Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
Learn Microsoft Fabric
14.3k members • Free
18 contributions to Learn Microsoft Fabric

May '24 •
Removing duplicates from the SQL-endpoint of a Lakehouse
In the latest video (Transforming data | PySpark, T-SQL & Dataflows in Microsoft Fabric) @ 8.57 it says that after deduplication of the revenue data set, the results can be saved into another table or another downstream activity. I know the sql-endpoint of a lakehouse is "read" only. So, how would I save the results of a deduplication query to another file in the Lakehouse. Even tried to a DW but the command is always rejected. -- deduplication CREATE TABLE [LH_BRONZE].[dbo].[dedup_revenue] AS ( SELECT [Dealer_ID] ,[Date_ID] ,max([Revenue]) 'Revenue' FROM [LH_BRONZE].[dbo].[revenue] GROUP BY [Dealer_ID],[Date_ID] ) This command is rejected, says "CREATE TABLE AS SELECT command is not supported"
May '24 •
Can't access Applied Skills Credentialing
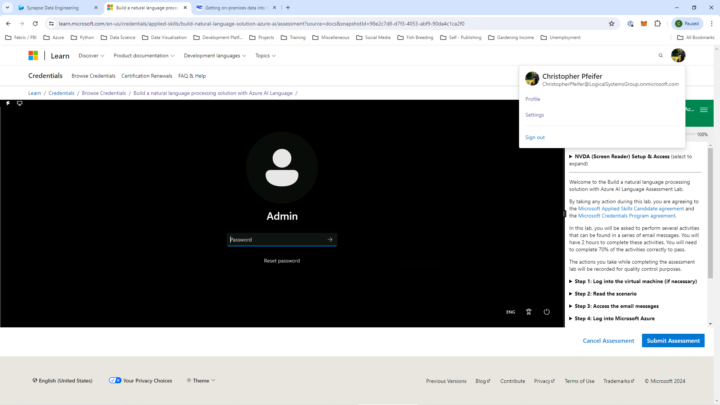
I'm am trying to take the assessment for one of Microsoft's Applied Skills Credentialing topics; however, it asks me for some type of "Admin" password. It seems to be trying to set up some type of a sandbox. I am the Global Administrator for my 365 account with Power BI Pro, Azure, and Fabric trial licenses. I have only a single login for everything. The attached screen shots show I am correctly linked to my account, second screen shot show that it won't accept my Global Admin password. Does anybody know what password it is looking for here?

Apr '24 •
Unexpected error dispatching create semantic model to portal ms fabric lakehouse
Hi All, I'm testing one of leakhouses for one of my exsisting PBI reports and workspace and when I trying to create a new semantic model I have below error: unexpected error dispatching create semantic model to portal ms fabric lakehouse There is no explanation in MS Community web page, I can modify default semantic model in the warehouse but this error is limiting my actions. Do you have any solutions to it? :)
2 likes • Apr '24
This issues seems to be fixed as of 4/29/24. I also was having this problem, left it alone for a couple of weeks and now I can create custom semantic models again, as before this situation showed up.

🚀
Mar '24 •
Making progress with Fabric? SHARE YOUR WINS!
What have you been working on this week in Fabric? I'd LOVE to hear more about what you're building, or what you're learning. So please share you Fabric WINS below (no matter how small)!! Maybe you built your first data pipeline? Or you wrote a Python notebook to transform some datasets? Or you built a Direct Lake semantic model? Or you did some learning modules? What are you currently learning? Looking forward to hearing what you're working on and celebrating your successes!
1 like • Apr '24
I am currently building an end-to-end project to load all of my Crypto trading info into Fabric. This includes my trading activity for the past two years from the exchange I use as well as my Grid-Bot profit history. This project will include Power BI reports, Real-Time streaming of available streaming data from many Crypto sources, as well as some Data Science models for predicting. To get some good practice in anticipation of taking the free certification exam I earned, I am duplicating the ELT function is all the different was possible (Dataflow Gen2, Data Pipelines, and Spark Notebooks).
0 likes • Apr '24
Sorry for the late response, been out-of-town. These past two weeks I have put that project on hold in order to study/practice for the DP-600 exam. Next week I am going to start building out the Power-BI report that will be the end point of this project. When I get far enough to be interesting I will publish the report to a public end-point and share the link with you. I can also share all of the source stuff also in a few weeks.
🚀
Apr '24 •
DP-600 Prep: Version control (Git) and deployment solutions
Hey folks, happy Friday! I just released video 4 in the 12-part DP-600 series. This time we focus on the analytics development lifecycle, so things like version control, depoyment pipelines and some other fun stuff. I hope you find the video useful in preparing for the exam. Let me know your thoughts! If you found it helpful, please do click through to YouTube and leave a comment there, as it helps with the algorithm (apparently 😂)
1 like • Apr '24
Question: It seems that when using the git integration for a Fabric workspace the workspace folder hierarchy was not preserved in DevOps, all items from all folders are in a single list. Any way to preserved the Fabric workspace folder hierarchy in DevOps?
1-10 of 18

@christopher-pfeifer-2356
Retired old-school software engineer from the 70s thru 90s. Specializing in mainframe database engineering. Back in the saddle after 12 years retired.
Active 577d ago
Joined Mar 4, 2024
Waupun, WI, USA
Powered by