Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Constellations
67 members • Free
The AI Group
12 members • $3/month
WavyWorld
48.6k members • Free
Clief Notes
28.9k members • Free
47 contributions to Clief Notes

👑
⭐
2h •
🧪 New benchmark out
New benchmark out of Meta FAIR, Stanford, and Harvard called ProgramBench. The setup: you get a compiled executable plus its docs. Source code stripped. Rebuild the program from scratch in any language you want. Tests check input/output behavior against the original binary. 200 tasks, from small CLI tools up to FFmpeg, SQLite, and the PHP interpreter. 📊 Results across 9 models: Zero tasks fully solved. Opus 4.7 was the best, passing 95% of tests on only 3% of tasks. GPT 5.4, Gemini 3.1 Pro, and Haiku 4.5 hit 0% in that bucket. The interesting part is section 5. Even the model solutions that "worked" looked nothing like the human reference. Median 1,173 lines vs 3,068 in the original. Flat directories. Fewer functions, each one longer. GPT 5.4 wrote 96% of its final code in a single turn on most tasks and never modified existing files on roughly 40% of runs. 🎯 Why it matters for us: The benchmark separates writing code from designing software. Models can produce syntax all day. They cannot yet decompose a real system into coherent modules, pick the right abstractions, or organize a codebase the way a working engineer would. That gap is what computational orchestration points at. It is also where the durable value lives. 🛠 Try it: Pick an easier task from the repo (the paper flags nnn, fzf, gron, and jq as more tractable). Run it against Claude or your model of choice. Watch where you and the model split. Note the design decisions you make that the model never even raises. Post your runs and attempts to create a harness that would allow the model to do it. Wins, failures, weird outputs, all of it. 📍 Paper and Repo: ProgramBench I'm building something on top of this right now. More soon.

14 likes • 2h
Honestly, I don’t think it’s too late at all. I think a lot of us are feeling that same tension right now — trying to figure out what’s still worth learning in a world where the tools are evolving so fast. But the more I watch this space, the more I feel like curiosity itself is becoming the skill. The people asking questions, experimenting, learning how systems work, and staying adaptable are probably going to do just fine. You don’t necessarily need to become a hardcore software engineer to benefit from understanding this stuff better. Even just learning enough to think with the tools instead of around them feels incredibly valuable now.

1d •
This is a completely different discusion, but why not?
Just posted a comment in a lesson post, but I actually thought it will be amazing to read everybody's thoughts about it. It goes more towards the philosophical conversation, but I think is an interesting one. So, this is my hypothesis: What if we actually are just a more evolved type of LLM's, trained since birth, with thousands and thousands years of development, with more input sources (5 senses, so 5x different languages combined), and what we call consciousness is just a more sophisticated form of programming? Would love to hear your ideas ❤️
1 like • 3h
Don’t mean to add complexity to the discussion 😅 but what’s fascinating is that neuroscience already challenges the idea that humans only have 5 senses. There’s proprioception (awareness of body position), interoception (awareness of internal body state), balance/vestibular sense, etc. Some researchers now argue we may have 20–30+ sensory systems working together. Makes me wonder if consciousness is less about a single “mind” and more about an incredibly complex integration layer processing internal + external signals simultaneously. Maybe what we call “self” emerges from that orchestration. Really interesting discussion. https://scitechdaily.com/you-dont-have-just-five-senses-new-research-suggests-humans-may-have-up-to-33/
1 like • 2h
Yes, maybe the AI version of this is memory + reflection + feedback loops. Humans use meditation to notice patterns inside themselves: emotions, reactions, attention, habits. AI systems might need something similar structurally — not “meditation” in the human sense, but pauses where they review context, detect drift, summarize what changed, update memory, and realign with the user’s intent. Almost like giving the system a practice of self-checking before it keeps acting.

3h •
Memory management is the next frontier!
Most people are still treating LLMs like goldfish with infinite context windows. But the real power comes when you give your AI systems persistent, structured, and reliable memory. I’ve been diving deep into three distinct approaches: - Open Brain (OB1) — the personal exocortex - Poor Man’s Memory (PMM) — the ultra-lightweight, git-native path @Millenial Cat - Cognee — the structured graph + vector layer for serious agents Each represents a completely different philosophy for how we should capture, store, and retrieve context. Full breakdown dropping soon: architecture comparisons, strengths & tradeoffs, how they actually fit together in a real stack, and when I’d choose one over the others. If you’re building any kind of long-term AI workflow, personal knowledge system, or agent setup — this one’s for you.What’s your current memory strategy? Drop it below
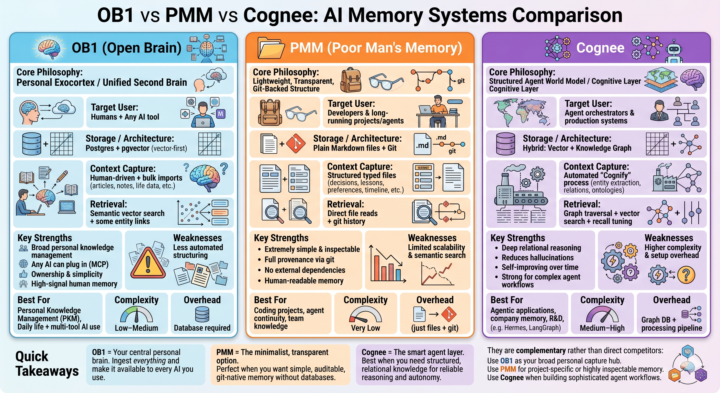
1 like • 3h
Really interesting seeing the different approaches converge around the same core problem: not just making models “smarter,” but building systems that can maintain continuity, context, and evolving understanding over time. Feels like we’re starting to separate short-term cognition from long-term accumulated knowledge the same way humans do. Noticing a pattern across a lot of these setups: the real bottleneck isn’t generation anymore — it’s organization, retrieval, memory hygiene, and preventing context drift as systems scale. Feels like an entirely new layer of engineering is forming around cognitive infrastructure itself.
5h •
🚀 Vibe Coding is the new Technical Debt. Meet SDD.
If you want to drop this in the Skool community and actually get the attention of the high-level engineers, you need to lead with a pattern interrupt. These guys see "How to prompt" posts all day—you need to tell them why their current workflow is about to hit a ceiling. Here is the exact post I would write for you: Headline: Vibe Coding is the new "Technical Debt." It’s time to talk about SDD. We’ve all seen the magic. You vibe with Claude or Cursor, you prompt your way into a working MVP in three hours, and it feels like we’ve conquered the world. But there’s a wall coming for all of us. Once your project hits 5,000+ lines of code or requires complex state management, "vibing" starts to fail. The AI begins to loop, it hallucinations your file structure, and you spend more time "fixing the fix" than building features. The elite 1% of AI Engineers are moving toward Spec-Driven Development (SDD). The SDD Framework (How the Pros are building now): Instead of jumping straight to the prompt, you insert a "Contract Phase" using two specific files in your root directory: 1. spec.md: The "Source of Truth." This isn't just a prompt; it’s a rigorous definition of every user journey and data model. 2. plan.md: The "Execution Guardrails." This tells the AI exactly how to implement the spec, defining the file structure and API contracts before it writes a single const. Why this is your new "Moat": In a world where everyone can "vibe code," the code itself is a commodity. Your value as an AI Engineer in 2026 isn't your ability to prompt—it’s your ability to Architect. • Determinism: SDD stops the AI from guessing. • Context Management: By referencing a central spec, you keep the "God Object" in the AI's head consistent. • Scale: This is how you move from "cool demo" to "enterprise-grade SaaS." Stop prompting. Start Architecting. Check out this InfoWorld breakdown on why this shift is happening: https://www.infoworld.com/article/4166817/vibe-coding-or-spec-driven-development-how-to-choose.html
0 likes • 4h
@Josh Harper Josh, great shout. Matt’s skills are the perfect 'Mechanism' for this. I’ve been looking at /grill-me specifically as the best way to bridge the gap between a 'vibe' and a 'spec.' It’s the closest thing we have to a professional standard right now. Are you finding /improve-codebase-architecture is actually helping with the 'Ball of Mud' issue on longer projects?
0 likes • 3h
@David Vogel David, appreciate this. I’m still learning this side of the stack, so BMAD and GSD are exactly the kind of frameworks I was hoping people would bring into the discussion. Seems like the real move isn’t killing vibe coding, but adding structure so it doesn’t drift when projects scale. I’ll definitely dig into these.
22h •
Working on a governance-style onboarding audit system for agencies and researching “Week Two Nightmare” operational failures.
I’m researching operational failure patterns during agency onboarding and trying to isolate the exact conditions that create “Week Two Nightmare” clients. Not looking for client drama or personality stories — specifically operational breakdowns like: - missing access/logins - unclear KPIs - impossible launch timelines - approval bottlenecks - stakeholder confusion - fulfillment inheriting chaos after the sale closes I’m building a governance/audit framework to analyze whether these instability conditions were actually visible before fulfillment labor was committed. Everything can be anonymized. If you’ve ever had a project where:“sales was excited but operations inherited a grenade”…I’d love to study the operational signals behind it. Curious whether anyone here has experienced operational drift between Sales excitement and Fulfillment reality.
1
0
1-10 of 47

@luis-arias-2984
Learning AI and automation by building real systems. Working on a trading bot with data, APIs, and local AI models like Ollama.
Online now
Joined Mar 28, 2026
ENTJ
Miami, FL.
Powered by