Activity
Mon
Wed
Fri
Sun
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
Jack Vs. AI Workflows
14.1k members • Free
AI Launchpad
32.8k members • Free
Samin's Free AI Resource Hub
19.9k members • Free
Agent Zero
2.7k members • Free
AI Automation Agency Hub
331.1k members • Free
4 contributions to Agent Zero

Jan 22 •
Damn, I'm impressed...
Just finished my first A0 experiment and it's blown me away. Previously I did most of my copywriting using ChatGPT for ideation and Claude (via the web, then with the claude desktop) for the actual copywriting. Most of the time the copy was good, occassionally it was great (I've been writing copy for myself and for others for 15+years and have racked up multiple seven figures in client earnings as a result, so I'd like to think I know good copy when I read it), but at least once in every writing session it would make shit up, wildly hallucinate or just ignore some instructions. I took my best claude writing skill, moved it into A0 and started to write some linkedin pieces. Initially I noticed a few of the same errors but each time I asked for a correction the copy got tighter, the agent did seem to make less obvious mistakes. it took about 45 minutes of corrections, feedback and revisions but asking A0 to create and update an insights.md doc as it went appears to have sped up the learning phase. Really excited to see where how this develops next! And, in case it's not obvious, I am glad I am here :)

0 likes • Jan 26
love to see the insights.md file - the link above goes to an unintended website.
Dec '25 •
Repeated confabulation by A0 - anyone else?
So I'm not a developer, but I spend about 15 hours a week over last year building with agents and have developed some expert system and effective training bots. But for me Agent Zero confabulates more than any other agent platform I've worked with. Is this happening for anyone else? It tells me there's an instance set up on the server of an application and that the testing is all fine when it isn't. It tells me it's working through a scan of selected websites and producing a report when it isn't. It often takes me a lot of prompting to get it to admit that it was simulating a web server monitoring output and it wasn't the actual output. Experimented with a wide range of llms and still getting this problem frequently (or endless loops) including with gpt 4.1, 5.2, Kimmy K2, GLM 4.6. I'm sure it's something to do with me because a lot of very expert users are doing great with Agent zero, so appreciate any tips.
0 likes • Jan 3
@Kiron Keyz thanks, by that you mean break up each step more discreetly ? Just had some success last night that was impressive.

Aug '25 •
research agent most capable
and I want to say the research agent is most defintely the most capable when it it comes to handling multi step reasoning and thinking smart. I usually reference the reasoning loop from that agent when creating new ones as a starting point if I need some super smart thinking. whoever did that research agent prompt....you rock on that one
0 likes • Dec '25
Rafael, is it possible to get a copy of your deep research prompt? I hear folks talking about it on the community call.

Jul '25 •
Agent Zero is a real team member
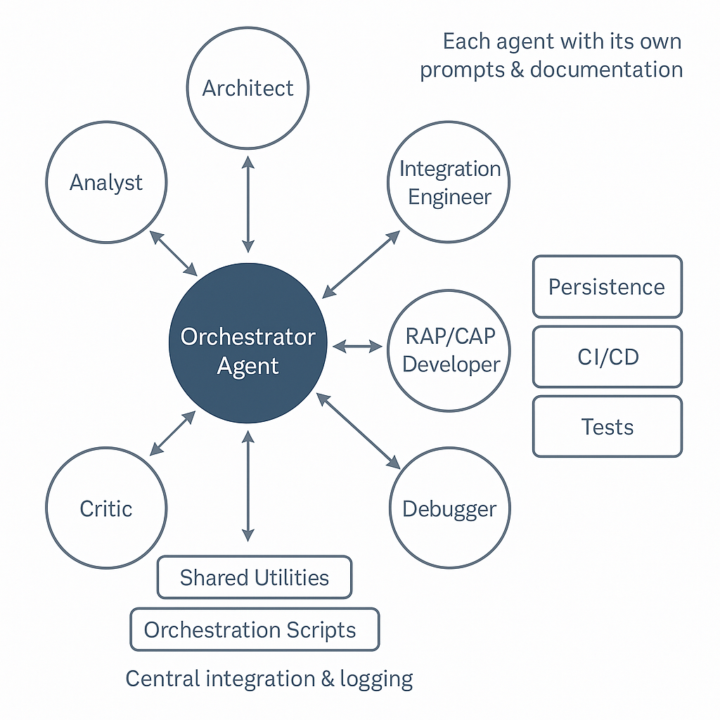
What I would like to make my Agent Zero do, I need help to set up this scenario. One detail is that each sub-agent can use a different Model. Recommended Final Structure of the /a0/agents/ Directory /a0/agents/ ├── shared_utils/ # Shared functions/utilities (templates, helpers, integrations) │ ├── message_template.json │ ├── mongo_integration.txt │ └── README.md ├── orchestrator_agent_zero/ # Main orchestrator (defines central prompts and decision logic) │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── architect/ # Specialist agent for solution architecture │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── integration_engineer/ # Agent for technical integrations (e.g., APIs, middlewares) │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── rap_cap_java_json_developer/ # Specialist agent for CAP/RAP and Java/JSON development │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── tech_lead_expert/ # Tech Lead/Senior agent for technical review and guidance │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── analyst/ # Functional and requirements analyst agent │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── critic/ # Critical agent for QA, review, and quality control │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── debugger/ # Agent for debugging and error resolution │ ├── system_prompt.txt │ ├── user_prompt.txt │ └── README.md ├── orchestration_scripts/ # Central multi-agent orchestration scripts (router, launcher, manager) │ ├── orchestrator.py │ ├── agent_launcher.py │ ├── task_router.py │ ├── communication_manager.py │ ├── logger.py │ ├── shared_utils.py │ └── test_multi_agent_flow.py ├── persistence/ # Abstraction for database integration (MongoDB, etc.) │ └── (relevant scripts/configs) ├── tests/ # Automated unit and multi-agent integration tests ├── ci_cd/ # Continuous integration and delivery pipelines ├── healthcheck.py # Script for system health monitoring and healthcheck
1 like • Aug '25
I would love some guidance on when to use subagents versus just giving A0 a list of sequential tasks - any suggestions on the triggers or thresholds for doing this?
1-4 of 4

Active 3h ago
Joined Aug 6, 2025
Powered by