Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
67 contributions to AI Automation Society

Jun 2 •
Looking for Beta Testers: AI Sales Training App (Sales Experience Welcome!)
Hey everyone, I've been building a voice AI sales training platform and I'm looking for a handful of beta testers to help me figure out if this is worth pursuing further. What it does: You hop on a live voice call and practice cold calls and pitches against AI personas that respond like real prospects, pushing back, asking hard questions, and keeping you on your toes. After each session you get a scored breakdown of your performance. That's the core of it right now. It's early. Cold calls and pitches are what's live, and I want real feedback from people who actually do this work before building anything else. Who I'm looking for: Anyone with sales experience. SDRs, AEs, founders doing outbound, or anyone actively making calls and pitches. The more real-world reps you've done, the more useful your feedback will be. What you get: - Free access during the beta - Direct input on whether this is something worth building out further If you want in, comment below and I'll reach out to get you set up. No credit card, no fuss. Thanks! Karthik


5 likes • Apr 4
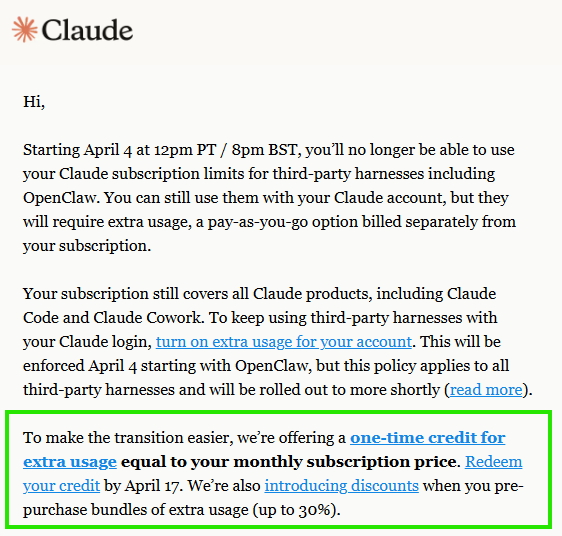
Already switched to openai for usage on openclaw
Mar 30 •
Claude Code just got computer use in the CLI - here's the architecture detail nobody's explaining
Most posts about this are just "wow Claude can control your mouse now." That's not the interesting part. The interesting part is the fallback hierarchy. Claude tries MCP servers first. Then Bash. Then Claude in Chrome. Screen control only activates when all three fail to reach the task. That tells you exactly when and how to use it. The security model is also different from what people assume. Unlike the sandboxed Bash tool, computer use runs on your actual desktop with no filesystem isolation. On-screen prompt injection is a real threat vector, not a hypothetical one. Two more things worth knowing: App approvals reset every single session. That is intentional trust architecture, not a UX bug. Your terminal window is excluded from Claude's screenshots the entire time. It cannot see its own output while controlling your screen. Hard requirements if you want to try it: macOS only, Pro or Max plan, CLI v2.1.85+, and you must authenticate through claude.ai directly. Drop any questions below. Happy to go deeper on any part of this.

1 like • Mar 30
Full LinkedIn breakdown here if you want to save it or share it with your network: https://www.linkedin.com/posts/karthikeyan-rajendran07_claudecode-aitools-buildinpublic-share-7444516807551496192-xxJs
Mar 19 •
The "Vibe Coding" Honeymoon is Over(Here is the New Baseline)
Let’s get real about the latest Google AI Studio update. I spent time tearing down the actual mechanics of what they just released, and 90% of the timeline is completely missing the point by focusing on "better prompting." Here is the actual strategic shift: Google is officially closing the gap between generating a pretty UI and deploying a usable app stack. AI Studio is no longer just a toy for styled components. It is actively provisioning the boring primitives like Firestore, Google Sign-in, secrets handling, and direct deployments to Cloud Run right from the browser. Meanwhile, they are clearly positioning AntiGravity for the heavier, deeper agent workflows. The new baseline is a functional, full-stack prototype in minutes. If you are just generating React components and calling it a day, you are already behind. But a word of warning to the smart builders: Do not fall for the "production-ready" marketing trap. AI gets you velocity, but you still have to be the engineer. You still have to review security rules, validate auth flows, and manage cloud costs. Use the speed. Do not outsource your judgment.

1 like • Mar 19
If this breakdown sharpened your thinking, drop a like or join the conversation on my full LinkedIn deep dive here to help push the signal past the hype: https://www.linkedin.com/posts/karthikeyan-rajendran07_ai-aibuilders-vibecoding-activity-7440528579014320128-o1Vh
Mar 18 •
GPT-5.4 Mini and Nano just dropped
Everyone in the AI space is talking about the new small models from OpenAI. Most people are reading the marketing. I read the benchmarks. Here is what actually changed: Mini went from 42% to 72.1% on OSWorld-Verified. Terminal-Bench jumped from 38.2% to 60%. SWE-Bench Pro moved from 45.7% to 54.4%. That is not a minor upgrade. That changes where you draw the line between your main model and your worker model. Now here is the part most people will miss. The 400k context window is a trap. Mini scores 33.6% on the 128K to 256K long-context needle test. Stuff 200,000 tokens of logs into it and it fails roughly 66% of the time. Context window and context skill are not the same thing. The routing decision is actually straightforward once you see it clearly: Full model handles planning, ambiguity, and final judgment. Mini runs parallel subagents, tool calls, and screenshot-heavy workflows. Nano handles classification, extraction, ranking, and tight JSON tasks only. One hard rule: do not put nano anywhere near UI navigation or computer use. It scores 39% on OSWorld while mini scores 72.1%. The builders who win here will not just swap models. They will redesign routing. Would love to hear how others in this community are thinking about model tiering in their agentic stacks. Drop your current setup below.

0 likes • Mar 18
If it resonates, a like or repost on LinkedIn goes a long way in helping this reach more builders who need it. Here is the post 👇 https://www.linkedin.com/posts/karthikeyan-rajendran07_aiengineering-agenticai-llms-activity-7439870855708524544-Q-Pp
1-10 of 67

@karthikeyan-r-5062
I'm a Software Engineer by profession based in India. I'm trying to learn more about AI Automation and its usages
Active 16h ago
Joined Dec 7, 2024
Powered by