
Write something

2d •
Kind of a nerdy music crossover...
Wanted to share a project I've been working on, more as a component of a larger one but largely a standalone. As an amateur musician, I've been looking for ways of displaying custom chord diagrams inline (for example, in TAB music charts). The `svguitar` library is pretty effective, but it requires a fair knowledge of js to implement it - not really a "plug and play option". So I built the thing. With this, I can `<chord-diagram instrument="Standard Mandolin" chord="Dm7"></chord-diagram>` in the HTML and all the js contained. It includes some logic (lazy logic) to generate chords dynamically, but it also includes a chord editor - and the way I've built it, it looks first for a user override, then a system override, and only if it doesn't find those does it use the dynamic utility. It's a Custom Web Component built with Lit.js, it can be standalone or used as part of a contextual system (so if a user is logged in, there can be a user context). If any of y'all are interested, https://github.com/parent-tobias/chord-component - feel free to beat on it and use it if you have an application for it.

25d •
Centralized logging helps you scale real products
Most engineers obsess over features, UI, or "performance" But here's something nobody talks about, and it's the thing that actually saves you when things go wrong: Centralized logging.... When you're building a serious application. Especially something with multiple services, workers, queues, WebSockets, API layers, etc...there will be errors. That is a guarantee. And here's what happens if you're NOT centralizing your logs: - You only notice errors when users complain - You lose context about where something failed - Each env logs differently - You spend hours digging through random console outputs At scale, this becomes chaos. The Fix: I just implemented this for Gextron system, and it's a huge improvement. - One global initialization - One unified logger across every module - Structured messages (timestamp, context, metadata) - Errors captured with stack traces - Works the same in dev, staging, and prod As your product grows: - More users = more edge cases - More features = more moving parts - More traffic = more concurrency issues - More services = bigger blast radius when something fails If you don't have a centralized logging in place early, the pain compounds fast. Once you do: - Debugging becomes 10x faster - You catch silent failures immediately - You can trace issues across services This is one of the real "grown-up" engineering steps most indie dev skip. Don't skip it.

Oct 30 •
Hey I'm Mahi,
Hi, my name is Anshuman. I live in India and I’m currently pursuing my Master’s degree in Computer Applications (MCA) — I’m in my final year (3rd semester). Along with my studies, I’ve been working as a MERN Stack Developer for the past year. I would love to gain the following three things from this community: 1. 💬 Experiences and insights from developers. 2. ⚠️ Guidance on what mistakes to avoid while growing as a developer. 3. 🚀 Anything that can help me become a better developer than I was yesterday. For fun, I like to do these 3 things: 1. 🎮 Gaming. 2. 🎧 Listening to music . 3. 💻 Building small side projects to practice production-level coding.
Oct 26 •
JSON Is Slowing You Down — Here’s Why Tuples Win
🧩 JSON (JavaScript Object Notation) As JavaScript developers, we love JSON [IMG 1]. It's extremely simple to understand. But JSON is nothing more than just text representing data. That's it...just text. When you parse it, the parser decides what structure it becomes in memory. ⚙️ After Parsing (in memory) When parsed in JS: - JSON objects become plain objects, which then are then implemented much like hashmaps/dictionaries. As I continue to increase the performance of Gextron dot com, I see myself using less and less JSON objects. Here are some weaknesses of JSON and where tuples have an upper advantage: ⚡️ HIGH Frequency Ingest JSON pain: - Every message has to be prased from text into object - Parsing is CPU intensive, especially a lot of strings with a lot of characters - Field names repeat in every record, so wasted bandwidth Imagine doing this – "strike": 505, "delta": 0.95, "gamma": 0.03" – for 4200+ contracts for a single ticker. Tuple win: - Define schema: [strike, delta, gamma] - Then ingest an array of fixed width tuples - No per-field string parsing - Much smaller payload → less network, less garbage collection stress This matters even more when firing a WebSocket provider. 🥵 Hot Path Cache Read JSON pain: - Pull a blob from Redis/DB - JSON.parse() to filter or enrich data - Parse does a full walk of the entire structure, even if you only need 2 fields - Large heap allocation = more GC pauses Tuple wins: - Slice out columns you need without materializing the rest - Index into a field without parsing the whole record - Return to the client as-is or lightly transform This matters when I'm building a full option chain that needs to be served =< 100ms 🚌 Bulk Transport JSON pain: - Repetitive keys in every row - JSON.stringify is very expensive the bigger the object Tuple wins: - Tuples are naturally tight - Sending a matrix of numbers/strings without field names - Compresses extremely well - Faster to serialize
Oct 23 •
Storing Data Efficiently with JS
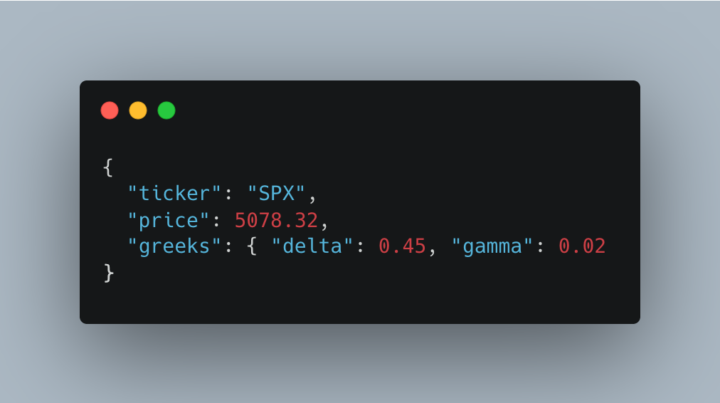
As I’m building Gextron, one of the most expensive operations is generating a full option chain. I actually wrote about the bottleneck here: 👉 How Node.js Turns API Bottlenecks Into Instant Data Moving this work to Node workers helped a lot — but there was still another hidden cost: how data was stored. So I completely changed the model of how Redis is used inside Gextron. 🧩 Before — Redis as a Key-Value JSON Cache I was just storing option-chain data as raw JSON strings. [IMG 1] Redis stored this as plain UTF-8 text, which came with heavy costs: - 🔸 Lots of heap allocation - 🔸 CPU-heavy serialization (JSON.stringify / JSON.parse) - 🔸 Huge Redis memory usage (3 – 5 MB per chain) - 🔸 Slow iteration and high GC pressure ⚡ Now — Redis as a Binary Data Store (Columnar Cache) Now the data is serialized into typed arrays (Float32Array, Uint32Array) and packed into one binary block, then Brotli-compressed. [IMG 3] Redis now stores a compact numeric binary snapshot, not text. This change alone brought massive wins: - ⚙️ Pure numbers, no strings - 💾 ~10× smaller payloads (≈ 300 KB vs 3 MB) - 🚀 Fast transfers - ⚡ Decompression 2–4 ms vs 20–40 ms for JSON.parse() 🧠 Lets breakdown a simple analogy: 📚 Bookshelf - JSON: Thousands of loose pages (repeated titles, redundant text) - Columnar: One clean binder with tabbed sections 🧮 CPU Access - JSON: Skims ever page to find a number - Columnar: Reads one tight stack of numbers 📦 Compression - JSON: Random text - Columnar: Predictable patterns (tiny) 🧰 The Takeaway By switching from JSON blobs to binary columnar storage, Redis went from being a text cache to an in-memory analytics engine. These are the same principles behind systems like Parquet and ClickHouse

1-30 of 38

skool.com/javascript
Chat about javascript and javascript related projects. Yes, typescript counts.
Leaderboard (30-day)
1

+20
2

+6
3
+2
4

+2
5

+2
Powered by