Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Clief Notes
40.1k members • Free
AI Automation Agency Hub
327.4k members • Free
3 contributions to Clief Notes

2h •
Question
Hi, I was wondering if someone can explain if there is a difference between having a file structure in VSCode or in Obsidian It seems to me that they accomplish the same thing, or am I missing something?
1 like • 1h
@Taofeek O. a. Interesting, that’s actually a very smart move to make it easier for the majority. Does seem like going the extra mile 🤣 So, if I understand you correctly, you’re building some kind of app/website that routes to those file structures through clicks of a button essentially?
1 like • 1h
@Taofeek O. a. Cool, I’ll experiment with that. Thanks!

👑
⭐
3d •
🗺️ Afternoon Tea #9 from last week is in The Vault
Recording's up, and I packaged the whole thing so you can drop it straight into your second brain or hand it to your AI. 🍵 Here's what we got into this session: 🧠 Map your work, don't just store it. A second brain holds notes. A map holds your work plus the people and data around it — teams, processes, and the links between them. You can't improve what you can't see, and neither can your AI. 🔗 Every workflow is a node. One markdown file = one process. The references between them are the edges. That's the whole graph. 🟢 Build workflows, not outputs. Store the outputs inside the workflow. Then when Opus 4.8 or Fable ships, the right feeling is "cool, my system just got better" — not scrambling. 🔍 Google basically proved the method. Their new Open Knowledge Framework (dropped June 12) is markdown + files + front matter to document and query big datasets. One of the biggest players outside Anthropic is doing the markdown-and-files approach we've been practicing here. 👀 🏛️ Plus: mapping a real company's teams in Obsidian, the platform coming so you can own and license your workflows, and a sneak peek at my new paper — Human in the Compute Layer — built on Engelbart's 1962 work. 📎 What's attached (and what each file is for): 📝 session-notes.md — The opinionated version. All the ideas from the call, written so you can act on them. Start here if you want the short version. 📚 term-sheet.md — Plain-English definitions for every term: node, edge, semantic layer, OKF, ICM, "the data becomes the agent," and more. Perfect if you're new to the room. 📄 vault-page.md — The index for the whole package. 🗂️ Package.zip — Everything zipped, ready to add to your AI's memory (Claude, Hermes, OpenAI — whatever you run). 💬 Watch it, grab the files, and drop your questions below — the best ones seed the next Afternoon Tea. So much love. 🫶
0 likes • 1d
@Eytan Levy ah yeah, I would say that you can experiment with a folder that evaluates knowledge based on posterior updating. I am curious how this will work out for you
1 like • 1d
@Eytan Levy to make the knowledge more explicit to AI, you can draw inspiration from Bayesian statistics (posterior updating) as an analogy.
👑
⭐
1d •
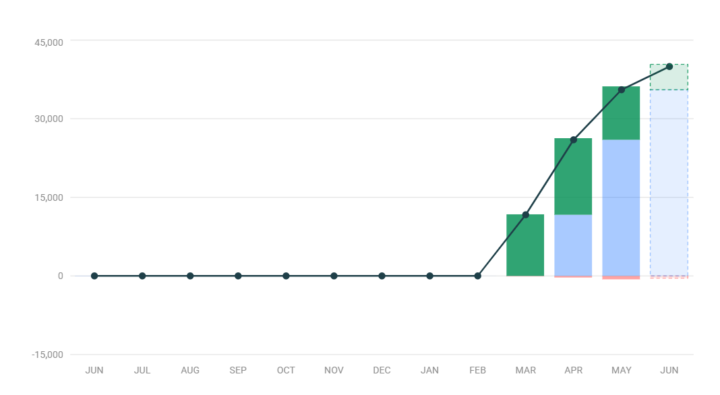
40,000 People....I have only this to say
We just broke 40k Members, in less then 4 months... To say I am honored and blown away is an understatement. I feel like yesterday @Matthew Creamer quit his job to sleep on my floor and bust out 15 hour days to build out content, structure and anything else I thought you all would need to make this community worth it. But at the end of the day there is only one thing for me to say. THANKYOU None of this, and I mean NONE of this would be remotely worth it if it wasn't for you all. To list and tag everyone that have contributed so much valuable not just to this community but to me would be nearly impossible. Thank you to every single one of you. Thank you for commenting and helping out on posts Thank you for sharing the wins you have gotten both at home and professionally. Thank you for believing in me and what I am building septically those of you who have been around since the beginning (you know who you are). I cannot tell you how happy my heart is to get in front of you all and teach, talk, ask questions and even learn a lot myself. It is a dream come true to become someone that people can learn from; to share my thoughts and have those very thoughts change the way people live their lives and do their work. It's only the beginning too, I can't wait to see what the rest of the year has in store, and I promise to keep building, working and recording for you all. From the very very very bottom of my heart.....Thankyou! Thankyou to every single one of you reading this and for being part of such an amazing community.
3 likes • 1d
Thank you Jake. You bring enormous value and you definitely deserve more!
1-3 of 3
Active 49m ago
Joined May 7, 2026
Powered by