Activity
Mon
Wed
Fri
Sun
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
What is this?
Less
More
Memberships
Tech Snack University
14.2k members • Free
AI Workshop Lite
12.8k members • Free
AI Automation Society
208.5k members • Free
5minAI
2.8k members • Free
AndyNoCode
25.5k members • Free
5 contributions to AI Automation Society

Feb 16 •
How to ACTUALLY Deploy a Voice Agent (Considerations)
After sharing my VAPI build, I’ve had a lot of questions about how to ACTUALLY deploy and manage a VAPI deployment to clients. In this video, I’ve shared the different options and pros- and cons as well as broader considerations when starting and running an AI Agency. Please let me know your thoughts - I tried to edit this MUCH faster as last time it took me a silly amount of time. So again, all feedback very much appreciated to help me improve! 🙂

1 like • Feb 18
Welcome @Jamie Oarton Sure. I don't comment much since I'm not as tech-savvy as most here. Feel free to shout if you have any business, finance or client value-stream-related questions. What's your background?
0 likes • Feb 18
@Jamie Oarton sounds good!

Feb 15 •
Enhancing RAG Search Accuracy with Pre-Processed Contextual Data
I have been using a technique to improve the accuracy of searches in RAG (Retrieval-Augmented Generation). The process works as follows: I receive data in JSON or XML format, and instead of using it directly, I apply a pre-processing step. To achieve this, I use an AI model to transform the raw data into a structured sentence and a logical natural language representation. This significantly enhances accuracy, as traditional semantic search struggles with retrieving disconnected data points. Example: Suppose I have a JSON file with real estate listings: { "id": 12345, "type": "Apartment", "bedrooms": 3, "bathrooms": 2, "size": 120, "city": "São Paulo", "neighborhood": "Vila Mariana", "price": 950000 } The AI processes this data and generates a structured sentence: "Apartment with 120m², featuring 3 bedrooms and 2 bathrooms, located in Vila Mariana, São Paulo, available for R$ 950,000." It also creates a logical representation for precise searches: "A property of type apartment, located in São Paulo, in the Vila Mariana neighborhood, with 3 bedrooms, 2 bathrooms, and a size of 120m², available for sale at R$ 950,000." Why This Technique Works This approach is particularly useful when searching for highly relevant results within RAG. Instead of relying solely on semantic search—which may struggle with loosely structured data—we provide clear contextual information in advance. Once the model returns a relevant result, I can extract the ID of the property (12345). With this ID, I can perform a direct database query, retrieving all the necessary details accurately. This technique significantly enhances search precision, ensures data reliability, and improves the overall effectiveness of AI-powered retrieval systems.
0 likes • Feb 17
@John Batisti This looks very interesting. Do you have an example workflow that I could test the theory?

💎
⭐
Dec '24 •
🚀New Video: The Best RAG System On YouTube
Learn how to create a powerful Retrieval-Augmented Generation (RAG) system using n8n, Supabase, and Postgres. This system automatically uploads documents to your vector database based on file type and seamlessly updates your records whenever changes are made to your files. Perfect for streamlining data management and enhancing your AI knowledge base.
2 likes • Feb 5
@Dave Brong Hi David. Have you managed to integrate elevenlabs or telegram webhook triggers working on Windows? Could you walk me through how please? I've tried so many solutions, but still hitting deadends. Thank you
1 like • Feb 8
@Dave Brong Thank you. I figured this out the hard way! You're bang on the money!
Feb 5 •
Windows webhook trigger problems
Can any savvy n8n WINDOWS users help me get webhook triggers working? I've tried using the npm and docker starterkit routes and just cannot get Elevenlabs or Telegram working with n8n. The n8n webhook triggers are not picking up what these APIs are putting down. I know there are a lot of other windows users squirming around this issue but for some reason, there isn't much info out there! @Nate Herk You could do a video on this, you'd pull a good number of views for sure! Thanks in advance!
1 like • Feb 8
Thank you. I figured this out the hard way! Also learned that the free version of ngrok times you out if you're on the free plan, so it sucks for leaving long batch runs (E.g. scraping) idle.

Jan 27 •
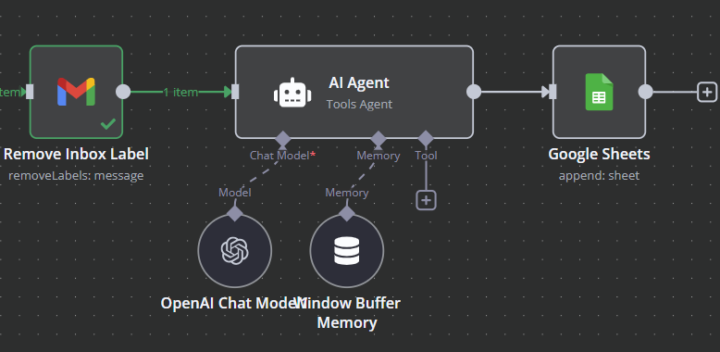
extracting info from gmail and input to google sheet
When I get a warranty registration email, I want chat gpt to extract the information (name, email, product, date) and append it to warranty registration google sheet. This seems like it should be easy, but I'm stuck. Can anyone point me in the right direction or recommend a tutorial? thanks.
0 likes • Feb 2
@Patrick Freeburger Awesome. Can you share a snapshot a json of the workflow. It'd be awesome to see exactly how you extracted the keywords and info and allocated it to the right cells. Thanks in advance!
1 like • Feb 8
@Patrick Freeburger Really intuitive! Thank you!
1-5 of 5

Active 88d ago
Joined Feb 2, 2025
Powered by