
Write something

Mar 16 •
🚀 你的 Agent Skill 寫了好幾天還在調?讓 Skill 自己優化自己!
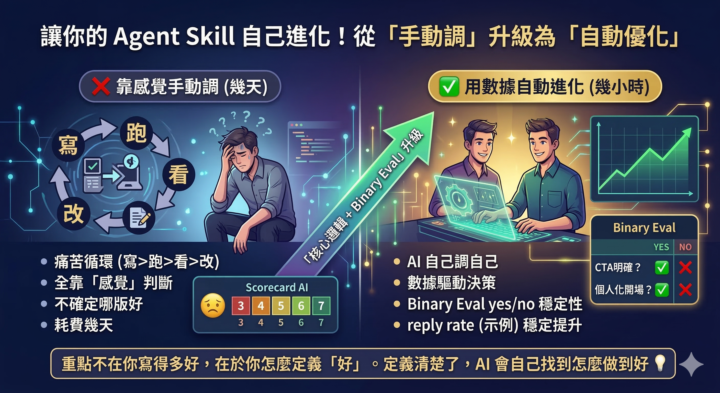
每次寫完一個 Skill,是不是都經歷這個循環? 寫好 SKILL.md → 跑一次 → 看輸出 → 覺得不太對 → 改指令 → 再跑 → 還是不太對 → 再改… 整個過程全靠你的「感覺」判斷。改了 10 版,不確定第 10 版是不是真的比第 1 版好。一個 Skill 調到穩定,花幾天很正常。 但如果有一套方法能讓 AI 自己調自己的 Skill 呢?今天分享 AutoResearch 的核心邏輯、Binary Eval 這個關鍵技術、以及怎麼套用到你自己的 Skill 上 👇 1️⃣ AutoResearch 的核心邏輯 AutoResearch 是用來自動優化 AI 的框架,原本拿來優化 AI 模型。 核心邏輯很簡單: 定義一個指標 → AI 自動跑多種變體 → 評分 → 保留更好的版本 → 淘汰差的 → 循環 這跟我們調 Skill 是一模一樣的道理。差別只在一點:AutoResearch 把「你靠感覺調」變成了「AI 用數據調」。 700 次自動實驗跑完,找到 20 個有效的優化方向,整體提升 11%。聽起來不多,但重點是:這全部是 AI 自己跑的,不需要人盯。 2️⃣ Binary Eval:讓 AI 穩定評分的關鍵 這裡有一個大部分人不知道的坑。 你可能想:「讓 AI 打分不就好了?」 問題是,用 1-7 分讓 AI 評分,同一個輸出它這次給 5 分,下次給 3 分,結果根本不穩定。AI 打分的變異性太大,你根本無法判斷 A 版本是不是真的比 B 版本好。 ❌ 錯誤做法:讓 AI 用 1-7 分評分 → 每次結果不同,優化方向亂跑 ✅ 正確做法:Binary Eval — 把所有品質標準拆成 yes/no 問題 「有沒有個人化開場?」→ yes 或 no 「CTA 是否只有一個?」→ yes 或 no 「subject line 少於 10 個字?」→ yes 或 no yes/no 的答案每次都一樣,AI 就能穩定判斷哪個版本更好。 這是整個系統能跑起來的關鍵。沒有穩定的評分,自動優化就是空談。 3️⃣ 實際例子:Cold Email Skill 假設你有一個寫 Cold Email 的 Skill。跑出來的信件,有些回覆率高,有些石沉大海。 以前怎麼調? 靠感覺:「好像 subject line 太長了」「CTA 不夠明確」 改完再跑,不確定是不是真的變好了 套用 AutoResearch + Binary Eval 的邏輯: 📊 把 reply rate 設成核心指標 📋 品質標準拆成 10-15 個 yes/no 問題 🔄 AI 自動跑幾十種變體 📈 每輪保留通過率更高的版本 行業平均 cold email reply rate 只有 3.43%,但 top performers 超過 10%。差距就在 Skill 指令的細節裡 — 而這些細節,用 Binary Eval 可以一個一個揪出來。 同樣邏輯可以套用到任何 Skill: 🔸 內容生成 Skill → 指標 = 品質通過率 🔸 SEO 文章 Skill → 指標 = 排名或流量 🔸 圖片生成 Skill → 指標 = 視覺品質通過率 🎯 結論:從「手動調 Skill」升級為「讓 Skill 自己進化」 舊思維:寫好 Skill → 靠感覺微調 → 花幾天找到「還行」的版本 新思維:定義指標 → 拆成 yes/no → 讓 AI 自動跑實驗 → 幾小時內找到最優版本 重點不在你寫得多好,在於你怎麼定義「好」。定義清楚了,AI 會自己找到怎麼做到好 💡 你有什麼 Skill 想用這個方法來優化?歡迎留言分享你的想法 👇
Mar 6 •
🚀 你的 Agent Skills 真的有好好工作嗎?
用 Claude Code Skills 的人一定遇過這種情況: 你寫了一個 Skill,開 thinking mode 檢查,發現它根本沒有自動觸發 你只好手動打 /skill-name 或者直接跟它說「用 XX skill」 如果每次都要你手動指定,那寫 Skill 的意義在哪? Anthropic 剛更新了官方的 Skill Creator Plugin,直接解決這個問題 而且背後的信號比功能本身更值得注意 1️⃣ 🔍 先搞懂根本原因:為什麼自動觸發不準? Claude 決定要不要用你的 Skill,不是讀完整份 SKILL.md 它只看 title + 大約 100 字的 description 然後決定要不要啟用 description 太寬 → 亂觸發,叫 A 它跑了 B description 太窄 → 從來不自動觸發,每次都要你手動指定 你確實可以在 thinking mode 裡看到它有沒有觸發 但問題是,你不可能每次用每種問法都手動檢查一遍 Anthropic 拿自己的 6 個官方文件類 Skills 跑了一次 Trigger Tuning 結果:5 個的觸發準確度都還有提升空間 連官方自己寫的都有優化餘地 2️⃣ 📊 Eval — 幫你的 Skill 寫「考試卷」 這是軟體工程裡「自動化測試」的概念 寫程式有 unit test,現在寫 Skills 也有了 你定義一組測試 prompt + 預期結果 Skill Creator 自動跑一輪,告訴你每題 pass 還是 fail 不用再一個一個手動試 最實用的場景:模型更新後,跑一次 Eval 就知道你的 Skill 還能不能用 不用等到出問題才發現 根據 Anthropic 的測試,PDF 填表 Skill 跑完 Eval 優化後 原本填錯位置的問題全部修好了 3️⃣ 🎯 Trigger Tuning — 解決「叫了不來」的問題 如果你有 10 個以上的 Skills,一定遇過觸發打架 想用 Skill A,結果 Claude 跑去用 Skill B Trigger Tuning 會分析你目前的 description 用不同的問法反覆測試,自動調整措辭 用 60/40 的 train/test split,每輪跑 3 次取平均 最多迭代 5 輪,找到最佳平衡 Anthropic 自己測了 6 個官方 Skills 5 個觸發率都有提升 4️⃣ 📈 Benchmark — A/B 對比測試 這個功能超實用: 「有 Skill」vs「沒有 Skill」,同時跑,量化給你看 你會拿到三個關鍵數據: 📌 Pass Rate — 通過率多少 📌 Token Usage — 花了多少 token 📌 Total Time — 跑了多久 甚至可以比較兩個版本的 Skill,看哪個更好 如果「沒有 Skill」反而更好 → 這個 Skill 該退役了 5️⃣ ⚡ 這次更新背後的信號 Anthropic 願意花資源建 Eval 系統 代表他們把 Skills 當作長期核心功能,不是一個實驗性玩具 以前所有 AI 的 prompt、workflow 都是「寫完就上,出事再改」 現在 Anthropic 說:不行,你要先測過 這在 AI 工具圈是第一次 定義輸入 → 定義預期輸出 → 自動跑 → 報告結果 就是軟體工程裡的自動化測試,套用在 AI Skills 上 寫 Skill 的門檻會越來越低,以後人人都會寫 但誰能管好自己的 Skills,誰的 AI 助手才真的可靠 ⭐ 結論:從「手動檢查」升級為「用數據驗證」 以前寫 Skills:寫完 → 開 thinking mode 看一次 →「這次有觸發」→ 上線 現在寫 Skills:寫完 → Eval 測品質 → Benchmark 對比效果 → Trigger Tuning 優化觸發 → 確認沒問題才上線 Skills 的門檻只會越來越低 但品質管理只會越來越重要 以後人人都會寫 Skill,差距在誰會管理 Skill 你的 Claude Code 有幾個 Skills?有沒有遇過觸發不準的問題?歡迎留言分享 👇 想知道具體怎麼安裝、怎麼跑 Eval、怎麼做 Trigger Tuning? 付費群有完整的操作教學,包括兩種 Skill 類型怎麼分別測試 ✅

Mar 7 •
你用 AI 寫內容,但有沒有讓 AI 真正幫你提高效率?
很多人已經在用 ChatGPT 寫文案、用 AI 生圖、用 AI 想點子 但每次做完一篇文章之後,還是要花大量時間手動改格式、上傳、整理 老實說,這不叫「AI 提效」,這叫「AI 幫你做了一半,另一半你自己收尾」 今天來聊一個我自己實測有效的做法: 把 AI 從「單點工具」升級為「自動化內容系統」 📊 先看一組很有意思的數據 根據 2025 年多份行銷研究報告,94% 的行銷人員已經在用 AI 做內容了 理論上,AI 能把內容創作時間壓縮 90%,從 16 小時降到 1.5 小時 但實際上呢?大部分人只省了 30-40% 的時間 為什麼落差這麼大? 原因很簡單:大部分人只是把「每一步」各自加速 想 idea 用 AI,寫文用 AI,生圖用 AI 但步驟之間的 copy paste、格式轉換、手動上傳、更新記錄 這些「中間步驟」全部還是自己來 ❌ 用 AI 寫完文章 → 手動改成 IG 版 → 再改 Threads 版 → 再改網站版 → 生圖 → 上傳 ✅ 給 AI 一個主題 → 自動產出所有平台版本 + 配圖 + 上架 差別在哪?不是 AI 寫得更好,而是你有沒有把整條線串起來 🔧 我的做法:一個主題 → 30 分鐘 → 7 個平台版本 以前我寫一篇內容的流程是這樣: 1️⃣ 用 ChatGPT 研究主題 + 寫好一篇文章(30 分鐘) 2️⃣ 手動改成 IG 版、FB 版、Threads 版、網站版(1 小時) 3️⃣ 生成配圖、上傳網站、更新數據庫記錄(30 分鐘) 總共 2 小時,才搞定 5 個版本 後來我用 AI 建了一套自動化寫文系統,現在的流程: 1️⃣ 給 AI 一個主題 2️⃣ AI 自動做深度研究 + 驗證數據 3️⃣ 自動生成 Threads 串文、Facebook 長文、IG 短版、私域付費教學 + 免費引流、Patreon 付費 + 公開網站 4️⃣ 配圖自動生成,文章自動上架網站 30 分鐘,7 個版本 + 配圖 + 上架 我只需要確認 3 份核心內容,其餘全部自動格式轉換 💡 關鍵不在 AI 多聰明,在你怎麼串 有公司用完整的 AI pipeline,把一個 60 分鐘的產品 demo 自動拆成 47 篇內容,分發到 7 個平台 研究也說,content repurposing(內容再利用)能增加 40% 的產出,時間不用增加 但如果你連轉換本身都自動化了,增加的不是 40%,是 300% 這裡有幾個值得做的方向: 📌 先列出你要發的所有平台(大部分人其實只有 3-5 個) 📌 想清楚哪些內容可以互相轉換,不用每個平台從頭寫 📌 定義好每個平台的格式規範,讓 AI 自動套用 📌 核心內容你自己把關品質,格式轉換讓 AI 全包 也有幾件事不該做: ⚠️ 每個平台都重新寫一遍 → 你在浪費 70% 的時間 ⚠️ 追求每篇都「完全不同」→ 你的讀者不會全平台跟蹤你 🧠 更重要的原則 你的時間應該花在「想法」和「品質把關」,不是「copy paste」和「格式調整」 AI 時代的內容效率,不在你用了多少 AI 工具 在於你懂不懂把事情串在一起,自動化來做 從「用 AI 寫東西」升級到「讓 AI 自動出內容」 這個思路一旦打通,你每天能產出的內容量會完全不一樣 你目前的內容流程是怎樣的?有沒有把多個平台的發布自動化?歡迎留言分享你的做法 👇 加入付費學習中心,了解更多

Jan 23 •
🎉 Agent Skills 訓練營 Day 1 順利完成!Day 2 預告來了!
昨晚的直播,各位觀眾跟著我一起,從完全不懂 Agent Skills,到 1 小時了解什麼是Agent Skills。 我想做這個免費訓練營的原因——讓每個人都能親手體驗 AI 自動化的威力,而不只是「聽說很厲害」。 1️⃣ Day 1 我們學了什麼? 昨天的直播,我帶大家完成了三件事: 🔧 觀念重塑:Prompt vs Skill vs MCP 很多人搞不清楚這三個東西的差別。我用「實習生理論」解釋: • Prompt = 口頭交辦 • Skill = 職位 SOP • MCP = 員工權限卡 搞懂這個,你就懂 AI Agent 的全貌了。 💻 實戰演示: 一鍵生成 PPT、影片分析轉貼文。不是紙上談兵,是真的打開電腦,一步一步操作給你看。 🛠️ 手把手部署: 用 Google Antigravity 免費裝進你的電腦。 沒錯,完全免費。你不需要訂閱任何付費服務,就能開始使用 Claude Opus + Agent Skills。 2️⃣ Day 1 錄影已上 Classroom! 錯過直播的朋友不用擔心,60 分鐘完整錄影已經放上 Classroom了。 3️⃣ Day 2 預告:從零打造你自己的 Skill! 📅 時間:1/27(週一)晚上 8:30 ⏱️ 時長:1 小時 Day 1 我們學會了「怎麼用別人做好的 Skill」。 但你一定發現了:別人的模板,總有些地方不太合你的工作流程。 所以 Day 2,我要教你: 【如何從零開始建立一個 Skill】 ✅ 完整的建立過程 ✅ 每個步驟的技巧和眉角 ✅ 新手最常踩的坑(以及怎麼避開) 這才是真正讓 AI 變成「你的數位分身」的關鍵。 4️⃣ 為什麼你應該來參加 Day 2? ❌ 只會用別人的模板: 遇到不合用的地方,只能將就或放棄。 ✅ 懂得自己建立 Skill: 根據你的工作流程,打造 100% 貼合需求的 AI 助手。 這就像是: • 買現成西裝 vs 量身訂做 • 套用別人的 Excel 公式 vs 自己寫公式 根據 Anthropic 官方建議,一個好的 Skill 應該: 📏 控制在 500 行以內 🎯 Description 寫得具體(這是 Claude 決定是否啟用的關鍵!) 📂 善用漸進式揭露(大型參考資料拆成獨立檔案) 這些細節,我會在 Day 2 全部講清楚。 5️⃣ 如何參加? 這個訓練營完全免費,為期 3 天: ✅ Day 1(1/22):已完成,錄影在 YouTube 🔜 Day 2(1/27):如何從零打造 Skill 🔜 Day 3(1/29):進階技巧 + Q&A

Feb 4 •
🌐 零基礎搭建個人網站 — 溝通才是關鍵!
自己用 IDE 從零搭建了個人網站,根本不需要懂 HTML。 但我發現,大多數人失敗的原因不是「技術不夠」,而是「不會跟 AI 溝通」。 【最常見的錯誤】 ❌ 錯誤心態: 「AI 很厲害,一次把所有需求丟給它,讓它直接做完」 結果: • AI 生成了一個不符合你期待的網站 • 要重新修改時,發現改 A 壞 B • 最後整個專案崩潰,重頭再來 【正確的搭建流程(3 步走)】 1️⃣ Step 1:先確定整體架構(不要讓 AI 直接寫 code) 一開始不要急著要程式碼,先跟 AI 對齊「網站架構」: 你: 「我想建一個個人品牌網站,要有首頁、關於我、作品集、聯絡方式這 4 頁。你覺得這樣的架構合理嗎?還有什麼建議?」 AI 會給你回饋,例如: 「建議首頁加上 CTA 按鈕」、「作品集可以分類展示」 確認架構後,才開始進入開發階段。 2️⃣ Step 2:逐頁逐區塊修改(一次只改一個部分) 千萬不要一次丟 10 個需求: ❌「幫我把首頁改成深色模式,順便調整字體,然後加上動畫效果,還有把 CTA 按鈕改成綠色⋯⋯」 這就像你一次交 10 件事給新員工,他一定會搞砸。 ✅ 正確做法: • 第一輪:「先把首頁改成深色模式」 • 確認沒問題後,第二輪:「把標題字體改成 Montserrat」 • 再確認後,第三輪:「加上淡入動畫」 為什麼要這樣做? 因為 AI 每次修改都是基於「當下的版本」。如果你一次改太多東西,AI 很容易搞混,把上一版的正確程式碼改壞。 分步修改 = 每一步都可控,出問題立刻抓到 一次性大改 = 出問題後不知道哪裡錯,只能重來 3️⃣ Step 3:部署到伺服器 網站做好後,你有 3 種選擇: 🔹 GitHub Pages • 適合誰:學生、測試用 • 成本:免費 • 優點:✅ 免費 • 缺點:❌ 只能放靜態網站 🔹 Hostinger • 適合誰:個人品牌、小生意 • 成本:US$2/月 • 優點:✅ 便宜、穩定、✅ 支援 WordPress 🔹 Vercel • 適合誰:開發者 • 成本:免費 ~ US$20+ • 優點:✅ 部署快 • 缺點:❌ 商業用途要付費 我推薦新手用 Hostinger,原因: • 固定月費 US$2,不會有意外帳單 • 附贈網域名稱(省一筆錢) • 支援 WordPress(以後想用模板也可以) 💡 最重要的一句話: 跟 AI 合作建網站,就像管理一個遠端員工 —— 你不會一次把所有需求丟給他,而是先交代一件事,做好了再交下一件。溝通的節奏,決定了專案的成敗。 🏆 結論:從「AI 輸出消費者」升級為「AI 成果策展人」 以前我們用 AI,是「消費者心態」: • AI 跑完了,我複製貼上 • 資料散落各處,要用的時候再去找 • 越用越亂,最後放棄整理 現在我們用 AI,應該是「策展人心態」: • AI 是我的助手,我是總指揮 • 我設計好「成果的家」(前端界面),AI 負責填充內容 • 資料越多,我的系統越強大 與其每次花時間在終端機裡翻找舊資料,不如花一次時間搭建一個前端界面,讓所有成果都有一個「家」。 這才是 AI 時代真正高效的工作方式。 你有什麼想用 AI 搭建的前端界面嗎?或是已經用 Skills 建了什麼有趣的東西?歡迎留言分享!👇
1-5 of 5
powered by

skool.com/hei-ai-8196
這是一個幫助你掌握AI自動化工作以及AI Agent (AI代理) 的中心。讓我們一起利用AI令你的人生更精彩!
升級至VIP:
skool.com/ai-plus-8477
Suggested communities
Powered by