Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Owned by Theresa
🚀 Your Goals, Our Method 📲 Our App + Your Actions 🏡 ADHD & TBI Help 💪 You CAN achieve ANY goal! ✅ From Dream to DONE 🌍50+Languages Supported
Memberships
BrandVoiceAI
12 members • Free
Christian Gals with Goals
38 members • Free
Skool Extensions 🧩
633 members • Free
The Founders Guild
1.1k members • Free
Skool Growth Free Training Hub
8.7k members • Free
Claude Code Club
7.1k members • $9/month
THRIVE After 40: Get Sexy Back
42 members • Free
eXplorers 🚀
72 members • $7/month
Aquarium Tips For Beginners!
2 members • $5/month
114 contributions to AI Automation Society

💎
⭐
59m •
🚀New Video: Claude Code + Clay Makes Lead Generation Actually Fun
Finding leads is the thing that blocks most people from landing their first client, so in this video I connect Claude Code to Clay and build a lead generation machine you run entirely in plain English. Claude Code is the orchestrator and Clay handles the data, sourcing real businesses, enriching them with verified emails and phone numbers through its waterfall, and writing a personalized email for every single lead. I run a real HVAC example that pulled 50 fully enriched leads with custom subject lines and bodies for about 12 dollars in credits, then take the whole list into Clay to buy domains, warm them up, and launch the campaign. If you have been putting off cold outreach because the data and the tools felt like too much to manage, this is the easiest way I have found to do it.

🔥
0 likes • 28m
I can’t wait to watch this
💎
⭐
3d •
🚀New Video: I Tested GPT 5.6 Sol vs Fable 5. What You Need To Know.
I spent all day running GPT-5.6 Sol against Claude Fable 5, side by side, on real work instead of just staring at benchmarks. I put them head to head in Codex and Claude Code on browser games, interactive websites, and open-ended builds, then ran a bunch of quick one-off tasks over the API to see how they compare on speed, cost, and reliability. My take: Fable is the better manager and the more creative, capable model, while Sol is a really good worker that ships fast and costs a fraction of the price. Watch to see where each one wins and how I decide which model to reach for.
🔥
4 likes • 2d
@Jason Elam he sure is!
💎
⭐
4d •
🚀New Video: Fable 5 Just Built Me a Business With One Prompt
I gave Claude Fable a single goal prompt: build me a complete company from scratch, starting with nothing but the open internet. A few hours later I had a real product, a landing page, two launch videos, a founder video, a business plan, and market research, all built by hundreds of subagents that Fable planned, delegated, and reviewed. In this video I walk through everything it produced and break down the exact prompt that made it happen.
🔥
1 like • 3d
Genius. Love this.
🔥
1 like • 3d
@Nate Herk where is the prompt so we can try it? Is it in the classroom?
💎
⭐
9d •
🚀New Video: Fable 5 + Karpathy’s LLM Wiki is Basically Cheating
I ingested all my YouTube videos into an LLM wiki and turned them into a connected second brain that my AI OS can actually reason over. In this one I show you how to build the same thing in about five minutes using Claude Code and Obsidian, based on Andrej Karpathy's LLM knowledge base idea. You drop in sources, the AI reads them, splits them into cross-linked wiki pages, and keeps the whole thing organized with routing rules so it can find anything fast. By the end you'll know how to set up the vault, write the schema, ingest a PDF and a URL, and decide when to keep your wiki flat versus structured.
🔥
18 likes • 9d
Wow!!! This is amazing. Can’t wait to dive in
💎
⭐
11d •
June MVPs Are Here! 🏆
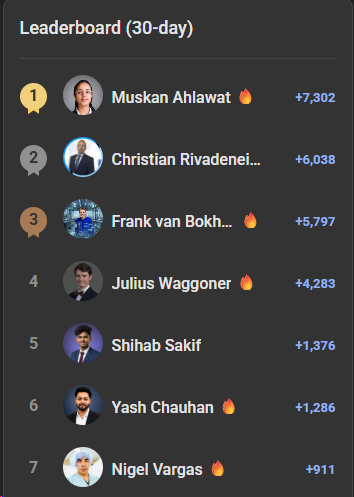
Huge shoutout to the Top 5 Members of AI Automation Society for June! These are the people leading the way, sharing knowledge, and helping spread the AIS culture: 1️⃣ @Muskan Ahlawat 2️⃣ @Christian Rivadeneira 3️⃣ @Frank van Bokhorst 4️⃣ @Julius Waggoner 5️⃣ @Shihab Sakif And a special mention to @Nigel Vargas, who takes 6th and just missed the Top 5. We're rooting for you to break through in July! 👏 Keep contributing, sharing wins, and helping others grow! Our community gets better because of you. Let's keep building, keep learning, and keep spreading that AIS energy. 🚀 Cheers, Nate P.S., @Yash Chauhan is an AIS community manager, so his points don't count towards this ranking.
🔥
3 likes • 11d
CONGRATULATIONS EVERYONE
1-10 of 114

🔥
@theresa-elliott-8825
Navy Veteran. Mom. Wife. AI Builder.
Join My FREE 28-Day Action Plan community to ACHIEVE ANY GOAL.
Results, Not Hype. Come See for Yourself!
Active 9m ago
Joined Dec 26, 2025
ENTP
outside Washington, DC
Powered by