Activity
Mon
Wed
Fri
Sun
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
What is this?
Less
More
Memberships
Learn Microsoft Fabric
15.3k members • Free
5 contributions to Learn Microsoft Fabric

Apr '24 •
Automatically resume and suspend capacity
Hey all! I was searching how to automatically suspend and resume fabric capacities and leave it running only on week days in order to save money or to scale up wihout exceeding the budget. So, I found this tutorial from Chris and Kevin where they show step by step how to do it. Since it's really useful and I haven't seen this posted here yet I thought of sharing it with you. https://www.youtube.com/watch?v=OHw-RJPW9SQ This is the link for the article they are using: https://richmintzbi.wordpress.com/2023/11/23/microsoft-fabric-capicity-automation/ In the article there is also the code for automatically resizing the capacity which can also be very useful, if you know the time you'll need more compute you can schedule when to scale up and scale down after a period of time.

🚀
Apr '24 •
❗New to the community? INTRODUCE YOURSELF! 😊
👋 First things first - welcome to all the new joiners! 🤝 We have a bit of a tradition here for new joiners to introduce themselves just so everyone can say hello and learn about the amazing people (you!) that are regularly joining the community. It also helps me understand more about what you are looking to get out of the community (so I can make it a better experience for you!). 💬 So, don't be shy, we're a friendly bunch... feel free to say hello using the following questions as a guide: 1. Which part of the world are you signing in from? 2. What's your background (current role, industry, ambitions for the future)? 3. What attracted you to this community? 4. What excites you most about Fabric? 5. I'm really interested in learning more about _______ ? 6. Are you looking to get Fabric certified (DP-600)? Thank you for engaging and joining us on this exciting learning journey! 🙏 Will
2 likes • Apr '24
Hey @Bruno Silva ! It's good to see more brazilians around here! I'm from Rio too. Welcome!
Apr '24 •
Query a LH | DW outside the Fabric interface
Hi everyone! Is it possible to query a Fabric Lakehouse or DW using a python script outside Fabric? I have this script that must run only on this specific computer and it will need information from one of the tables in my lakehouse.
0 likes • Apr '24
@Will Needham Great, I'll try! Thanks!
2 likes • Apr '24
Hi @Santosh Pothnak. Yes, I managed to connect using interactive browser connection, but I had to fix the name of some variables, I'm attaching a working version of the code (just needs to replace the sql endpoint and database name). Azure CLI didn't work for me. Overall, it solves my problem for now, but it would be nice to see a smoothier way to do that, one that I wouldn't have to mannually authenticate in every run.
Mar '24 •
Choosing between two data pipeline designs
Hello everyone. I'd like to start by apologizing for the long text. If anyone manages to get to the end and has an opinion to share or find something that doesn't make any sence, I would be grateful and happy to discuss further 😊 Currently, I am working on building a data pipeline at the company where I work to meet their needs for reporting and analysis. I don't have much practical experience with data engineering yet, this is actually the first complex project I'm working with, and since it primarily involves Fabric, I thought of sharing it with you. What I have defined is that the data - ready for consumption - will be available in silver and gold layers in Fabric lakehouses. Where I am having difficulty deciding is at the initial part of the pipeline where I need to decide between 2 approaches that seem to make sense. This initial part includes an initial data validation by checking constraints and data types, handling SCD cases, and performing retroactive updates of some tables (e.g., stock prices need to be adjusted backwards according to market events). I've attached a diagram that I believe helps visualizing. Basically, there are 3 different data sources, with (i) and (ii) being accessed via API and (iii) consisting mostly of manually filled Excel tables with registration data that will later be used to build dimensions. In option A, an initial ETL process would be done for a PostgreSQL database. The main idea here is to have a very direct way to validate the data through constraints and typing. As for SCD cases and retroactive updates, it seems feasible to perform here as well. In option B, the data would be loaded into a Fabric bronze lakehouse and all this initial stage would need to happen within Fabric. At first glance, this approach seems simpler and less costly because it does not require an additional platform to place the data, nor an additional copy of the data. My concern is whether it will also be simple to perform the tasks I mentioned directly in Fabric.
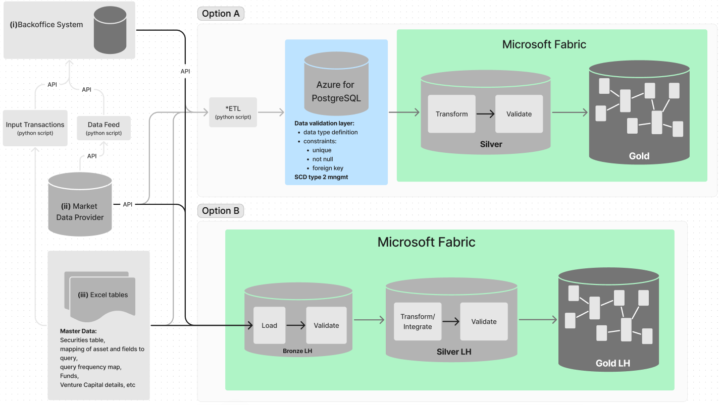
0 likes • Mar '24
Hi @Will Needham Thank you for sharing your SQL Bits presentation beforehand. It definitely will be useful! I really like the architecture for data validation that you suggest and how you map and walk through what could go wrong in each step of the pipeline. I hadn't thought of validating the files inside fabric before turning them into delta tables. Looking forward to your videos! Also I took a look at the SQL Bits agenda and got excited that it is going to have a lot of content about microsoft fabric! 1) A few weeks ago I watched your video on GX and did some tests in Fabric by following your steps. Has anything changed since then or this video is still the best approach for using GX inside Fabric? I found the setup a little difficult but was able to make it work. Do you have any recommendations for learning more about GX? 2) About option A (with a postgres db at the beginning of the pipeline). I'm already convinced, but I still need to convince my (non technical) superior that this approach isn't ideal. The cost perspective is one argument, but I think it's not enough since our data volume is relatively small (all tables together should be around 20M rows as of today) although it might become relevant in the near future. What crossed your mind when you said it comes with constraints? For me it seems to create an additional complexity, for example I think I would need to worry about optimizations that wouldn't be necessary in option B.
🚀
Feb '24 •
Data Quality discussion
Hi all! I would love to get your views and experiences with data quality and data validation in data analytics/ viz/ engineering. It would be great to hear your experiences on any of the following: - Is this an area you've worked in before? - If so, what were you doing and - how did you approach it? - Any particular tools or frameworks you used? - What were the outcomes for you and your company/ client? The reason I'm asking is that for me it's probably the most important part of any data strategy, and one that is often neglected. Fabric makes it simpler to implement data quality/ validation rules in nearly every part of the data analytics workflow/ system. If there's any interest, I'll look to create a series of videos on how to think about data quality and validation within Fabric, and how to actually implement measures that grow trust in your analytics systems, visualizations and insights.

0 likes • Feb '24
@Will Needham In the project I'm currently working on I'm going to use the medallion architecture approach with validation steps between each layer since we're really concerned about data quality here. I watched you video on GX and it's really helping me out. Didn't know about GX before. I followed the steps in the video and adapted it to a slightly more complicated scenario: a data pipeline to copy data into 3 tables of a bronze LH and a validation step using GX to promote them to a silver LH while storing data about the validation results for each table. In the process a few questions came to mind and I was wondering if someone might want to share some insight/opinion/experience. 1. Is there a best practice to when to create GX checkpoints? I. Is it better to create a checkpoint for each layer, for example a checkpoint validating all tables in bronze? II. My intuition says it would make sense to create them based on update frequencies of the tables III. Since I might want the pipeline to run when a file is updated it might also make sense to create one for each table of the layer. 2. Following up from the previous question, if I understood correctly. I. I probably will end up with quite a few notebooks of validation for each layer. So maybe there is a way in fabric to keep all the validation logic organized in one notebook and in the data pipeline tell which part of the validation should be run to validate the corresponding table II. After configuring GX I'll have many names created for different expectation suites, assets, checkpoints... and I'll have to use these names across notebooks. I was thinking there might be a way to better organize this names using parameters
1-5 of 5

@sergio-barbosa-5167
👋 Hi, I'm a data engineer enthusiast, looking forward to learning more about Microsoft fabric.
Active 50d ago
Joined Jan 20, 2024
Powered by