Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
Learn Microsoft Fabric
14.3k members • Free
Fabric Dojo 织物
364 members • $30/month
7 contributions to Learn Microsoft Fabric

🚀
Mar '24 •
Trusted Workspace Access for OneLake Shortcuts.
Microsoft have been busy pumping out new security updates this week, this one is: Trusted Workspace Access for OneLake Shortcuts. This feature allows you to securely access (and create shortcuts to) firewall-enabled Storage accounts in ADLS Gen2. You can read more about it here: https://blog.fabric.microsoft.com/en-us/blog/introducing-trusted-workspace-access-for-onelake-shortcuts/ I'll try and fold this into the new video I'm preparing (which includes shortcuts!)

0 likes • Feb 26
Thanks @Will Needham for this post. We implemented shortcuts to files in blob storage so that it can be automated and picked by pipleine and processed further in ETL process. Currently -> I am connecting it using the above steps in Bronze layer for Dev env. My question is when i deploy it to Stage and Prod -> Do I need to create the connection again physically to the files in blob or is there a way that I can copy (shortcut) files to Stage and Prod? Appreciate your help. Thank you!
0 likes • Feb 26
@Will Needham this is the code I am trying to execute. It gives me - Py4JJavaError: An error occurred while calling z:notebookutils.fs.cp. : Operation failed: "Bad Request", 400, HEAD,
Dec '24 •
Data Pipeline executes multiple times
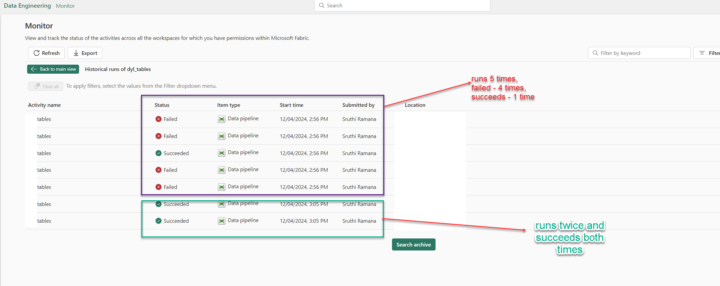
Hello dear community, I am facing an issue with data pipelines. Whenever i try to execute a pipeline in different workspaces.. multiple instances are kicked off. There are times when it runs twice, in one workspace it run 5 times. It doesn't run parallelly but still at times one succeeds while at times other instance fails. But other users who access to the workspace/pipleline DO NOT face this issue. Can you please let me know if there is any setting that I need to change?
1 like • Dec '24
Hello Will, so I tried different scenarios and narrowed it to be possible VPN issue. So when I run the pipeline from office it runs a single instance where as when I run the pipeline when I am home it kicks in 5 instances. I deduced this last evening.
Dec '24 •
Migrating from P1 to F64
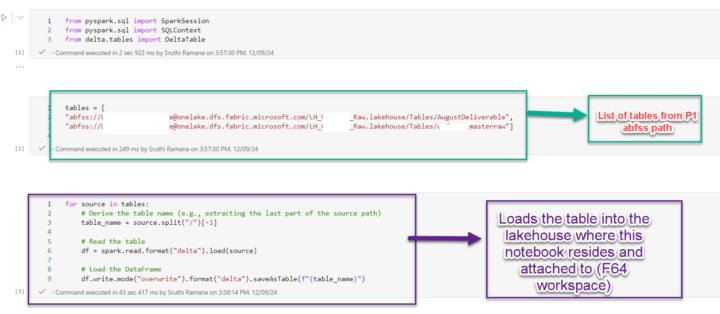
We upgraded our account from P1 to F64 and it enabled us with lot of new capabilites. Adding a blob storage container to LH etc. But moving data (lakehouse tables / sql endpoint) was not easy and was not just setting change (in workspace setting) below workaround worked like a charm and I wanted to share with community if it can help someone that will be a +1 for all of us. :)
0 likes • Dec '24
Hi Charles, We found we couldn’t connect to azure blob when we were in P1 , compared to F8/F64 which help in automating the process - like picking csv/excel files , load it in pipeline etc. also we are working in different Geo’s and have different capacities F8,F16 and F64. I am not aware we had that capability with P1. And also possible cost benefits .
Oct '24 •
Data pipeline Excel files
Hello everyone, I am trying to use a pipeline (Data Engineering) to load excel files that are stored in blob container and then eventually load as table in the Lakehouse. 1) I have the shortcut for the above files In Lakehouse in file section. 2) I have about 3 excel files with about 180 columns and 60k rows. The data gets loaded successfully but the column names are loaded as Prop_1,Prop_2 etc. I lose the column names but have all the data loaded. Another pipeline - So, I changed the excel files to csv (also removed the space in the column names just to be sure) and ran the pipeline. Though it fails but it did create the empty table with the same column names as in excel files unlike the other pipeline. Did anyone work on loading multiple excel or csv using pipeline? any insights on this will be helpful.

May '24 •
How to update column data type in data warehouse
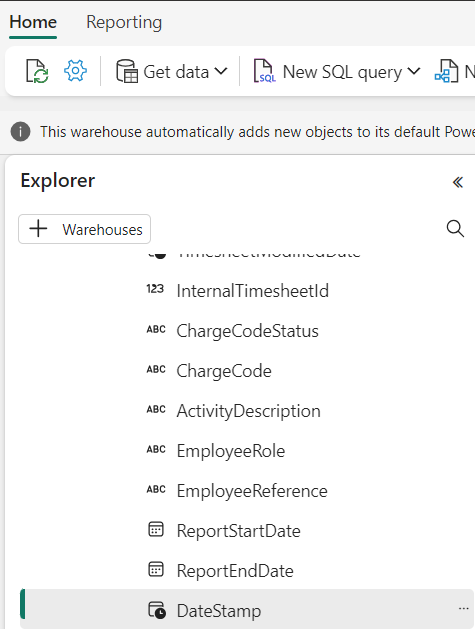
Hi, I have got this table in data warehouse and need to update the "DateStamp" column from datetime2 to date. I was trying to run alter table query however it doesnt support in Fabric, is there a better way to do this without dropping and recreating the whole table?
0 likes • Oct '24
@Will Needham Thank you for this workaround. But can I use it for lakehouse tables as well ? I uploaded a calendar table as csv and then loaded into lakehouse, but by default it picks all columns as text and not datetime2 or int. So if I need to alter the table what is the best possible option. I tried the sp_rename in sql endpoint as well as magic sql in notebook but both throw error.
1-7 of 7
