
Pinned

4d •
New n8n Video out now + FREE Weekly AI Call today (5EST)
n8n has a built in tool to create workflows. Here is everything you need to know from credit usage to how to access it and write your first prompts https://youtu.be/paOQ6bWEBGw
Pinned
Jan 12 •
17 Hour FREE n8n v2 Course is out now!
All of the resources for the course are in the classroom Excited to share with you what I worked on over the past few weeks https://www.youtube.com/watch?v=TZ43SRdTMs0
Pinned
Nov '25 •
Let's Break The Ice 🧊
Drop a comment below and share: 1) A career goal you're working toward 2) A personal goal that matters to you 3) Your favorite music artist right now Let's get to know the people behind the profiles. I'll go first in the comments! 👇

Mar 28 •
Building a Linear AI Prospecting Engine with n8n
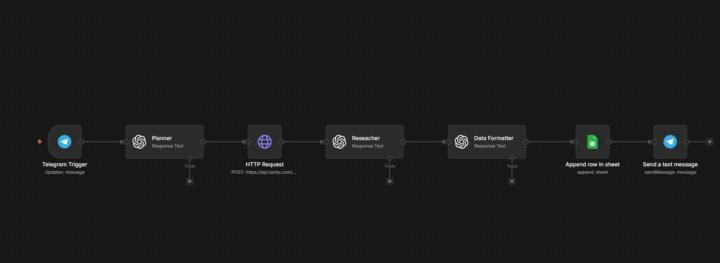
My second agent is officially live! After the Content Scout, I’ve moved into B2B sales automation. Instead of complex "black-box" agents, I’ve built a high-reliability Linear Engine that performs deep web research and structures data for CRM. Key Tech Stack: 🔹 n8n (Linear Workflow) 🔹 Tavily API (Live Web Search & Scraping) 🔹 OpenAI GPT-4o (Analysis & Data Formatting) 🔹 Google Sheets (CRM Integration) What it does: It doesn't just find names. It identifies specific automation gaps for the client and writes a personalized ice-breaker based on live news. Just open-sourced the JSON on my GitHub for the community! Check it out here: https://github.com/Evgeniy1970-ai/AI-Lead-Gen-Prospecting-Engine Feedback from fellow builders is highly appreciated! #n8n #AIAutomation #BuildInPublic
May 3 •
How I automated 5 core restaurant operations with AI agents — modular architecture breakdown
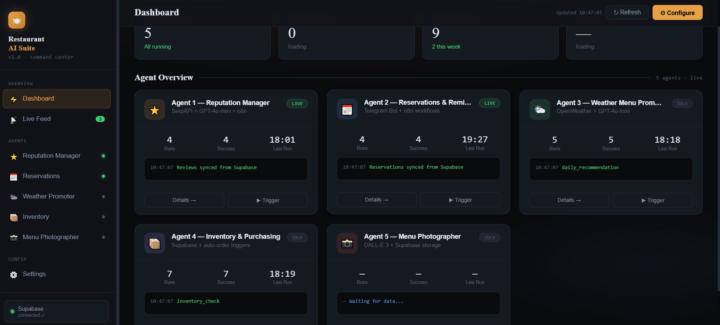
Hey everyone 👋 Finished a portfolio project I'm excited to share — a Restaurant AI Suite that automates 5 core areas of restaurant operations. The problem it solves: Restaurant owners spend hours every week on tasks that can be fully automated — checking reviews, handling bookings, monitoring stock, promoting the menu. This system handles all of it. 🍽️ What it does: → Monitors reputation on Google Maps, TripAdvisor & Yelp — AI sentiment analysis every 6 hours → Handles reservations via Telegram bot — auto-confirms by email, sends reminder 24h before → Recommends menu items daily based on live weather conditions → Checks inventory and sends low-stock alerts before items run out → Analyzes dish photos with AI vision and generates professional menu photos with DALL-E 3 All results go into a live dashboard the owner can check from their phone. 💡 The key design decision: modular architecture. Each agent is an independent n8n workflow. The client can start with 1 agent and add more over time — without touching existing workflows. Need a guest return engine? Delivery bot? Social media poster? Each one slots in as a new agent. This is the approach I use for all client projects now — start small, expand modularly. Full project on GitHub: github.com/Evgeniy1970-ai/restaurant-ai-suite Portfolio: neolithai.netlify.app Has anyone here built automation for HoReCa clients? Would love to hear what challenges you ran into.
1-30 of 411

skool.com/data-and-ai
For operators and builders who want to actually profit from AI — not just learn about it.
Leaderboard (30-day)
1

+9
2
+7
3

+7
4

+6
5

+5
Powered by