Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Clief Notes
40k members • Free
84 contributions to Clief Notes

👑
⭐
11d •
WEEK 7 COMP⚙️ THE OPERATOR — RESULTS
(and a small change to how we run these) Hello everyone!! 👋 First, the honest bit. This one is landing later than Monday, and on purpose. Two things got us here. One, a lot more of you are submitting now. If I am going to really sit with every entry and give it a proper look, a weekend is not enough. This round I went through all of them, watched the videos, opened the repos, the full pass. That takes time and I would rather do it right than rush it. Two, I could feel a few of you running hot. Weekly is a sprint, and burnout was starting to creep in for some. So we are moving to bi-weekly. More room to build, more room to breathe, and the time for me to actually review the work the way it deserves. 🎥 Quick word on the videos. They were a step up this round. Some of the animated walkthroughs and live demos were a genuine pleasure to watch, and yes, I weigh them. A clean demo that shows the thing actually working makes a real difference. However I don't want that to ALWAYS be a requirement. Also you will notice the Heavy hitters that you usually see up here are not currently, some posted late and I decided to let the new entries and first timers also have a chance as well! But certainly, check the original post as every submission has something for you to learn from : 💰 Competition 7 ➖➖➖ 🛠️ A FEW THAT STOOD OUT (in no order, and if you didn't make it, it doesn't mean yours wasn't great) The Pipeline Operator — @Jayden Forshee Runs a whole sales pipeline. Paste a lead and it grades it, writes the outreach, and moves the card itself. The live board where you watch cards move on their own, sat right next to a normal chatbot, was one of the clearest ways anyone has shown what an operator actually is. https://github.com/griffainai/studio-pipeline-operator Board: https://pipeline-operator.vercel.app/board

0 likes • 10d
Congratulations to everyone that stepped up again and created their fourth/fifth build in the competitions. Moving to bi-weekly will create more room for judges but it will also add a lot of "fluff" around a build. Like a stunning video and detailed webpages on how to use it. Those are great but I'm here to build stuff that works. The Porter application took me under an hour to build. A few hours more for fine-tuning, testing and using it myself before it went public. I use it every day and it helps a lot in my real work. Bi-weekly isn't the answer for better builds. A great idea can be materialized in a few hours. With this community we could shave and polish it to an excellent idea within a day. The ASTRID project management took a bit more time but this week I had the first session with a colleague that wants the system too. It will be company wide in a few weeks. If you didn't participate in the competitions yet: see it as a chance to get your AI production lab up and running. You need the agency (week 4) with a brand voice (week 1) and put a specialist (week 3) in there. Maybe even the coach (week 5) and reseacher (week 6) for some special stuff. And then the operator (week 7) and most of it will run without you. And then you can deliver products (like week 2 requested) in no time.
0 likes • 4d
@Ivan Soto hopefully more inspiring than anything 😁 for the specialist competition I built a specialist that helps build specialists.. and I have a skill that helps me set up a new work process using the ICM standards. Once you have some of these basics working you are no longer intimidated but empowered. Let me know how it works out for you

11d •
How are you handling team collaboration in an ICM workspace?
I just came out of a conversation with the CEO of a startup in Madrid. My goal was to explain ICM and understand both the problems it could solve and the new friction it might introduce. The first obstacle was file collaboration. Their team works in Google Drive and is used to editing Docs, Sheets, and Slides together in real time. An ICM workspace, however, moves much of the operating context into the filesystem through Markdown and other structured files. That works well for agent readability, portability, and version control, but it is a significant change for a non-technical team accustomed to Google Workspace. How are you handling this in practice? - Do you use Git and a shared editor? - Do you sync the ICM workspace through Google Drive? - Do you keep Google Workspace as the collaboration layer and move approved material into ICM? - Have you found another setup that works better for non-technical teams? I am particularly interested in how you define the source of truth and prevent conflicts between a live Google file and its ICM counterpart.
2 likes • 11d
Use git.. that's production ready for handling versions of files and doesn't collapse when there is a difference between several people I use it in ASTRID (project management) even when it runs on local computers and syncs the status to a shared drive
1 like • 10d
if you give them agents to work with, AI assisted work processes i mean.. then they won't even notice it. It's built in the engine.

13d •
Your AI doesn't read. It finds the paragraph and bluffs the rest.
Search finds. It never reads. Every "AI that knows your stuff" runs the same trick: embed the material, grab the paragraph nearest your question, bluff the rest. For easy questions the bluff holds. For the ones that matter, it doesn't. So I'm building the missing layer. Call it a reading swarm. Instead of paying one expensive model to read a whole mountain, I cut the corpus into slices and send a swarm of cheap workers, one per slice. Each reads its slice properly and hands back a single finding. A deterministic harness merges them into one verdict. The expensive model only steps in if I ask it to sharpen the final call. Not shipped yet. Still smoke-testing the edges, and I read every verdict myself. But the law already holds: finding isn't comprehending, and comprehension doesn't need a bigger brain. It needs more cheap eyes, one slice each. What's the biggest pile of material you wish your AI actually read, not skimmed? //A<3
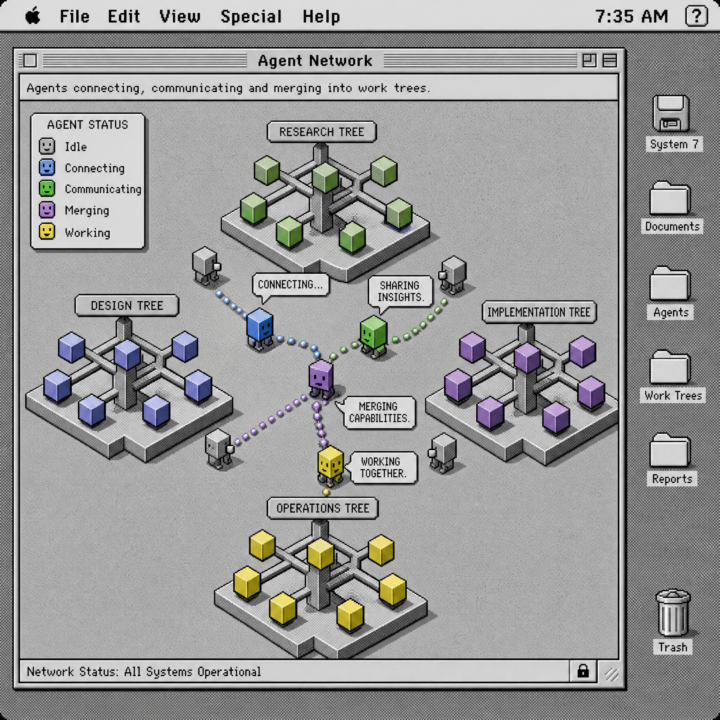
0 likes • 11d
I love the approach. Is it like one agent let's different agents read all the markdown and communicates with them when you ask the main agent a question? So when one agent finds something really helpful it will send it to the orchestrator which signals it needs to go in that direction? It could potentially solve the whole problem where we defined it but the agent was too economical to really find it. Very curious to the results and research!
0 likes • 10d
Love the idea and thinking how to actually use it. One Opus orchestrator spawns Haiku agents that read all of the markdown and are available to the Opus orchestrator? Can you explain it in more detail?
19d •
ICM on enterprise level - introducing Taurus
Folders, not frameworks: how Taurus makes Claude repeatable for a whole team Giving an AI agent the right context at the right moment is still the hardest part of using coding agents like Claude Code in real, daily work. We've all felt it: the agent is brilliant when it knows where it is, and frustrating when it doesn't. So how do you give it that context — reliably, for more than one person? A small team will work but what happens when you try to on-board 100+ people? The popular answers don't scale. Elaborate memory systems help a single power user, but in an enterprise they become a liability: they're hard to curate, easy to pollute, and brittle the moment you add more people and more projects. And anything built around one person's bespoke setup — their servers, their wiring, their mental model — is expensive to onboard a whole team onto. Honestly, the wheel hasn't been invented yet. Nobody has a clean, proven answer for how context should work at enterprise scale. This is where the Interpreted Context Methodology (ICM) changes the conversation. Its core idea is deceptively simple: folder structure as agent architecture. Instead of orchestration code or a sprawling memory store, the context lives in the folders themselves. A workspace is just numbered folders for each stage, with markdown files (CLAUDE.md, conventions, reference material, working artifacts) that load in layers when an agent starts there. The agent reads downward and stops when it has enough — typically 2–8k tokens instead of 30–50k. You "configure the factory, not the product": set the workspace up once, then every run reuses it with new inputs. Outputs are plain text, editable, reviewable at every step. ICM is elegant because it's filesystem-native and human-readable — a non-developer can reshape a workflow by moving files. But it has one practical dependency that's easy to overlook: When you add more and more folders agents begin to skip information. Guidelines are missed, rules are overlooked. What worked for one person doesn't work for another because the model scans economically and thinks it knows enough. The solution is again simple, the agent has to actually start in the right folder. Start in a central place and the layered context never loads; start in the right place and the agent is instantly grounded. In a team, "just cd to the correct directory" is exactly the kind of invisible, error-prone step that breaks repeatability.
0 likes • 16d
@Jake Van Clief let's do that! I'm trying to spark community builds with everything I release here so maybe this is the one? 🤗
1 like • 13d
Taurus — what's new A round of updates focused on getting links, paths, and folders to "just work," plus a bit of polish. - External links open from the HTML preview Click a link to any web page inside a generated dashboard or report, and it now opens cleanly in your default browser. Previously nothing happened — the preview runs in a locked-down sandbox that blocked it. Taurus now catches the click and opens the link from the main window, without loosening the sandbox, so it stays safe for any previewed page. - Launch an agent in any folder The start screen has a new "Browse for a folder…" button: pick any folder on disk and start an agent in it right away — handy for one-off work, with no need to save it as a project first. Folders that contain a CLAUDE.md are preferred; if there isn't one, you get a gentle hint but can still go ahead. - Clickable paths that open the right file When an agent prints a long file path that wraps across two terminal lines, Taurus used to open the wrong (truncated) path and show a "cannot find path specified" error. It now reassembles the full path first, so clicking always opens the correct file in the preview. - Polish The version number now sits discreetly at the bottom of the sidebar — selectable and copyable, handy if you ever need to report something. The project also carries a proper description under the hood instead of the template default. --- In short: external links open, any folder can be a starting point, file paths are reliably clickable, and the version is always in view. --- See https://github.com/astetic-dev/taurus

15d •
Hmmmm this sounds very familiar…
Google’s version if ICM? The **Open Knowledge Format (OKF)** is an open, vendor-neutral specification designed to standardize how context, metadata, and curated knowledge are stored and shared between humans and AI agents. Introduced by the Google Cloud Data Cloud team in June 2026, OKF formalizes the emerging **"LLM-wiki" pattern** (popularized by AI researcher Andrej Karpathy) into a portable, interoperable format. Instead of forcing AI agents to repeatedly search massive, disconnected text files or query proprietary vendor catalogs, OKF provides a shared standard for a living knowledge base. ### Core Technical Structure The technical shape of an OKF "bundle" is intentionally minimal and lightweight. If you have ever used tools like Obsidian, Notion, or static site generators like Hugo, the structure will look highly familiar: * **File System as Identity:** An OKF bundle is simply a directory tree of standard Markdown (.md) files. Each file represents a single unit of knowledge—called a **Concept**—which can be a physical asset (like a database table or API endpoint) or an abstract idea (like a business metric or an incident playbook). * **YAML Frontmatter:** Every Markdown file begins with a snippet of YAML configuration metadata. * **Minimal Schema Constraints:** To maintain ultimate flexibility, the specification enforces only **one** required field in the frontmatter: type. Other highly recommended (but optional) fields include title, description, resource (a unique URI pointing to the underlying asset), tags, and timestamp (ISO 8601). * **Graph via Hyperlinks:** Concepts are linked together using standard Markdown links ([Link Text](path/to/file.md)). This effectively turns a flat folder structure into a rich graph of untyped, directed relationships (e.g., *parent/child*, *depends-on*, *joins-with*). Broken links are explicitly permitted to represent knowledge gaps that haven't been written yet. ### The 3 Core Design Principles
0 likes • 15d
@David Vogel LLMs need structure beyond the workflow description. If you just state what the input and output should be (json file or in OKF) performance is much better, always reproducable output that only varies in what the fields actually contain. See my post earlier about this https://www.skool.com/cliefnotes/the-fluid-ui-why-the-future-of-ai-is-personal-not-standardized?utm_source=skooldotcom&utm_campaign=user_profile_page
0 likes • 14d
@David Vogel just the json .. it's structure enough to get deterministic results.. or at least something the next process can handle
1-10 of 84

@arjen-stet-6395
It's better not to define much as most of it is transient
Active 4d ago
Joined Mar 9, 2026
Haarlem, Netherlands
Powered by