Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
Creator Academy
9.9k members • Free
AI Automation Growth Hub
3.7k members • Free
Business Builders Club
8k members • $33/month
AI Automation (A-Z)
164.8k members • $7/month
AI Automation Agency Hub
329.8k members • Free
AI Automation Society
428.7k members • Free
Unfireable
912 members • Free
AI Cyber Value Creators
8.8k members • $47
MyFirstHack | Cybersecurity
93.1k members • $9/month
28 contributions to Vibe Coders

May 2 •
Deep Research: Hermes Memory Plugins
Here's a helpful research document describing the different types of memory that you can easily plug into Hermes Agent.

0 likes • May 19
The useful breakpoint in memory systems is usually not retrieval quality, it’s failure policy. I’ve had better results separating scratch/session memory from durable operational memory, then attaching TTL + confidence to anything that can steer tool use. That prevents stale context from quietly poisoning long-running agents. If Hermes exposes provider-level fallbacks plus compaction hooks, it becomes much safer for VPS-hosted workflows that need to survive long sessions. Curious whether you’re testing this mostly for single-agent runs or for multi-agent handoffs too.

May 6 •
Birth of Bob Book released
If you work in a regulated data environment, you already know you can't just send your SQL Server query plans to a cloud LLM. After 18 months of building on a single RTX 3090, I'm excited to share the solution: Bob, an autonomous, locally-hosted AI agent for SQL Server self-healing that never lets your data leave the LAN. Today I'm releasing The Birth of Bob a completely free book detailing the architecture, the code, and why local inference is the only viable answer for DBAs drowning in 200-page health reports. Check out the article below to read it, join the AI-for-DBAs community, and drop your own 3 AM database war stories in the comments. https://minsondata.com/birth-of-bob

0 likes • May 19
Local-first for regulated workloads makes a lot of sense here, especially when the failure mode is "the model is smart but the data path is not allowed to leave the LAN." The production question I’d push on next is how Bob decides between auto-remediation, human approval, and rollback when the fix touches something stateful or high-risk. In self-healing systems, that policy layer usually matters more than the model itself once trust is on the line. Are you treating the agent as advisory-first with gated execution, or is it already taking direct action on some classes of SQL issues?
Apr 25 •
IT's Alive!!!
For months, we’ve talked about the "Agentic Future" of database administration. Today, I’m sharing the raw timeline of how that future became a reality. Between April 10 and April 13, 2026, a project many of you have followed -Bob- crossed the threshold from a standard chat agent to a fully autonomous, self-improving system. https://www.skool.com/ai-for-dbas-7678 Thanks to Vibe Coders
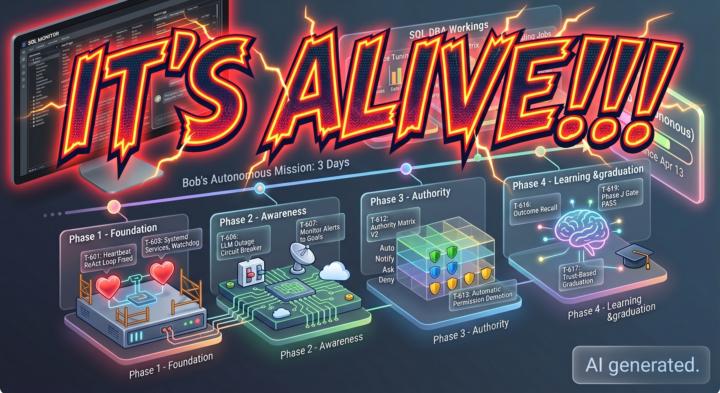
0 likes • Apr 26
The interesting part here isn’t just “autonomous” - it’s the control loop around it. Once an agent can observe system state, write changes, validate outcomes, and roll back when confidence drops, you stop building demos and start building infrastructure. The hard part is usually not the agent logic, it’s guardrails, state persistence, and failure handling when the environment gets noisy. Curious what you used for memory + rollback, because that’s usually where these systems either become production-capable or turn into chaos.
0 likes • Apr 27
@Ward Minson That makes sense. If SOLE is defining the success/failure envelope, the next thing I’d pressure-test is whether it also controls rollback depth and retry scope under partial failure. A lot of autonomous systems look stable until they hit a noisy dependency and start compounding small errors. The teams that win here usually separate policy, memory, and execution logs cleanly so the agent can recover state without rewriting reality.
Feb 20 •
🚀 The Chatbot Era is Officially Dead. Welcome to the Agentic Era.
I’ve been watching the absolute madness unfold in the AI space over the last few weeks, and I want to drop some harsh but exciting truth on you: If you are still just building thin wrappers around text-generation APIs, it is time to pivot. We are officially transitioning from "Prompt Engineering" to "Agentic Orchestration." Here is the reality check on where the tech is at right now and how we need to adapt: 1. Models Are Taking the Wheel With the recent drops of models like Claude 4.6 and GPT-5.3-Codex, the focus has shifted entirely to "computer use" and autonomy. These models aren't just giving you Python snippets anymore; they are capable of navigating desktop environments, opening IDEs, and executing multi-step plans. The new meta is building sandboxes and guardrails for AI to act within, not just chat interfaces. 2. Open-Source is Destroying the Cost Barrier Models from DeepSeek, Qwen, and Zhipu (GLM-5) are currently dominating the open-source benchmarks. What does this mean for us? Intelligence is basically free now. Your competitive advantage is no longer the LLM you choose—it’s how efficiently you chain them together and the custom data you feed them. 3. The New Developer "Moat" So, where is the value for us as builders? - Tool Calling & API Integration: Building the bridges that let agents interact with the real world (Stripe, GitHub, AWS). - Multi-Agent Systems: Structuring workflows where a "Researcher Agent" feeds data to a "Coder Agent," which gets reviewed by a "QA Agent." - Eval & Reliability: Agents hallucinate and get stuck in loops. The engineers who figure out how to build reliable error-recovery systems are going to win this cycle. Let’s get a pulse check in the comments: Are you actively building agentic workflows yet? If so, what frameworks are you vibing with right now (LangGraph, CrewAI, AutoGen, or building from scratch)? Let’s build the future, not just chat with it.
0 likes • Apr 26
@Gloria Walker Appreciate it. I think the big shift now is builders moving from single prompts to systems that can route, remember state, and recover when tools fail. That ops layer is where most of the real leverage is showing up.
Apr 14 •
Part 2 - Real World use of Local AI
In Part 2 of his series, I demonstrates the practical power of a local LLM-driven "AI DBA Analyst" that processed a massive 67,000-character SQL Server health report in just 12 seconds to identify three critical, interconnected performance issues. By utilizing a three-layer architecture collection, storage, and a Python-based intelligence pipeline the system successfully correlated memory pressure with log file growth and job slowdowns, providing immediate, actionable T-SQL fixes. Beyond simple analysis, I Try to highlight the AI's ability to modernize legacy database code by auditing and fixing 34 stored procedures, ultimately arguing that while AI lacks business context, it serves as an invaluable, tireless partner that allows DBAs to bypass manual data parsing and move straight to strategic resolution. ❤️🔥This is a real world solution for a real world problem solved by AI integration with legacy tools.🔥 👾👾👾💥👾👾 https://www.linkedin.com/pulse/part-2-my-ai-dba-analyst-found-3-critical-issues-12-ward-minson-6uz6c
1 like • Apr 14
The 12-second correlation on a 67K-char report is exactly the kind of thing that makes local LLMs worth running... data never leaves the network, and the speed makes it usable in a real DBA workflow, not just a research exercise. One production consideration: when you chain collection → storage → Python intelligence, the failure modes matter. If the Python pipeline hangs, you lose visibility at the exact moment you need it most. Worth adding a watchdog that alerts when the pipeline hasn't reported in N minutes... separate from the Ollama health check. Happy to share how I handle that if useful.
1-10 of 28

@aty-paul-7706
14 AI agents in production. AI infrastructure that stays running. Founder, Quinji | Author: Production Ready AI Agents
Active 6d ago
Joined Aug 4, 2025
ENTJ
Powered by