Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
KHOA AI-Ứng Dụng AI Thực Chiến
606 members • Free
AI VIDEO AFFILIATE
510 members • Free
AI Work System Design
337 members • Free
AI Applied Community
288 members • Free
MMO For Freedom
223 members • Free
PieLikeClaw
98 members • Free
AI Automation Mastery
30k members • Free
useful AI
22.6k members • Free
AI Automation Agency Hub
327.8k members • Free
9 contributions to AI Automation Society

2h •
#7dayAISChallenge - Day 4 (Completed)
Deployed first automation on Trigger.dev 🎉 1. What you deployed - Built a simple automation that will send top trending searches in RSS every morning to me and my partner along with the related 3 news article links. (We both rarely watch News, haha) 2. What it broke - mostly the formatting of email. Ooh and because I didn't plan well, it deployed the draft version to production directly the very first time. Soo much to learn and build using claude code, looking forward to Day 5! 🥰
3d •
#7dayAISChallenge - Day 3
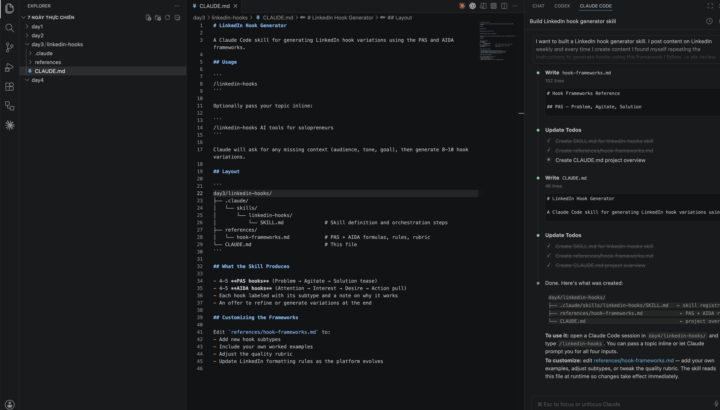
Built /linkedin-hook skill So finally completed day 3 of the 7 Day AIS challenge where I built a LinkedIn hook generator skill. I post content on LinkedIn weekly and every time I create content I found myself repeating the instructions to generate hooks using the framework I follow. I thought it would be a great use case to put it inside a skill and just call the skill every time I need to generate a hook.
3d •
#7dayAISChallenge - Day 2
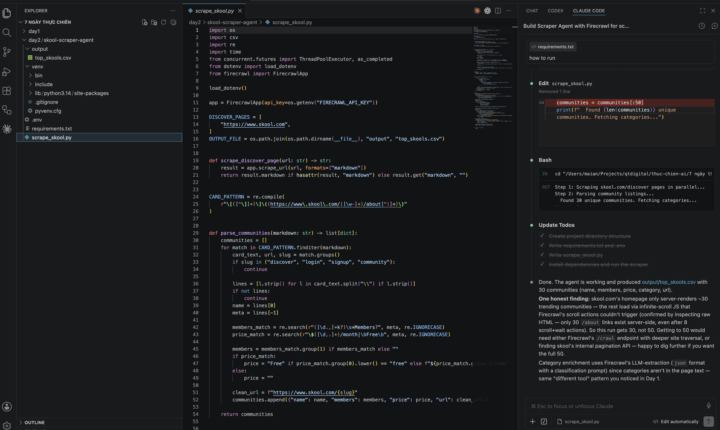
1. What you scraped -> Top 50 Skools and got a structured CSV 2. One thing I learned: When scraping skool.com, I asked Claude Code to also get the category of each community — but that info isn't on the listing page. Instead of giving up or hallucinating, it automatically switched to a different Firecrawl format (json with an LLM classification prompt) to visit each community's /about page and infer the category using AI. It chose the right tool for the right job without being told — that's the "agent thinking" moment that surprised me. 1. One use case idea: Website audit agent for clients. Many business owners don't know if their website looks outdated — old fonts, expired copyright year, slow tech stack, broken links. Build a scraper agent that takes a list of competitor or prospect URLs, visits each site, and returns a structured report scoring: design freshness, copyright year, tech stack age, mobile responsiveness signals, and CTA clarity. Sell it as a "digital health check" to agencies or run it yourself as a lead gen tool (scrape local business sites → flag the worst ones → cold outreach with a ready-made audit report). Looking forward to completing Day 3.
4d •
#7dayAISChallenge - Day 1
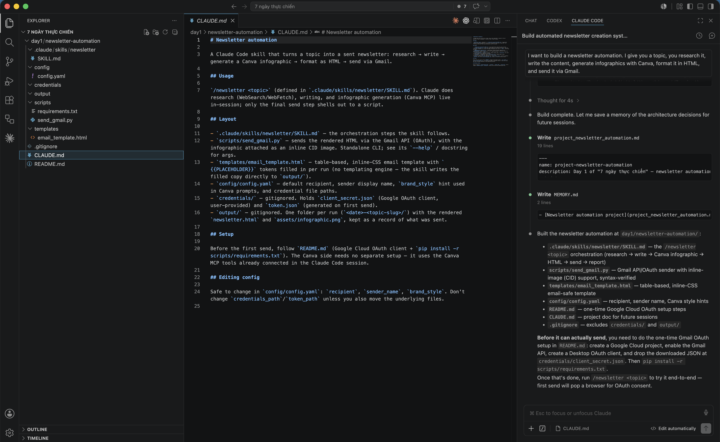
Built Newsletter Automation What I built: A /newsletter Claude Code skill — give it a topic, it researches it, writes the content, generates a Canva infographic, formats an HTML email, and sends it via Gmail (OAuth). One thing that clicked: Splitting the pipeline so Claude does the "judgment" steps (research, writing, picking the infographic angle) live in-session, and only the mechanical Gmail send goes through a script — kept the whole thing inside one skill instead of a separate brittle automation.🥰 Looking forward to completing Day 2. Thanks Nate for putting this together!

💎
⭐
Oct '24 •
Welcome! Introduce yourself + share a career goal you have 🎉
Let's get to know each other! Comment below sharing where you are in the world, a career goal you have, and something you like to do for fun. 😊
3 likes • 4d
@Sonney B welcome
1 like • 4d
@Bruno Clicque welcome 😄
1-9 of 9

Active 2h ago
Joined Sep 15, 2025
Powered by