Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
Data Alchemy
38k members • Free
3 contributions to Data Alchemy

Feb 6 •
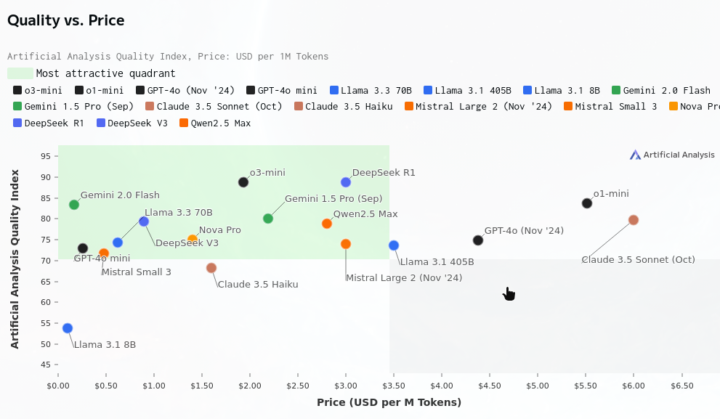
Forget DeepSeek - Gemini 2.0 Flash is a wrecking ball to LLM pricing
It's like yesterday we were freaking out over the leap forward we saw from DeepSeek R1 - a model developed with relatively few resources and an excellent cost/quality ratio. Its cost-effective performance reportedly caused a panic within companies like Meta. Google's release of Gemini 2.0 Flash to the public could be an even greater disruption. Its design as a "workhorse model" for high-volume tasks, its multimodal reasoning capabilities, its substantial 1M token context window, and, most importantly, its pricing - make it an attractive choice for any LLM application that requires quality and scalability. And the cost-optimized Gemini 2.0 Flash-Lite is somehow even cheaper. I hear industry leaders like Sam Altman give lip service to democratizing AI, but I think this is what that actually looks like. It's great to see real competition heating up in the foundational LLM models. With any luck, LLM models is not going to be a winner-take-all business.

Feb 1 •
Open AI Releases o3 mini
https://openai.com/index/openai-o3-mini/ We’re releasing OpenAI o3-mini, the newest, most cost-efficient model in our reasoning series, available in both ChatGPT and the API today. Previewed in December 2024, this powerful and fast model advances the boundaries of what small models can achieve, delivering exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.
3 likes • Feb 1
Very interested to try out o3-mini in my agents moving forward. The o1-mini model fails to match my structured outputs more often than I'd like.
1 like • Feb 4
@Anaxareian Aia OpenAPI specifications in JSON. It's not that surprising that an LLM can fail to match a structure so complex. I haven't taken proper statistics on the failure rate, but from my anecdotal testing it's in the ballpark of 10-25% for o1-mini. Claude consistently fails. I haven't tested o3-mini on the task yet. There are a few clean-up functions I apply to the output that bring the success rate up quite a bit. The most common mistake is o1-mini omitting closing brackets at the end of the output.

Jan 31 •
New Arms Race?
I'm curious about peoples' thoughts on the recent news of not only Deepseek, but also Alibaba's new model: https://www.reuters.com/technology/artificial-intelligence/alibaba-releases-ai-model-it-claims-surpasses-deepseek-v3-2025-01-29/ it seems everyone is racing to update their AI models. Is this a good thing? Do you think companies developing AI could be forsaking moral and ethical decisions in order to create the latest/greatest tool? For some perspective on moral/ethical issues please see: https://annenberg.usc.edu/research/center-public-relations/usc-annenberg-relevance-report/ethical-dilemmas-ai
2 likes • Feb 1
> Do you think companies developing AI could be forsaking moral and ethical decisions in order to create the latest/greatest tool? 100% - but it's just a continuation of the status quo. All the companies would have to simultaneously abide by the same rules - which is effectively impossible. The companies span multiple countries and have a variety of incentives. There's no stopping it. The only company giving serious lip service to ethics is Anthropic - and I don't know how much they actually practice what they preach. For the most part, the ethical concerns around AI aren't any different than other disruptive tech. If history is any guide, ethics won't play any role.
1-3 of 3

Active 117d ago
Joined Oct 8, 2024
Powered by