Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
9 contributions to Open Source Voice AI Community

Feb 16 •
NVidia PersonaPlex?
Has anyone integrated or created an agent on this yet? I would LOVE to test it out..

0 likes • Feb 17
See attached.

Feb 10 •
Llama 4 Scout
Got my adventure with LiveKit underway last week. After testing @John George 's demo, my demo felt underwhelming. I tried the Gemini Live API but my agent still felt sluggish and the data supported that. I tried switching out different TTS provides and voices the day before so yesterday, I focused on LLMs. I found Llama 4 Scout, installed with the Groq API. Admittedly, I only made one call but what a difference! A lot more testing to do, but finally, there hope on the horizon. Latency is such a killer. (those Cal.com tool calls still take forever). Anyone any thoughts on this Llama 4 Scout?
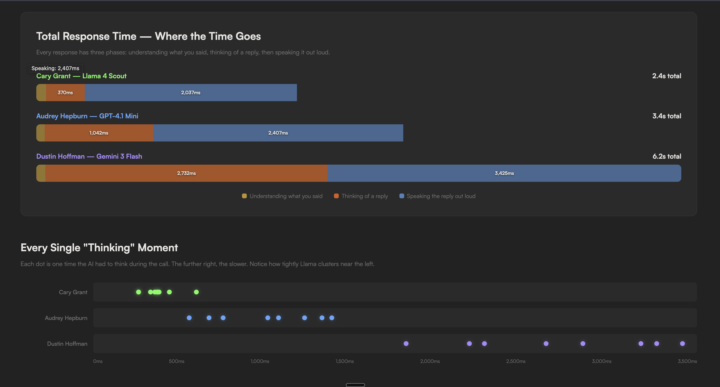
2 likes • Feb 10
@Dan Quixote glad it helped. On the caching, what's the refresh logic there? Do you do an uncached check if a booking attempt fails? Fair enough if so. Without caching it's an edge case where two people call at the same time and request the same slot (usually the next available) and one secures it first.
2 likes • Feb 10
@Dan Quixote you're welcome. And thank you too since you gave me a nice idea for a local caching service/proxy I can use for something else I'm building 🫡
Feb 5 •
Open-sourced my site's voice AI demo
I built a voice AI assistant for my website using Pipecat and Gemini's native audio model. People kept calling it trying to reverse-engineer how it works, so I just open-sourced the whole thing. It's a good starting point if you want to build your own web-based voice AI demo with low latency and multilingual support. Repo: https://github.com/askjohngeorge/askjg-demo-gemini-pcc System prompt: https://github.com/askjohngeorge/askjg-demo-gemini-pcc/blob/main/bot/prompts/demo_system_prompt.md You can try the live demo at https://askjohngeorge.com/demo (click the mic). Happy to answer questions if you have any.
1 like • Feb 5
@Dan Quixote appreciate the kind words. What's wild is that since I've open-sourced this a lot more developers have called it to test out its capabilities, and through that I learned of a couple of things the model can do I didn't know about: 1. It can whisper 2. It can rap "like Kevin Gates" 😂
1 like • Feb 5
@Dan Quixote I had to Google him too! Just listened to the recording. Oasis was my favourite band growing up :)

4 likes • Jan 17
Give this one a go if you want to try Gemini Live tuned for being a snappy demo: https://askjohngeorge.com/demo Built with Pipecat and hosted on Pipecat Cloud.
0 likes • Jan 18
@Nour aka Sanava thank you 🙏 Fully vibe coded it chatting to Claude Code over the xmas holidays 😁

Dec '25 •
Why Livekit Cloud, when I can just use Livekit Open source with Speech to Speech models and wont be restricted by concurrency
Hi everyone, why do i need livekit cloud, when I can just use speech to speech models like Open-AI-Realtime-mini and livekit open source. This would save like crazy because then I am not limited by concurrency limits. Best
0 likes • Dec '25
What's your autoscaling plan for the workers?
3 likes • Dec '25
I'm more referring to the process management side of the speech-to-speech pipeline. Even without local GPU inference, every active call requires a persistent Python worker to bridge the WebRTC stream to OpenAI's WebSocket. If you just use standard EC2 autoscaling, how are you handling scale-in events? When AWS spins down an instance to save costs, it will kill the process, which means dropping active calls mid-sentence. You'd need custom lifecycle hooks to implement connection draining so the server waits for the call to finish before terminating. LiveKit Cloud (or a custom K8s operator) handles that stateful orchestration. Raw EC2 autoscaling groups don't afaik.
1-9 of 9

Active 8h ago
Joined Nov 8, 2025
United Kingdom