
Write something
Pinned

May 14 •
0 to Indexing in <24
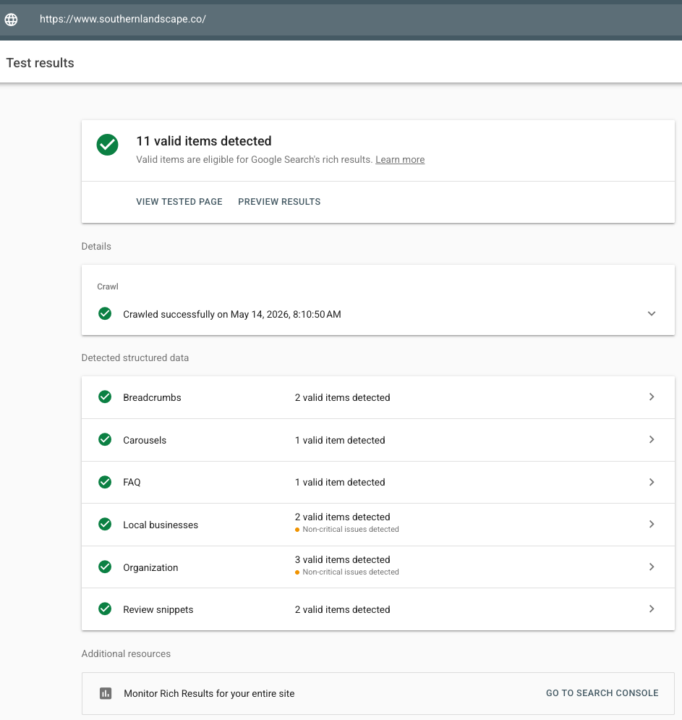
The Power of Clean Schema 🚀 Launched a new project last night for a landscaping client. Checked the stats this morning and the "machine-readability" is already paying off. The Win: - 11 Rich Result Findings: Validated everything from LocalBusiness to ReviewSnippets immediately. - First Impression Logged: Already showing up for "hardscaping services springboro oh". The Takeaway: In the AEO/GEO era, you don't wait for Google to "find" you. You give the LLMs and Search Crawlers a structured map they can't ignore. 11 valid items isn't just a vanity metric—it’s the reason this site is already live in the SERPs while the competition is still waiting to be crawled. https://www.southernlandscape.co/
Pinned
May 4 •
Welcome to the AI Visibility Lab.
Hey — welcome. I'm Alex. I've been doing SEO for 15 years and I built this lab because the way search works has fundamentally changed and most people are still optimizing for the wrong thing. Rankings matter. But AI systems — Google's AI Overviews, ChatGPT, Perplexity — now select which source to cite before anyone clicks. If your content isn't built to be extracted and cited, it doesn't matter how well it ranks. That's what we're here to fix. This isn't a tips group. It's a working lab. You bring something real — a website, a page, a draft, a problem — and we help you build something structured you can actually deploy. Start here: 1. Run the Entity Health Check (in the Start Here module). 2. Drop your result and intro below — name, what you do, your site, and what you want AI to understand about your brand. See you in the lab. — Alex
0
0
22h •
Shifting from Page-Based Thinking to Graph-Based Architecture (The Service Business Spec)
Hey everyone — happy Tuesday. We talk a lot in the lab about how the gap between getting ranked and getting selected by AI systems is entirely structural. Today, I want to drop the exact content engineering blueprint for building an enterprise-grade semantic system. If you run an agency, consult, or build visibility stacks for local service businesses (or brick-and-mortar operations), you can deploy this framework directly into your CMS templates to automate machine-readability. The Core Concept: The Web Is a Map, Not a Folder Traditional SEO treats a website like a folder of separate pages. AI systems—Google AI Overviews, ChatGPT Search, and Perplexity—treat it like a localized Knowledge Graph. If your schema properties are just thrown on a page via basic standalone plugins, you're delivering fragmented data soup. If you want high citation confidence, you need a rigid hierarchy of Hubs, Nodes, and Edges. I've put together a quick technical teardown matrix showing exactly how this lines up across your content layers: SEO = Classic SERP Lean HTML5 code, strict URL directory design, keyword-to-intent matching. AEO = Answer Extraction Engines Schema-validated FAQ blocks + direct summary text (150-200 characters) immediately following your question headers. GEO = Generative Engine Citations Hard entity corroboration. Mapping primary nodes to Wikidata via sameAs arrays and anchoring pages to verified expert entities. How to Build it Safely in Your CMS Templates Instead of editing things manually page-by-page, map these 3 components directly into your global page layouts (whether you use Webflow, WordPress, or custom headless builds like Sanity): 1. The Claim Component: A dedicated landing section that mathematically clarifies Who is performing the service, What the service parameters are, Where it physically takes place, and the Proof behind it. 1. The E-E-A-T Author Object: Never leave service content anonymous. Dynamically link every single landing page to an author entity profile that parses a clean Person node (jobTitle, knowsAbout, alumniOf).
0
0
19d •
THE W-A-R-O FRAMEWORK
Interactive site: https://click-for-me.manus.space/ This page serves as an interactive methodology guide and companion tool for your book, Click For Me: A Simple Guide to AI That Uses Your Browser. Specifically, it is designed to teach and help you implement the W-A-R-O Framework, which structures prompts to turn a browser AI into a highly precise, read-only digital assistant. Here is what you can do on this page: - Learn the 4 Pillars of Browser Prompting: It breaks down the framework's core components: - Use the Interactive Prompt Builder: You can select various presets—like Competitor Intel Collector or - Form-Prep Assistant—to see how a structured W-A-R-O prompt compiles in real-time. - Build Custom Blueprints: The sandbox at the bottom allows you to input your own custom task, area, rules, and output requirements to instantly generate a repeatable, structured prompt that you can copy and paste into Gemini, ChatGPT, or Claude. Click For Me GPT: https://chatgpt.com/g/g-6a1524ce81a08191bebd3e87a1834a41-click-for-me-gpt Click For Me: A Simple Guide to AI That Uses Your Browser Kindle Edition https://www.amazon.com/Click-Me-Simple-Guide-Browser-ebook/dp/B0H2XZMJX1/?tag=haitianpikliz-20

11d •
I Sell AI Visibility Work. Here's How to Check People Like Me.
Quick disclosure before anything else: I do this work for a living. Which is exactly why I'm handing you the questions that filter operators from spam. If these questions would disqualify me, they should disqualify me. The AEO pitch wave is in full swing. Agency listicles flooding Reddit. "LLM optimization" retainers. Vendors borrowing credibility from real mechanisms (RAG exists, retrieval is real) to sell unproven tactics. One enterprise SEO director I follow described a company that added FAQs site-wide because an agency said it helps LLMs extract answers. Their SEO dropped across multiple content types. The AI lift never came. Now they're paying a second time to rip it all out. That's the failure mode: real mechanism, spam execution, no measurement. Here are the five questions that catch it before you sign. 1. "What do the engines currently say about my business?" Ask this first because it's the cheapest test. A real operator captures a baseline before proposing anything — what ChatGPT, Perplexity, Gemini, and AI Overviews actually return for your buying-intent prompts today. If they pitch tactics before they've documented your current state, they're selling a package, not solving your problem. You can't measure a change against a baseline nobody took. 2. "Can you show me before/after data on a site that isn't your own case study?" Stolen directly from an enterprise SEO director, because it's the best filter in the industry right now. Fair warning: almost nobody can fully answer it — controlled third-party proof barely exists in this space yet. That's fine. What you're listening for is whether they admit that. "Here's our internal data, here are its limits, here's what we can't claim" is an operator. "We dominate AI search for our clients" is a walk-away. 3. "Is this reversible?" Every structural change should have an undo path. The FAQ-everywhere company is paying twice because nobody asked this. Site-wide content injections, separate machine-readable sites, mass schema changes — if it can't be rolled back cleanly, the downside isn't zero results. It's site debt plus a cleanup project.
0
0
1-25 of 25

skool.com/alex-rodriguez-seo
A practical AI visibility lab for business owners, marketers, and operators who want to get found, trusted, cited, and selected.
Leaderboard (30-day)
1

+1
Powered by