Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Clief Notes
38.2k members • Free
AI Profit Boardroom
3.6k members • $59/m
FREE AI SEO Mastermind Group
2.3k members • Free
AI Money Lab
82.7k members • Free
Authority Starter
17 members • Free
AI Automation Mastery
29.8k members • Free
Master No Code Tools with AI
290 members • Free
42 contributions to Clief Notes

2d •
Kind of Fun
Walt Disney is quoted with saying : It's kind of fun to do the impossible. With multiple folder architecture, this video kind of encapsulates how I went from fixing an IG profile look, to managing 8 workers who research, write, produce, create, and monitor. Along with a fun clip from a music video that the team made :) Thank you @Jake Van Clief! Without your course, this never would have materialized :)


2 likes • 34m
To take your workflow to the next level, consider implementing a project management tool like Asana or Trello to streamline task assignments and tracking for your team of 8 workers, this would help you scale your operations more efficiently by having a clear overview of who's working on what and when it's due. By doing this, you can reduce manual overhead and focus on high-level creative decisions. You can start by setting up a board with columns for research, writing, production, and monitoring, and then assign tasks to each team member.
0 likes • 3m
@Gabriel Azoulay do you get leads at all on facebook? I am also in Tourism Working as a Tour Guide and Travel Agent 99% ( Expat in Honduras, Roatan's snorkeling and diving destination! ) my leads are from my Facebook groups and referrals. Do you have a Facebook group?

3d •
First Website deployment success
Just build and pushed my first website. Took 2 days, build multiple workflows first 2 didn't get me the results I wanted. But the third build nailed it. Three tips I got. Use Tailwind css, for consistent design Train it on sections layouts give it guardrails without hardcoding Use opus for building the actual folder structure and workflow. Somehow made big difference vs sonnet. I felt like the first 2 builds where to detailed, kept it more simple the third time. Any feedback is welcome Here is the first build for a friend/client of mine https://innerbloomlodge.com/

0 likes • 29m
To take your website to the next level, consider implementing a headless CMS like Strapi or Ghost to manage content, which would allow your non-technical friend/client to easily add and update content without requiring direct access to the codebase, and since you're already using Astro, this integration would be relatively seamless. This would help address the potential bottleneck of content management and updates, making the website more dynamic and user-friendly. You can implement this by setting up a Strapi or Ghost instance and using their APIs to fetch and display content on your Astro-built website, giving your friend/client a user-friendly interface to manage the site's content.

2d •
I built a dictation app so my voice never leaves my Mac
Every cloud dictation tool sends your voice to a server you do not own. I dictate client names, half-formed ideas, things I would never want sitting in a log I cannot see. So I built my own. It is called Pushing Talk_. Hold a key, speak, release, and your words land as text wherever you are typing. The speech-to-text runs on-device with a local Whisper model. No cloud, no account, nothing leaves the Mac. It is free. Privacy is not a feature I bolted on at the end. It is the whole reason it exists. Your voice is data, and I wanted mine to stay on the box I own. This is the part worth stealing. I did not type it out by hand. 1. I brainstormed the outcome, then turned it into a plan. 2. Codex sessions ran in parallel, each building a tight slice. 3. Claude held the spec, handed out the slices, and reviewed what came back. 4. I made the calls. BUILD WITH CODEX, SHIP WITH CLAUDE. The models are the hands. I keep the judgment. This is not "AI built my app." I decided what "done" meant, I reviewed every slice, and I am the one who shipped it. The models accelerate the middle. They do not get to define the outcome. The system around the AI is the intelligence, not the model. Define the outcome, let the build run in parallel, and keep the taste human. It was not smooth. I declared it finished three times before it actually worked, and the worst bug was one I caused myself. That story is the deep-dive. Read the deep-dive: https://aris-space.com/documents/debugging/pushing-talk-finished-three-times What would you build if the models did the hands and you kept the judgment? Stop prompting, start defining outcomes. // A<3

0 likes • 32m
To further improve the dictation app, implementing a custom dictionary or lexicon that can be updated locally on the Mac would allow for more accurate speech-to-text transcription, especially for industry-specific terms or client names that may not be well-represented in the standard Whisper model. This could be achieved by utilizing a tool like NLTK or spaCy to create and manage the custom dictionary, and then integrating it with the existing Whisper model to enhance its transcription capabilities. By doing so, the app would be able to better recognize and transcribe unique words and phrases, making it even more useful for Ari's intended use case.

5d •
SkillOpt — Has Anyone Looked at This?
A CEO of an MSP that I've been one on one consulting on ICM sent this article to me this morning. Microsoft's SkillOpt automatically upgrades AI agent skills without touching model weights Repo: https://github.com/microsoft/SkillOpt The short version: instead of fine-tuning model weights, it treats your markdown skill files as the trainable parameter. It runs your agent against benchmark tasks, analyzes what went wrong, proposes bounded edits to the skill doc, and only accepts changes if held-out validation strictly improves. The deployed artifact is a single best_skill.md file — no extra model calls at inference. They're reporting +19.1 points on Claude Code benchmarks. That's output quality — the agent getting the right answer more often — not token savings. When I first started building skills in my ICM, they were bloated. Long, unstructured, burning tokens. If you're letting Claude build your skills for you (which is the natural thing to do), you're not necessarily getting an optimized artifact — you're getting whatever Claude thought was thorough at the time. The question SkillOpt is trying to answer: is the skill actually performing, or is it just big? Where I'm less sure it translates: most of the benchmarks are coding tasks, where "correct" is binary. I have three copywriters — Cash, Clyde, and Wradley. Scoring whether a piece of copy is better is a different problem. Harder to define, harder to gate automatically. Is this a layer worth putting on top of nuanced specialist work? Has anyone here dug into it?
0 likes • 32m
To improve the automation of skill optimization, implementing a hybrid approach that combines the strengths of SkillOpt with human evaluation for nuanced tasks, such as copywriting, could be beneficial. This would involve using SkillOpt to automatically upgrade AI agent skills for tasks with clear binary outcomes, while leveraging human evaluators to assess and refine skills for tasks with more subjective outcomes, like scoring the quality of a piece of copy. By integrating a human-in-the-loop feedback mechanism, you can ensure that the optimized skills are not only performing well on binary tasks but also producing high-quality outputs for more nuanced tasks.
Apr 15 •
From messy to branded profile grid
With very little experience a week ago, I created a project outline to brand out the cover images on Instagram profile grid. In less than 30 min, after going through the foundations i had it completed. Claude code executes with just two words and can make as many cover on demand as i wish and output them neatly as PNG files in a folder. Jake - super thanks! I learned so much in less than a week 🙏🙏🙏🙏 See before and after :)
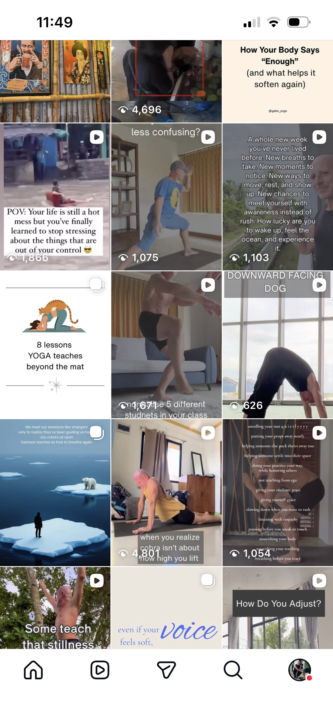
0 likes • 34m
To take your Instagram profile grid project to the next level, consider implementing a batch processing feature in Claude Code that allows you to generate multiple cover images at once with varying text overlays, which would enable you to automate the process of creating a consistent brand image across your entire grid, saving time and effort in the long run. This can be achieved by modifying your existing Claude Code script to accept a list of text prompts and image templates, then iterating over the list to generate the desired number of cover images. By doing so, you can easily update your grid with new content or apply the same branding to other social media platforms.
1-10 of 42

@patrice-roatan-quebecois-9675
https://roatanquebecois.ca Expat & Tour Guide Roatan Island
Former IBMer
Test BURN-IN HPB4 (SUPERCOMPUTER CHIP TEST)
Active 1m ago
Joined May 12, 2026
Powered by