Activity
Mon
Wed
Fri
Sun
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Juanes
Memberships
Voice AI Bootcamp 🎙️🤖
8.9k members • Free
Road to Partner | Nico Seoane
16.2k members • Free
Brendan's AI Community
24.1k members • Free
Oscar's Community
7.4k members • $39/m
Skoolers
196.1k members • Free
AI Automation Agency Hub
310.7k members • Free
Adonis Gang
183.3k members • Free
Heroes Legacy™
26.2k members • Free
Assistable.ai
3.4k members • Free
76 contributions to Assistable.ai

Mar 5 •
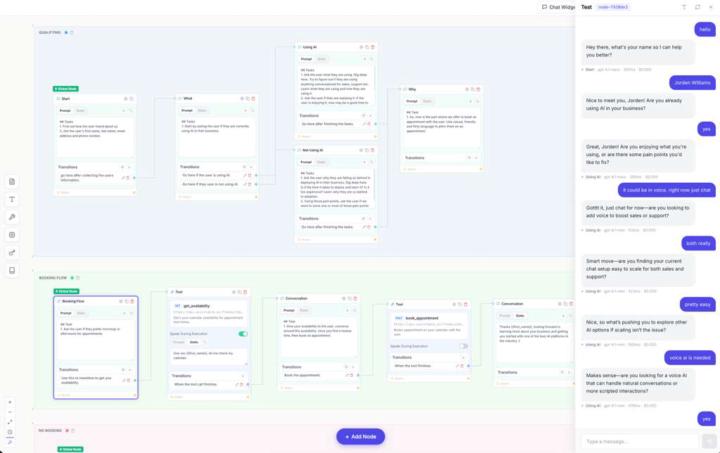
flowbuilder production
long dev cycle but we've rebuild the platform from the ground up along compliance audits. its a lot. but, something we have put into product for managed clients is the production version of flow builder for voice and chat. I know a lot of people have wanted this for some time, we have to.

0 likes • Mar 6
@Bernie White So we’re HIPPA compilant now?
Dec '25 •
Updates on HIPAA
Support said this would be available in November. Now it’s December. Is there a specific date when this will be fully compliant? Is the HIPPA from GHL different from the HIPPA in assistable?
0 likes • Dec '25
@Mike Copeland
Dec '25 •
UI in phone numbers not working
It makes it so difficult to check which assistant it is assigned to when you have 20 or 30+ numbers and the UI hasn't been working for a lot of time now, can you solve this error? @Assistable Ai
0
0

Dec '25 •
SIP trunking GHL numbers
Is this possible? Would be better if I don't have to switch to telenyx or twilio for this client
Nov '25 •
Feature Release: Chat History Token Optimization
So, when using your own openai key (and even us as a business), you notice with agent stack (tools, prompt, convo history, RAG, etc) it starts to stack up quick - especially if you have a really involved process. We implemented a token optimization model before our chat completions to ensure you get the cost savings and ill share some data at the end :) So, we are now truncating and summarizing conversation history - we noticed there are large chat completeions coming through with 300-400+ message histories. This becomes expensive overtime if its a lead you've been working or following up with for a while engaging in conversation, so we are reducing that number and summarizing the history to ensure the intelligence stays the same but the token consumption goes way down (98% decrease on larger runs) Another thing we are doing is truncating large tool call outputs within the window that are not relevant to the current task - meaning, if there are tool calls with large outputs (like get_availability), if they are not relevant to the current task at hand, we truncate the response to show the agent that the action happened but the context is shorter. This saw a huge reduction in token consuption as well (96% decrease on larger runs) Here is the before and after, this is the same exact conversation history, assistant ID, tools, custom fields, knowledge base, etc - but see the speed and cost difference and the output was the exact same message: Differences: - 35 seconds faster - 95.95% cheaper ---- Before: "error_type": null, "usage_cost": { "notes": null, "tokens": { "output": 211, "input_total": 175948, "input_cached": 0, "input_noncached": 175948 }, "total_cost": 0.353584, "model_normalized": "gpt-4o", "models_encountered": [ "gpt-4o" ], "price_used_per_million": { "input": 2.5, "cached_input": 1.25, "output": 10 }, "error_message": null, "run_time_seconds": 32.692, "returned_an_error": false, After: "run_time_seconds": 2.618, "returned_an_error": false,
0 likes • Dec '25
@Jorden Williams Volume is high, but 58 Million tokens in input is crazy, I have like 400 conversations daily
1 like • Dec '25
@Brandon Duncan No, every conversation is like 10-15 messages and that’s it, and I have a limit for 20 messages in each conversation
1-10 of 76
