Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Memberships
Future Founders
532 members • Free
Remote Job Accelerator
550 members • Free
JavaScript
303 members • Free
3D ACADEMY
587 members • Free
Architecture Rendering
319 members • Free
GoHighlevel For Entrepreneurs
612 members • Free
VinPreneurs Club
12 members • Free
4 contributions to JavaScript

Sep 24 •
Which Javascript Framework is Best in 2025 ?
There is no single “Best” JavaScript framework; Select Your ideal choice
Poll
12 members have voted

0 likes • Oct 27
Next.js is a framework built on top of React.js. It provides more powerful features and capabilities compared to using React.js on its own
0 likes • Oct 30
I've seen a post yesterday, nowadays many devs prefer TanStack. TanStack is full stack framework based on React.

Oct 22 •
Excited to Grow and Collaborate as a JavaScript Developer
Hey everyone I’m Michael Heck, a passionate front-end developer focused on learning and building with JavaScript, HTML, and CSS. I’m currently improving my skills with React and working on small projects to grow my portfolio. My goals right now: - Strengthen my JavaScript fundamentals - Build and share real-world projects - Connect with other developers and potential clients for freelance work I’m really happy to join this amazing community and looking forward to learning, sharing ideas, and collaborating with you all
1 like • Oct 30
Nice to meet you. To enhance your proficiency in React, it's essential to have a strong understanding of hooks. Much of React's appeal comes from the flexibility and power that hooks provide. Hope to have a good journey here!

Oct 26 •
JSON Is Slowing You Down — Here’s Why Tuples Win
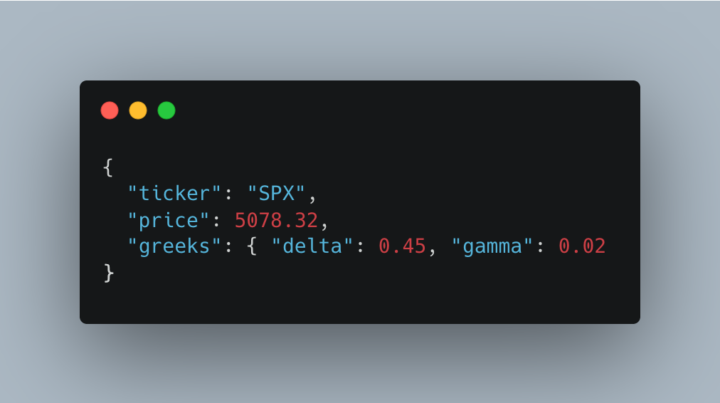
🧩 JSON (JavaScript Object Notation) As JavaScript developers, we love JSON [IMG 1]. It's extremely simple to understand. But JSON is nothing more than just text representing data. That's it...just text. When you parse it, the parser decides what structure it becomes in memory. ⚙️ After Parsing (in memory) When parsed in JS: - JSON objects become plain objects, which then are then implemented much like hashmaps/dictionaries. As I continue to increase the performance of Gextron dot com, I see myself using less and less JSON objects. Here are some weaknesses of JSON and where tuples have an upper advantage: ⚡️ HIGH Frequency Ingest JSON pain: - Every message has to be prased from text into object - Parsing is CPU intensive, especially a lot of strings with a lot of characters - Field names repeat in every record, so wasted bandwidth Imagine doing this – "strike": 505, "delta": 0.95, "gamma": 0.03" – for 4200+ contracts for a single ticker. Tuple win: - Define schema: [strike, delta, gamma] - Then ingest an array of fixed width tuples - No per-field string parsing - Much smaller payload → less network, less garbage collection stress This matters even more when firing a WebSocket provider. 🥵 Hot Path Cache Read JSON pain: - Pull a blob from Redis/DB - JSON.parse() to filter or enrich data - Parse does a full walk of the entire structure, even if you only need 2 fields - Large heap allocation = more GC pauses Tuple wins: - Slice out columns you need without materializing the rest - Index into a field without parsing the whole record - Return to the client as-is or lightly transform This matters when I'm building a full option chain that needs to be served =< 100ms 🚌 Bulk Transport JSON pain: - Repetitive keys in every row - JSON.stringify is very expensive the bigger the object Tuple wins: - Tuples are naturally tight - Sending a matrix of numbers/strings without field names - Compresses extremely well - Faster to serialize
1 like • Oct 30
Great experience!
Oct 23 •
Storing Data Efficiently with JS
As I’m building Gextron, one of the most expensive operations is generating a full option chain. I actually wrote about the bottleneck here: 👉 How Node.js Turns API Bottlenecks Into Instant Data Moving this work to Node workers helped a lot — but there was still another hidden cost: how data was stored. So I completely changed the model of how Redis is used inside Gextron. 🧩 Before — Redis as a Key-Value JSON Cache I was just storing option-chain data as raw JSON strings. [IMG 1] Redis stored this as plain UTF-8 text, which came with heavy costs: - 🔸 Lots of heap allocation - 🔸 CPU-heavy serialization (JSON.stringify / JSON.parse) - 🔸 Huge Redis memory usage (3 – 5 MB per chain) - 🔸 Slow iteration and high GC pressure ⚡ Now — Redis as a Binary Data Store (Columnar Cache) Now the data is serialized into typed arrays (Float32Array, Uint32Array) and packed into one binary block, then Brotli-compressed. [IMG 3] Redis now stores a compact numeric binary snapshot, not text. This change alone brought massive wins: - ⚙️ Pure numbers, no strings - 💾 ~10× smaller payloads (≈ 300 KB vs 3 MB) - 🚀 Fast transfers - ⚡ Decompression 2–4 ms vs 20–40 ms for JSON.parse() 🧠 Lets breakdown a simple analogy: 📚 Bookshelf - JSON: Thousands of loose pages (repeated titles, redundant text) - Columnar: One clean binder with tabbed sections 🧮 CPU Access - JSON: Skims ever page to find a number - Columnar: Reads one tight stack of numbers 📦 Compression - JSON: Random text - Columnar: Predictable patterns (tiny) 🧰 The Takeaway By switching from JSON blobs to binary columnar storage, Redis went from being a text cache to an in-memory analytics engine. These are the same principles behind systems like Parquet and ClickHouse

1 like • Oct 27
awesome, I'd like to get the opportunity to work with you.
1-4 of 4

Active 4h ago
Joined Oct 27, 2025
Powered by