Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI Video Creators Community
4.4k members • $15/month
AI Creator Bootcamp
2.6k members • $9/month
Clief Notes
38.9k members • Free
AndyNoCode
34.4k members • Free
AI Automation Agency Hub
325.8k members • Free
14 contributions to Clief Notes

7h •
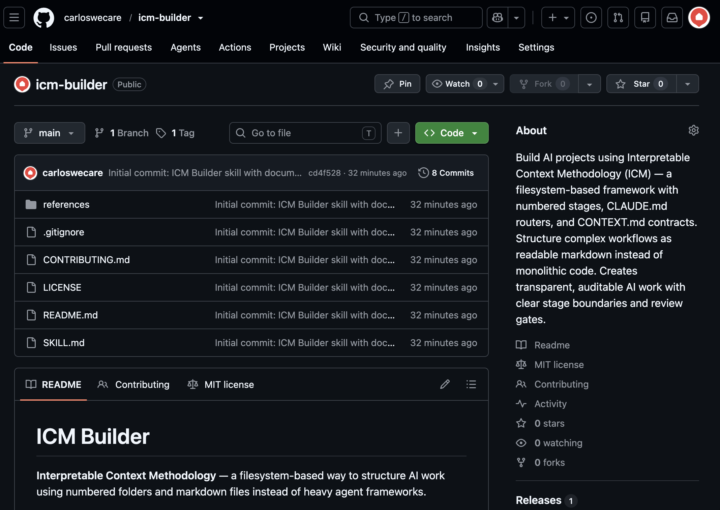
ICM-Builder Skill - link
Hey folks 👋 Packaged an icm-builder skill — helps scaffold projects, generate routing tables, and track what needs updating when you change a contract or reference file across stages. GitHub: https://github.com/carloswecare/icm-builder WARNING: Not a substitute for the courses and fundamentals — just a helper for when you're already building. First attempt, open-sourced on GitHub. Would love PRs, issues, or a "you're solving the wrong problem" if that's the case 😄 — Carlos
1 like • 5h
@Khalid Elbaz I hope that helps! Thanks! What is that you building?
1 like • 4h
@Curtis Hays Thanks so much for taking the time to look through the repo and for the incredibly thoughtful feedback! I agree - Skipping the classroom completely misses the point of the framework. Love the high school Spanish story, too! "Los" is a great nickname. Appreciate the support on my first MIT repo!
5h •
Loop Engineering 🔄 + ICM 📂: Perfect match, or completely different things?
Hey everyone! 👋 I’ve been spending a lot of time thinking about how we build, and Loop Engineering have been popping up lately... I’m really curious to see how you all view the relationship between Loop Engineering and ICM. I’d love to get your quick thoughts on a few fundamental questions: 🤝 Do they naturally intertwine? To me, Loop Engineering is all about how the agent acts—creating autonomous cycles of execution, verification, and self-correction. On the other hand, ICM is about where the agent lives—using transparent folder structures and markdown files to manage context. Do you see them as a natural duo? Does a great autonomous loop need a clean file structure like ICM to keep from losing its mind? 🏗️ Can Loop Engineering be the framework FOR ICM? Instead of looking at them as separate tools, can we use the concept of Loop Engineering as the actual structural framework to drive an ICM workspace? For example, using the agent's looping logic to systematically move files from a 01_inbox to a 02_processing folder? Or do you think keeping the looping logic and the context methodology strictly separate is a better approach? 🤷♂️ Or are they just for completely different use cases? Are we trying to force a connection that shouldn't be there? Do you use Loop Engineering for heavy task automation, but prefer to leave ICM strictly for human-in-the-loop, highly readable research workspaces? 💬 What’s your take? - How do you define the connection between Loop Engineering and ICM? - Are you combining them in your current builds, or keeping them completely separate?

👑
⭐
Mar 2 •
Who's here? Drop your intro.
Tell us three things: 1. What you do (job, industry, student, career-changer, whatever) 2. What brought you to Clief Notes 3. One thing you're trying to figure out right now related to computing or AI I'll respond to every single one. And read each other's intros too because the person who's stuck on the same problem as you might already be in this thread. I'll go first I am Jake, I have been working in tech for 15 Years, building with Generative AI for 3 Years straight now! Excited to teach and learn! That's it. Simple, scannable, gives you data on who's joining and what they need, and keeps the feed clear for content that retains people past week one.
2 likes • 1d
I built ICM-builder skill for Claude! Comment "icm-builder" and I'll send it to you. It helps a lot to create your folder structure , claude.md and all context.md files! It works ! lol
2 likes • 7h
@Dan Bouldin here it is - https://github.com/carloswecare/icm-builder I hope that helps!

Mar 15 •
🏁 Foundations 1.2 Check-In
You built your first folder. Vote below, then drop a screenshot in the comments so we can see what you came up with.
Poll
2039 members have voted
2 likes • 1d
I built ICM-builder skill for Claude! Comment "icm-builder" and I'll send it to you. It helps a lot to create your folder structure , claude.md and all context.md files!
1 like • 7h
@Joshua Trimmell Hey man - here it is: https://github.com/carloswecare/icm-builder I hope that helps!
Mar 15 •
🏁 Foundations 2.4 Check-In
You just learned the book, movie, video game framework. Vote below, then tell us in the comments: name one thing in your work that you now realize is on the wrong layer.
Poll
662 members have voted
1 like • 1d
I built ICM-builder skill for Claude! Comment "icm-builder" and I'll send it to you. It helps a lot to create your folder structure , claude.md and all context.md files!
1 like • 7h
@Abdulrehman Sagheer here it is: https://github.com/carloswecare/icm-builder I hope that helps. I use it to help me think in the structure and also when I ant to update something, it helps to check all the files and references and change it so, it won't brake!
1-10 of 14

@carlos-pecucci-9352
Solopreneur exploring the power of AI to simplify work and spark innovation. Passionate about leveraging automation, data, and creativity!
Active 34m ago
Joined Mar 10, 2026
Powered by