
Pinned

💎
⭐
4d •
🚀New Video: Claude Code for Non-Coders (6 Hour Course)
This is a complete beginner course on becoming AI native with Claude Code, no coding background required. I take you from your very first prompt all the way to building your own skills, sub-agents, a second brain, and automations that run on their own in the cloud. It's all real examples and step-by-step builds, so you can follow along and walk away with AI systems that actually do work for you. Feel free to skip around using the timestamps below to whatever piques your interest.
Pinned

🔥
5d •
🏆 Community Wins Recap | July 4 – July 10
From AI operating systems and first client deliveries to open-source tools, second brains, and personal AI assistants, this week inside AIS+ showed that the best products often start by solving your own problems first. 🚀 Standout Wins of the Week inside AIS+ 👉 @Miguel Alfonso Murillo closed 3 clients using the AIOS he built for his own business, sharing how his journey evolved from experimenting with ChatGPT to running his operations with AI. 👉 @James Joens delivered his first client project just 11 days into AIS+, saving his client $1,400 on a single deal and following it up with his first in-person cold outreach meeting. 👉 @Jenni Saarenpää built her own AI-powered Wealth Analyzer after realizing the tool she wanted didn't exist, creating a personal FIRE planning app with powerful financial modeling. 👉@Konstantinos Karamatzianis built and open-sourced Session Guardian, solving Claude Code session limits for himself before sharing it with the entire community. 👉 @Girish Mohan created an AI Treasurer to manage expenses for a 100-person family festival, turning a real-life headache into a practical automation. ⸻ 🎥 Super Win Spotlight | @Jacob West Jacob joined AIS+ looking to build a business, not just learn AI. Since then, he has: - Built the confidence to leave his job and go all in on entrepreneurship - Closed larger AI projects by applying real business fundamentals - Shifted from learning tools to building a scalable business around them His biggest takeaway? Skills matter. But confidence comes from building, taking action, and surrounding yourself with people already doing what you want to do. 🎥 Watch Jacob's story 👇 ✨ Every week, members turn personal projects into client work, ideas into systems, and momentum into real businesses.

Pinned
💎
⭐
Jun 3 •
What do you get if you upgrade to AIS+?
Some of you have never heard of the AIS+ community. Others have but the part that trips you up is the actual difference between the two. Either way, this post will give you clarity. This free group is a bundle of quick resources pulled from my YouTube videos, plus a massive open community that anyone can join. It's a great place to get your bearings and see what's possible. But it's open to everyone, it can be noisy and overwhelming, and there's no path through it. You can get help from other members, but I rarely answer questions here. AIS+ is the opposite: - A step by step roadmap with a clear order, so you're never guessing what to do next - A much smaller community of people who are seriously committed to building and selling AI agents - I answer questions every day and run a weekly Q&A call where you can get direct access to me For the course material: The roadmap takes you from zero to building and selling AI agents, and the whole thing is built on the latest tech like Claude Code and Codex. We update it constantly. The old n8n material has been archived. It's still there if you want it, but it's no longer the focus, because the way you build today has moved on and the courses moved with it. Here's the actual roadmap inside, in order, with when each piece opens up: 1. Start Here (opens the moment you join). Gets you oriented. How the community works, the path ahead, and how to get help when you need it. 2. Build Your Portfolio (opens the moment you join). Why a portfolio matters, beginner level tutorials, and what types of projects to focus on. You end up with real work you can show a client. 3. Claude Code (opens the moment you join). This is now its own dedicated course. Build faster, turn ideas into working automations, and go deep on the tool serious builders are using right now. This takes you from beginner to advanced, step-by-step. 4. Get Your First Clients (opens after 30 days). Getting your first clients is hard, because you don’t have any case studies yet. So, we analyzed all of the success stories from our members and found they get their initial clients with two different techniques: warm outreach and Upwork. So, we teach both techniques in detail with exactly what to say, exactly how to position yourself when you have no proof.
💎
⭐
19h •
🚀New Video: The $200K AI Job That Didn't Exist Last Year
This opportunity is real, and most people will miss it until it's too late. Twelve months ago nobody was hiring for this, and now companies are quietly building it from the inside out. I break down the exact four step roadmap to land this $200K job using AI. Hope you enjoy!

1d •
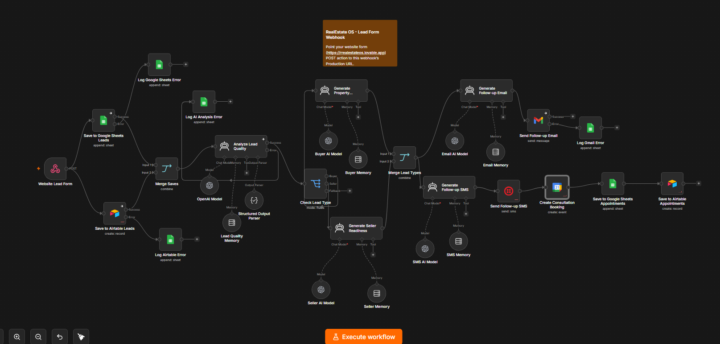
🏡 RealEstate OS — I Built a Full AI-Powered Lead-to-Close Automation with n8n
Just shipped RealEstate OS — an end-to-end AI automation that takes a lead from "fills out a website form" to "booked consultation" with zero manual work. Here's what it does under the hood: 🔹 Captures leads via webhook from any website form 🔹 Dual-writes to Google Sheets + Airtable for redundancy 🔹 Uses AI agents to analyze lead quality and classify lead type (buyer vs seller) 🔹 Routes to specialized AI agents that generate personalized property recommendations, seller readiness assessments, and follow-up messaging 🔹 Auto-sends follow-up emails and SMS tailored to the lead 🔹 Books consultations straight into Google Calendar 🔹 Full error-logging pipeline so nothing silently fails Built entirely in n8n with chained AI agents (OpenAI), memory buffers, structured output parsing, and multi-channel delivery (Email/SMS/Calendar/Sheets/Airtable). This is what "AI agency in a box" actually looks like — not a chatbot, a full operating system for lead conversion. #n8n #AIAutomation #RealEstateTech #NoCode #LowCode #WorkflowAutomation #AIagents #PropTech #LeadGeneration #OpenAI #Automation #BuildInPublic #SaaS #AIWorkflow
1-30 of 21,493

skool.com/ai-automation-society
Learn to get paid for AI solutions, regardless of your background.
Leaderboard (30-day)
1

🔥
+7800
2

🔥
+7769
3

+6765
4

🔥
+4490
5
🔥
+3794
Powered by