Activity
Mon
Wed
Fri
Sun
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Memberships
Free Skool Course
66.1k members • Free
Clief Notes
23.8k members • Free
App Founder OS
1.1k members • $19/month
WavyWorld
48.1k members • Free
Agency Rewired
2.2k members • Free
AI Rewired
393 members • $29/m
CloserX
921 members • Free
Data Alchemy
37.7k members • Free
Flipbytes Community (Closed)
2.1k members • Free
138 contributions to Clief Notes

7d •
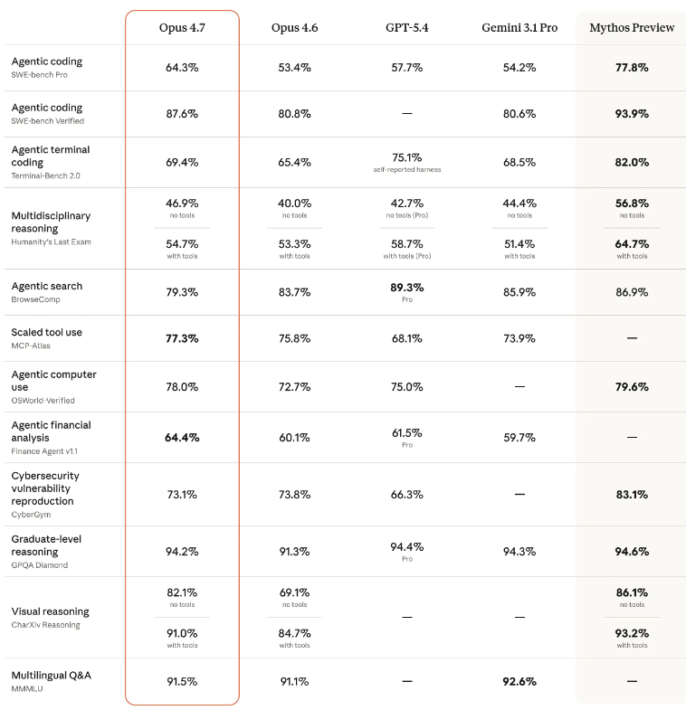
The best AI news this week, Opus 4.7 is here!
So opus 4.7 just dropped and it beats opus 4.6 on EVERY aspect except Agentic search and Cybersecurity. They also dropped the metrics for Mythos. It beats the other main stream models in most aspects, considering the general overview, not each and every use case and also it is in claude code for your information. It's available in the VS code extension, and you can update the claude terminal by just running 'claude update' in the terminal (not as a prompt in itself). Some major new UI changes and updates to claude's desktop app as well, I used co work today to free up an estimated of 20-30 GB on my desktop so that was fun.
0 likes • 24h
@David Vogel I've been seeing Codex a lot lately. Is OpenAI really going to make a comeback? or was this a one hit wonder
1 like • 23h
@Dillon Taitano I used up all my tokens that didn't even reach 70% in a 5 hour window with multiple projects at the same time previously, in about 1 hour or so with the new xhigh opus 4.7 with only 2 projects running at the same time. Sad times.
19d •
You finish claude usage? Use cave talk, save 75%.
Okay don't judge me on the title. It's actually what'll help you save up to 75% tokens while your using any Cloud LLM model. So as you can see in the screenshot below, there's this dev that made claude speak in "caveman" terms. Turns out that saves tons of credits for you. Tbh the more AI evolves, the more dumb and easier ways to save tokens arise, maybe soon enough the em dashes and 50 line answers would be eradicated by default? Anyways, here's the link to the post if you'd like to snoop around there: https://www.reddit.com/r/ClaudeAI/comments/1sble09/taught_claude_to_talk_like_a_caveman_to_use_75/

0 likes • 2d
@Antonio Mascarenhas Yessir!
0 likes • 2d
@Jerome Anasco Could you clarify?
3d •
Kimi 2.6 is out!
So there's a lot going on with kimi right now, from what I've looked at, for being completely open source it's quite amazing. The benchmarks look quite promising taking in the fact that it's completely open source. Specialized more towards the longer coding tasks and back end coding languages. A really interesting aspect is that (from their article): Kimi K2.6 successfully downloaded and deployed the Qwen3.5-0.8B model locally on a Mac. By implementing and optimizing model inference in Zig—a highly niche programming language—it demonstrated exceptional out-of-distribution generalization. Across 4,000+ tool calls, over 12 hours of continuous execution, and 14 iterations, Kimi K2.6 dramatically improved throughput from ~15 to ~193 tokens/sec, ultimately achieving speeds ~20% faster than LM Studio. The website design isn't that bad at all, but it feels like they were trained more on aesthetic PPT's than code. Anyways, tons more to explore, the link's here: https://www.kimi.com/blog/kimi-k2-6
0 likes • 3d
@Ivan Ivanov You're right, I even wrote about that in one of my previous posts, I'm always cautious about the benchmarks, but again, open source does have some more trust in my eyes.
1 like • 3d
@Elladan Elrondson Interesting take, I do feel like that's very much possible, as of now it's a race between consumer grade hardware vs cloud infrastructure. Will we be stuck with the "payphones" of this era or have our own "cell phones"?
6d •
Get unlimited claude usage for completely free.
You do need at least 1 claude subscription to access claude code in itself, regardless of which one. So how claude's usage works is that it saves all your transcripts and messages locally, that file was never a server side block. So you're basically resetting your usage manually from the log file that claude stores. Don't know how people figured it out. So you need to find your claude local folder and then delete everything except the first line, that's a header. So before you go ahead and do this, you will 100% get banned if you do this. Enjoy! 🤣 (This was for educational purposes only, don't come attacking me for the ragebait!)
1 like • 5d
@Ari Evergreen True true, I've never hit my weekly and only twice hit my session-ly limits so far.
1 like • 5d
@Ari Evergreen Yes Ma'am! It's because of people like us in Clief Notes that leads to Anthropic lowering usage rates and increasing prices 😭🙏
7d •
What sort of memory system should you use?
So, if you’re looking to set up a memory system but with all the new obsidian, graph, this and that sort of AI news, you just don’t know which one to, here’s what I recommend. I don't know your exact use case so I recommend copy pasting my message, putting it into claude and talking to it about your use case. So you have the obsidian stack, where the AI first looks for a topic, it doesn't exactly ask (query) any sort of external system. How it works is that the AI has a sort of index page, you know how our school text books have those main pages with chapters and page numbers? Something similar, but in this case, every "Chapter" leads to another chapter which is related to the main topic. So let's say you have a topic such as "How do I implement the apple branding guidelines", it would find that first, then it would see that there's a reference of another page, such as "How to implement a luxurious design with react", both relevant so far, now inside of the how to doc, it would refer to "How to save tokens while designing a website", now Opus could possibly think of saving tokens but by default with just the most simple prompt and topic you gave it, it would not go to that doc, it pulls the first 2 relevant documents and then understands that. If you're wondering how you even get those docs, you basically dump your notes, research papers, whatever you'd like to and then it would use AI to sort it out, 1 research paper can become 50-500 different documents, this is the Andrej Karpathy memory system. https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f The 2nd method would be through Vector, it's not always needed though. Going into Vector, it query's your database but with an unclear task. SQL would be: "find users where plan = paid" You know exactly what you need and need definitive results. Vector's more like: "find docs similar to this concept"
0 likes • 6d
@Mark Gubuan That is an amazing breakdown, I do vouch for this as well as that's what's mainly missing. There are a few flaws in every new project that come's out.
0 likes • 6d
@Qayyum Khan Exactly that's what everyone should be doing, not following the next new Openclaw with 50 security vulnerabilities
1-10 of 138

@shirsho-guha
Trying to keep up with the 50+ new open source AI frameworks daily!
AI Solutions Developer and Consultant.
Active 6h ago
Joined Mar 2, 2026
Dubai, UAE
Powered by