture-of-experts model that only activates ~40B parameters per query, so it punches at frontier level without frontier compute. MIT license means you can download it, fine-tune it, and run it commercially with basically zero restrictions. Now here's why the timing matters: Three days ago, the US government pulled Fable 5 and Mythos 5 offline for all foreign nationals. So for any developer or business outside the US, the most capable Claude models just vanished overnight. And right into that gap drops GLM-5.2 — open weights, self-hostable, frontier-class coding, a fraction of the cost. That's not a coincidence in vibes, it's a coincidence in consequence: when access to closed models gets politically fragile, open weights stop being the budget option and become the strategic one. My take for builders and operators: This is the exact argument I made in my Fable shutdown post, now proven in real time. Model access is a geopolitical variable. The thing that makes open weights powerful isn't just price — it's that nobody can switch them off. You download GLM-5.2 once, it's yours. No directive, no export control, no API ban takes it away. For anyone building client work: a model this capable, this cheap, that you can self-host, is a genuine option for production now — not a toy. The "open models can't keep up" excuse is dead. #2 on coding, behind only a model the government just banned, says it plainly. The honest caveat — and it's important: If you use Z.ai's hosted API, you're subject to China's National Intelligence Law, which can compel data sharing. For anything sensitive — healthcare, client data, regulated work — that's a real risk. BUT: the MIT open weights let you self-host and sidestep that entirely. So the move for serious use isn't "call their API," it's "run the weights yourself." Know the difference. It matters.
2d •
Is Fable 5 Really That Powerful… Or Is Something Else Going On?
The recent restrictions around Anthropic’s Fable 5 have sparked a lot of debate. Some people are treating it as proof that we’ve crossed a major AI milestone. Others think it’s just another hype cycle ahead of a potential IPO. My take? The truth is probably somewhere in the middle. If regulators are willing to step in, there is likely a genuine concern about the model’s capabilities or potential misuse. Governments don’t usually restrict technology without a reason. At the same time, we still haven’t seen enough independent evidence to conclude that Fable 5 is dramatically ahead of every other frontier model. What we’re seeing could be a combination of:• Real technical breakthroughs• Legitimate security concerns• Competitive positioning• Political influence• Media amplification The most interesting question isn’t whether Fable 5 is “dangerous.” It’s whether we’re entering an era where governments start treating advanced AI models the way they treat strategic technologies. If that happens, access to AI may become a geopolitical issue-not just a technology issue. What do you think? Is Fable 5 genuinely a step change in AI capability, or are we watching the world’s most sophisticated marketing campaign unfold in real time?
3d •
OpenRouter just shipped "ask 5 AIs and merge the best answer" as a single API — and it beats Fable 5
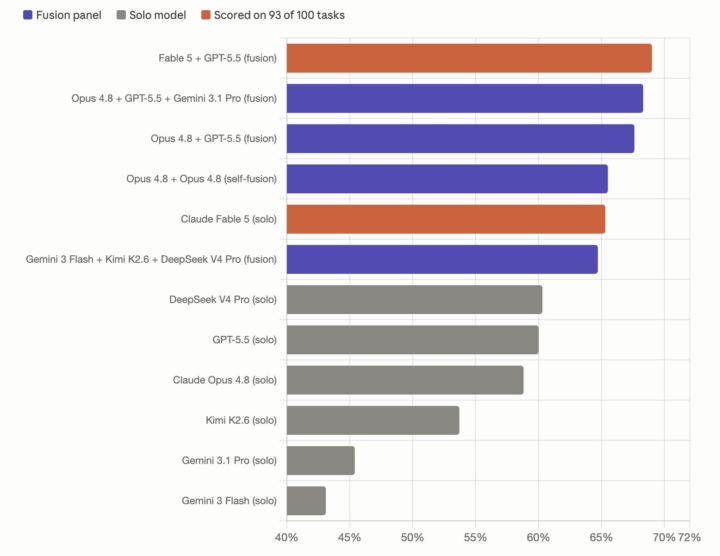
This is the most underrated launch of the week, and it maps almost exactly onto something I already use. Let me break it down 👇 What OpenRouter Fusion does: Instead of sending your prompt to one model, Fusion fires it at a panel of 3–5 models in parallel, then a "judge" + synthesis model merges all their outputs into one optimized answer. You call it as a single slug — openrouter/fusion — and it layers on top of the 400+ models OpenRouter already routes to. No rebuild. The results are what make it interesting: → A Fable 5 + GPT-5.5 panel, synthesized by Opus 4.8, hit ~69% on Perplexity's DRACO research benchmark — beating solo Fable 5 at ~65%. → The budget play is the real story: a cheap panel (Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro) matched Fable-level quality at roughly HALF the cost. The one stat everyone should sit with: OpenRouter says ~75% of the performance gain comes from the synthesis step — how the outputs get merged — and only ~25% from using different models. The intelligence isn't in running more models. It's in how you combine them. My take on why this matters: If you've seen me talk about the LLM Council approach — running a question past multiple AI advisors, having them critique each other, then synthesizing a verdict — this is that exact idea shipped as production infrastructure. The era of "pick the one best model" is quietly ending. The edge is moving to orchestration: who can combine models intelligently. For builders and operators, two takeaways: One — you no longer have to bet your whole workflow on one model. Panel the frontier ones for hard reasoning, panel cheap ones when budget matters. Especially relevant this week, when frontier models can apparently get switched off overnight. Multi-model isn't just better — it's insurance. Two — the honest tradeoff: you pay for every model in the panel (4 models = 4 completions) and it adds latency. So this is for high-value tasks where a better answer is worth the spend — deep research, complex analysis — not your everyday quick prompts.
6d •
OpenAI just turned rate limits into a game — and it's a direct shot at Claude
Two days after Claude doubled Cowork limits, OpenAI fired back at Codex. The usage-limit war is officially on 👇 What OpenAI launched: → Banked resets — instead of your limit reset firing automatically on a timer, you can now save it and trigger it whenever you want. You control when you get topped up. → A referral program — invite a friend, they complete their first Codex task, and you BOTH earn an extra reset. Up to 3 friends, two-week window. Totally free. My take on what's actually happening: Remember my Cowork post? Claude doubled limits because Codex runs on fewer tokens. Now OpenAI counters — not by adding raw capacity, but by making their limits feel generous and putting growth on autopilot through referrals. This is the same war, two different moves. Claude throws firepower. OpenAI throws flexibility + a growth loop. Both are fighting for the same thing: developer loyalty in agentic coding. The smart bit OpenAI pulled: they took their single biggest complaint — confusing, inflexible resets — and flipped it into a feature you control. That's a clinic in turning a weakness into a retention play. Why you should care as a builder: You're the winner here. Two labs are competing on how much they'll give you, and how much control you get over it. Pick the tool that fits your workflow — but right now is the cheapest, most generous moment to be running agentic coding on either platform. The bigger lesson is the playbook itself: take your #1 customer complaint and turn it into your next feature. That works in YOUR business too. Team Claude or team Codex right now? And be honest 👇

1-20 of 20

skool.com/systems-to-scale-9517
A community for mastering AI, Agents, and Automation.
Join today for immediate value!
Leaderboard (30-day)
1

🔥
+140
2

+93
3
+90
4

+57
5

+46
Powered by