Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
1of10: The Youtube Blueprint
1.7k members • Free
AI Automation Society
387.1k members • Free
Clief Notes
35.5k members • Free
Ecom Consulting Accelerator
533 members • Free
33 contributions to Clief Notes

4h •
I read Jake's paper and built this
Built something that addresses a gap named in section 6.2 of the ICM paper. https://arxiv.org/abs/2603.16021 Van Clief and McDermott call it "observability without traceability." ICM tells you which files a stage was given. It does not tell you which passage in the output came from which file. If something is wrong, you know what was in the room but you have to read everything and work backward. sem_debug is my attempt at that traceability layer. Point it at a stage output and the declared inputs. It maps every passage back to its source and flags anything with no detectable origin. That unattributed text is where the agent went outside the declared context. I wrote it about a week ago and sat on it because I wasn't sure if I was being a dick. Jake may have already solved this or had something in the works. Figured sharing it was better than sitting on it. Runs inside the ICM workspace structure. Validated on a real pipeline stage. Made the ICM workflow build the tool, because why not. github.com/WBChain3/sem_debug Curious if anyone has experienced the traceability problem, or if Jake has already addressed it somewhere I missed.
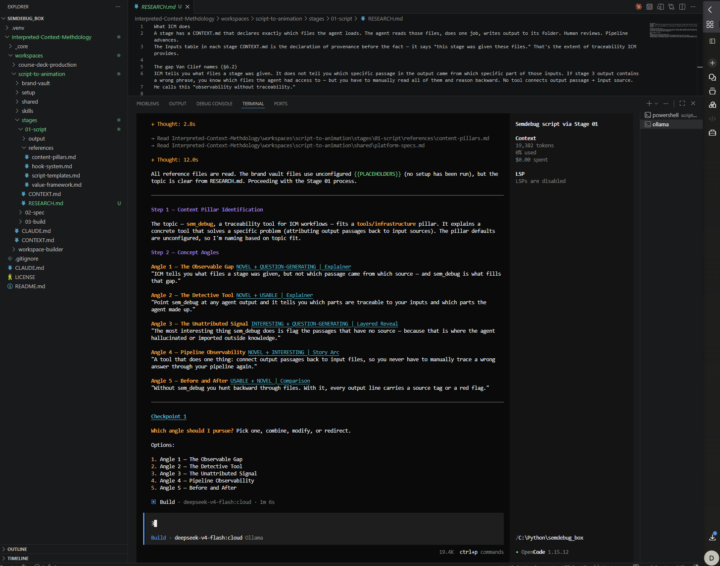

1 like • 3h
Going to look at this. Seems to directly address the gap Jake names in 6.2 "ICM currently provides observability but not traceability."
2d •
Workflow vs. Reasoning System: what I've been figuring out (learner perspective)
Most of what I see in here is about automating tasks. Building workflows, connecting tools, making things run faster. I've been learning all of it and it's clicking.But I kept hitting a wall that I couldn't name for a while. I was using an LLM app as my operating system. Not just for tasks but for decision-making, project navigation, thinking through problems, tracking where things stood across different work. And it kept falling apart. Sessions ended, context disappeared, drift compounded quietly. By the time something felt wrong, I was already deep in the wrong direction. I lost real work to it. The problem wasn't the tool. The problem was the category error. A workflow system automates a process you already understand. You know the steps, you know the inputs and outputs, you want to run it reliably and faster. It's execution. It shines when the process is stable. A reasoning system is what you need before that. It's the thinking partner that helps you figure out what the process should even be, especially when you're building something from scratch and the process doesn't exist yet. You can't automate your way to a decision you haven't made yet. I was treating a reasoning tool like a workflow system. No persistent state, no routing logic, no structure, just conversation. It can't hold a project together. That's not what it's for. So I've been building what I'm calling CoworkOS, based on ICM principles, a folder architecture that gives Claude a stable structure to operate within across sessions. Routing tables, layered context files, memory that persists. The idea is: before you build workflows inside your projects, you might need an operating layer that actually runs the reasoning coherently. I don't know if this is the right approach yet. Still figuring it out. But the distinction feels important, especially if you're newer to this and trying to figure out where to start. Workflows are powerful once you know what you're automating. The reasoning layer is what gets you there.
0 likes • 3h
@Aleksandr Samoilov The most detailed implementation I've seen described in this thread. The contract structure is something I don't have yet. I have context files that define scope and routing, but no explicit done-criteria at the step level. That gap is real. The line that landed: "The reasoning layer defines the structure, contracts, and validation rules. The execution layer just follows them." That's the separation I was trying to name in the original post. You've operationalized it further than I have. One thing I'm trying to understand: in your Goal → Module → Step → Phase hierarchy, where does reasoning end and execution begin? Is the reasoning layer the Goal and Module levels, with execution taking over at Steps and Phases? Or does reasoning run throughout and the levels are purely about scope?
1 like • 3h
@Max Walker Yes to having experienced the traceability problem. "You know what was in the room but you have to read everything and work backward" is exactly what debugging drift looks like from where I sit. The structural layer tells you what was declared. It doesn't tell you what was actually used. "Observability without traceability" is new vocabulary for something I've been hitting without being able to name it that precisely. Going to look at sem_debug. Glad you posted it.
21h •
Knowledge extraction pipeline for YouTube videos. Use this on Jake's videos!!!
You watch a lot of content in this space. Demos, walkthroughs, systems builds, production case studies. Some of it is genuinely valuable. Most of it evaporates. A summary gives you a shorter version of what was said. What you want to know is: is there anything here worth keeping, what's the mechanism behind it, and what would you build differently knowing it? What this does: YouTube URL in. Claude extracts 3-7 discrete claims worth keeping. Each one gets: - Concept - the core assertion - Mechanism - the causal explanation (the most important field) - So what - what you'd build or decide differently - Open questions - what this raises but doesn't answer Appended to a local markdown log you own. Real example, from Curtis Hays's Collideascope OS walkthrough: Concept: ICM deploys fast only when the doctrine layer is already documented. The folder structure is the last step, not the first. Mechanism: Curtis had 8 months of prior work before touching the ICM - documented beliefs, brand voice, organizational why/how/what, all in markdown. He brought that corpus in and said "organize it using this structure." The system came together quickly because the content existed. Without pre-existing doctrine, the ICM produces mechanics without a belief layer. So what: Before building the folder structure, ask: is the doctrine layer written down? Cloning a blueprint without existing beliefs produces a technically correct but contextually empty system. That's not in any summary. That comes from extraction. How repo works: Primary mode uses Claude Code with your existing subscription. No API key needed.Three components, each with one job: fetch_ transcript.py gets the transcript, prompts/extract_default.md tells Claude what to look for, CONTEXT.md tells Claude Code how to run the workflow. The prompt file is the thing to edit. The scripts are plumbing.
1 like • 19h
@Greg Prince absolutely, and that's the beauty and chaos of it. we need a way of defining and extracting what's relevant to us specifically, even if its a problem in that moment., across interest domains.
1 like • 18h
@Ruben Aguirre if you don't have the specific experience, this is literally everything you build your foundation from. worth a review or two! The setup isn't perfect but I'm sure this community will build from it!

22h •
Why opus 4.8 thrives in and ICM workspace
I ran Opus 4.8 at max thinking effort this week. The finding isn't "it's smarter." The finding is where that thinking goes, and what it needs before it pays off. Here's what nobody tells you about high-effort reasoning. It only thrives when there's something to reason over. Drop a max-thinking model into an empty context and you get a slow, confident guess. Drop it into a workspace you've actually built, the briefs, the memory, the prior decisions, the evidence, and it does something different. It digs. Three things I noticed. 1. Context is the unlock, not the model. The jump from 4.7 to 4.8 wasn't really "smarter weights." It was better use of the room you give it. The intelligence isn't in the model. It's in the environment you set up before you ask the question. 2. The slow part is the feature. Thinking times went up a lot. That felt like a cost until I read what it was doing. It wasn't stalling. It was hunting through the context for evidence before answering. Judge the reasoning, not the clock. The pause is the work. 3. It reasons evidence-first. This is the real shift. 4.8 goes looking for proof in your context before it commits to an answer. 4.7 tended to answer first, then justify. Working backwards from evidence instead of forwards from a guess changes the quality of everything downstream. It's the best reasoning I've seen from any model, and it only shows up when the evidence is there to find. So the lesson isn't "turn thinking up." Effort and context are a pair. Max effort on a thin context is an expensive guess. Max effort on a built-out workspace is a researcher. Build the room before you ask the question. Full deep-dive available at: https://www.aris-space.com/documents/workspaces/max-thinking-empty-room ASIDE —> After @Ruben Aguirre 's great post earlier today. If you highlight over any AI terminology, it will give you a plain English explanation of what that is. And there's also a glossary at the bottom to help. <3
1 like • 20h
Right back to the foundations Jake taught us. The context system you build is the right and durable abstraction layer to work on. The model is interchangeable as designed.

1d •
DO RIGHT OR GO BYE BYE!!
So it seems we have a bad actor, I didnt know that Jake was another person?? I am highlighting this because, if we catch you, we will report you to Skool, this is considered fraud when impersonating someone else, on top of charging people for our content we work hard here developing in the community. You have no right to do that, and its a shame someone is doing this. DO RIGHT OR GO BYE BYE. The choice is yours. Until next next time Friends. Aaron
1 like • 1d
did this guy seriously copy paste the whole course
1-10 of 33

@daniel-terry-8872
The vision = Macroeconomic AI analysis across major assets. MacroMachine.
Let's connect on LinkedIn!
Online now
Joined May 13, 2026
Palm Harbor, FL 34685, USA
Powered by