Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
AI Automation Club
870 members • Free
Clief Notes
42.1k members • Free
New Era Sales - Chris Rigoudis
1k members • Free
AI Automation Society
425.7k members • Free
108 contributions to AI Automation Society

19h •
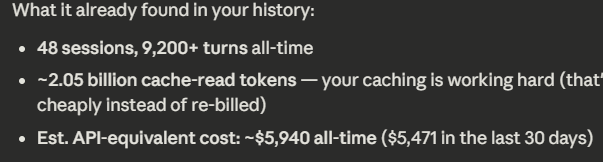
Maybe I should start being a bit more optimized
$500 spend on claude vs $6,000 claude spent on me... gives me a fresh perspective on things. Very grateful for Claude. Thank you!!
0 likes • 8h
@Ahmad Khan Kapathy Wiki + one of my very first builds that I iterated that I call my "Advisors" basically I have "Alex Hormozi" "Nate Herk" ect. advisors who are "trained" on all of their works and youtube vids. that then my sessions with claude reference and use for expert advice and guidance
1 like • 8h
@Nastasja Terry https://github.com/nateherkai/token-dashboard.git
13h •
I am the exact opposite of every single advice
That is why it is my background picture now. So I do not forget. Alex is making the perfect face for me and for you.
0 likes • 8h
@Ashley Nicole
0 likes • 8h
@Ahmad Khan
9d •
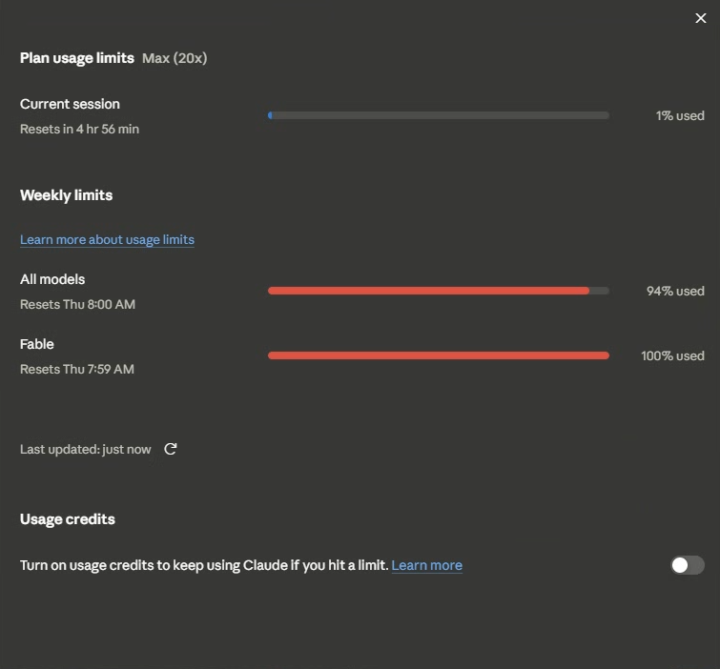
Do I turn on usage credit? Anyone know how much it's gonna cost me??
I can not believe I just maxed out the $200 Max plan... 🥲 I need to continue the builds and I wanted to try hyperframes today, I cannot believe I maxed out... Any advice?
0 likes • 19h
@Dawid Potgieter I have been a bit loosy goosey lately, I need to be a bit more structured like I used to be. one things that gets me is I technically should already have a bunch of parameters and instructions for making sure my usage is clean and lean. I already have my AIOS auditing and making sure it is using cheap workers where it should. I have been sometimes just impatient and letting go of past hygienic practices that should have been keeping my token usage to a minimum.

9d •
🚨🚨🚨We're extending access to Claude Fable 5 on all paid plans through July 12.🚨🚨🚨
As before, you can use up to 50% of your weekly usage limit on Claude Fable 5. After that, you can keep using Fable 5 with usage credits, or switch to another model to keep working within your remaining limits. https://support.claude.com/en/articles/15424964-claude-fable-5-promotional-access

3 likes • 9d
[attachment]
3 likes • 9d
[attachment]

9d •
Is AI becoming too easy?
My background is in web dev and i'm feeling like AI has progressed so much that and its becoming so easy that people don't see the value in actual developers anymore or even more recently, don't understand the value in having someone handle their AI needs for them. They can just have their assistant or secretary or nephew set things up without much effort or knowledge. Don't get me wrong, I feel like my past skills have helped me quite a bit and still do, especially when I need to tell AI what it is doing wrong in code somewhere. But eventually the AI would have figured it out. I know right now (this week haha) it can still be a bit complicated to set up some systems, which adds value to our skills, but in not too long, anyone will be able to just ask and AI will put all the parts together and create literally anything. How are you all justifying your importance and your value in AI when almost anyone can now do what you do?
0 likes • 9d
The human condition justifies your importance. The vast majority of people will still be afraid/lazy to touch or use ai, or just downright stand on principle to not learn to use ai. When in fact you are correct it already IS too easy to use. Yet most people will still fall behind and continue to use horse drawn carriages in the age of jet fuel and rockets. While this fear and doubt of the significance in our current skills and knowledge is a real hurdle to get over, rest assured your do have real value to provide those who want your expertise. It is just a matter of letting them know that you exist.
1-10 of 108

Active 8h ago
Joined Nov 19, 2025
Powered by