Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
Data Alchemy
38k members • Free
9 contributions to Data Alchemy

Feb 6 •
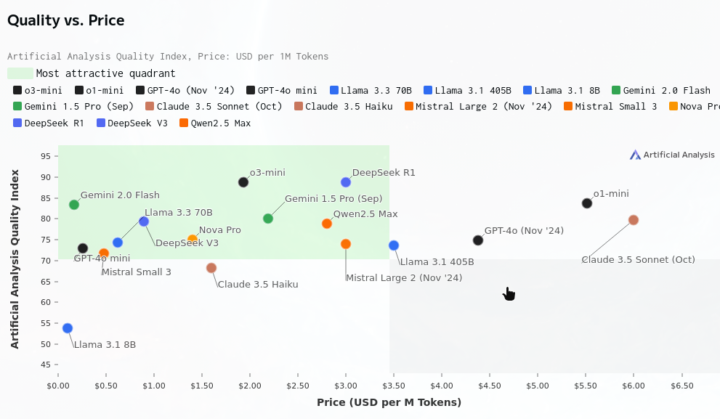
Forget DeepSeek - Gemini 2.0 Flash is a wrecking ball to LLM pricing
It's like yesterday we were freaking out over the leap forward we saw from DeepSeek R1 - a model developed with relatively few resources and an excellent cost/quality ratio. Its cost-effective performance reportedly caused a panic within companies like Meta. Google's release of Gemini 2.0 Flash to the public could be an even greater disruption. Its design as a "workhorse model" for high-volume tasks, its multimodal reasoning capabilities, its substantial 1M token context window, and, most importantly, its pricing - make it an attractive choice for any LLM application that requires quality and scalability. And the cost-optimized Gemini 2.0 Flash-Lite is somehow even cheaper. I hear industry leaders like Sam Altman give lip service to democratizing AI, but I think this is what that actually looks like. It's great to see real competition heating up in the foundational LLM models. With any luck, LLM models is not going to be a winner-take-all business.

0 likes • Feb 10
I'm also starting to use Gemini more and more on my phone. Features like app access are quite interesting and useful.
Feb 7 •
Deepseek true training cost
An interesting read about the actual training cost of Deepseek and the hardware they have - 50.000 GPUs, 10.000 of which are H100s. https://semianalysis.com/2025/01/31/deepseek-debates/
1 like • Feb 7
@Japmandeep Ahluwalia And it's pretty far away from what was claimed ($5.5m and 2.000 GPUs), which then caused a huge panic on the market.

Feb 1 •
Python AI Systems
Hi everyone, I am interested to know how all the data freelancers out there are implementing AI systems for their clients, and the advantages/disadvantages of the different options. I have experience working in Python for data science purposes and have recently been playing around with LLMs, however I lack the developer experience to know how AI systems would be productionized.
4 likes • Feb 1
I am also currently looking into how to build scalable backends for LLM and search usage. Curios about some real world experience.

Feb 1 •
Chat with your SQL database 📊. Accurate Text-to-SQL Generation via LLMs using RAG
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality. https://github.com/vanna-ai/vanna
1 like • Feb 1
Sounds interesting 😁

Jan 22 •
Deepseek R1 Released
An open source model that compares to Open AI's o1 reasoning model on several benchmarks. The research paper: DeepSeek_R1.pdf. https://github.com/deepseek-ai/DeepSeek-R1 """ We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models. """
1 like • Jan 28
This is fascinating on so many levels and it proves once again that constraints drive creativity and innovation.
1 like • Jan 28
This is a really interesting write up about how they managed to train this model on that kind of a budget and the lengths they went through, e.g. low level optimizations of cross-chip communication: https://stratechery.com/2025/deepseek-faq/
1-9 of 9

Active 213d ago
Joined Jan 12, 2025
Powered by