Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Prime Tech Academy USA
257 members • Free
MB USA Academy
861 members • Free
33 contributions to MB USA Academy

Mar 6 •
الأسبوع الثالث
سبوع ثالث مليء بالتحديات الحقيقية والانتقال من بيئة التعلم إلى بيئة "الإنتاج الفعلي"! 💪🚀 فخور جداً بإتمام مهام الأسبوع الثالث من برنامجي التدريبي، والذي توجته بتطوير وإطلاق نظام "مواكب المحاسبي". في هذا الأسبوع، ركزت على بناء حلول جذرية تخدم العميل النهائي مباشرة، وأنجزت المهام التالية: ✅ بناء تطبيق جاهز للإنتاج (Production-Ready App): تطوير "مواكب المحاسبي" ليكون نظاماً متكاملاً، مستقراً، وقابلاً للاعتماد عليه في بيئة العمل الحقيقية. ✅ بناء مشروع أتمتة مخصص للعميل: هندسة مسار أتمتة ذكي باستخدام n8n يربط التطبيق بـ Telegram. النتيجة؟ يمكن للعميل الآن تسجيل عملياته المحاسبية بمرونة تامة عبر رسالة نصية من هاتفه في أي وقت ومكان، دون الحاجة لأي خلفية محاسبية! ✅ مراجعة وتحسين الكود (Code Review & Refactoring): التدقيق في جودة الكود وتحسينه لضمان الأداء العالي، الاستقرار، وسهولة التوسع مستقبلاً. ✅ تقديم وتوثيق الحل (Solution Documentation): لأن الكود الجيد يحتاج لتوثيق ممتاز؛ قمت بتوثيق المشروع بالكامل وأقدمه كحل تقني احترافي ومستدام . .. اكتشفت في هذا الأسبوع أن القوة الحقيقية تكمن في الدمج بين البرمجة (Programming) والأتمتة (Automation)؛ فنحن لا نكتب أكواداً فحسب، بل نصنع "حلولاً ذكية" توفر الجهد، تكسر الحواجز التقنية، وتصنع أثراً ملموساً في حياة المستخدمين .


0 likes • Mar 9
ماشاء الله تبارك الله 🤩
Mar 6 •
الإسبوع الثاني
بفضل الله، أتممت تحديات الأسبوع الثاني بنجاح، وتوجت هذا الجهد بتطوير منظومة NeuroBridge 🧠✨ — وهي منصة تقنية متكاملة تهدف لرفع معدل التركيز لدى أطفال التوحد. لضمان تقديم أفضل تجربة، لم أكتفِ بتطبيق واحد، بل قمت بهندسة وربط 3 تطبيقات مختلفة تعمل بتناغم تام: 📱 تطبيق الطفل: بيئة لعب تفاعلية مصممة خصيصاً لجذب انتباههم ورفع تركيزهم. 📊 تطبيق الأسرة: لوحة متابعة حية تتيح للأهل رؤية تطور أداء طفلهم بالأرقام. 🔒 تطبيق الإدارة: نظام خلفي مخفي ومحمي بالكامل لإدارة المنصة والبيانات. التطبيق الشامل👌 ⚙️ ما وراء الكواليس (المهام التقنية المنجزة): ✅ بناء النظام وتطويره بالكامل (Full-Stack). ✅ دمج قواعد البيانات لضمان حفظ واسترجاع بيانات الأطفال بدقة. ✅ هندسة التكامل (Integration) لربط التطبيقات الثلاثة لتتحدث معاً في الوقت الفعلي. ✅ إعداد أنظمة المصادقة (Authentication) لضمان خصوصية بيانات الأسر. ✅ تتبع الأخطاء البرمجية في التكامل وإصلاحها (Debugging & Automation). البرمجة تصبح ذات طعم مختلف تماماً عندما نستخدمها لحل مشكلة إنسانية حقيقية وترك أثر ملموس. فخور جداً بما تحقق في NeuroBridge، !

1 like • Mar 9
مميز ك عادتك باشمهندس🤩
Feb 25 •
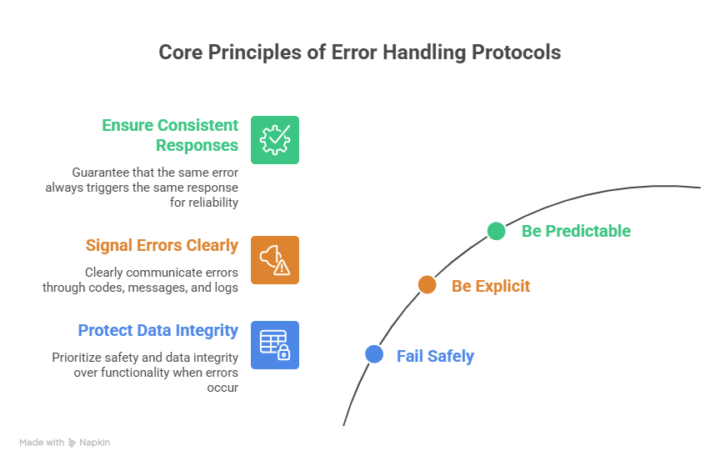
Week 2: Task 6 (Error handling protocols)
Error handling protocols are the agreed rules and workflows an organization or system follows to detect errors, classify them, respond safely, and learn from them so they don’t recur. What error handling protocols are Error handling protocols formally define what counts as an error, how it is detected (monitoring, validations, exceptions), who is notified, and how the system and people should react. They apply both at the technical level (e.g., API returning correct status codes) and the organizational level (e.g., incident playbooks, escalation paths). Core principles - Fail safely: When something goes wrong, protect data integrity and safety first, even if that means degrading or temporarily disabling functionality. - Be explicit: Errors should be clearly signaled (codes, messages, logs), not silently ignored or hidden. - Be predictable: The same type of error should trigger the same type of response, so behavior is consistent and testable. Typical protocol steps Most robust error handling protocols include: 1. Detection: Input validation, exception handling, health checks, and monitoring alerts to spot errors early. 2. Classification: Categorizing errors (e.g., client vs server, transient vs permanent, security vs functional) to choose the right response. 3. Immediate response: Returning safe responses, rolling back transactions, putting components into a safe state, or activating a fallback. 4. Notification and escalation: Alerting on-call engineers or responsible teams when thresholds or critical conditions are met. 5. Recovery: Retries, circuit breakers, failover, restoring from backups, or guiding users to correct the problem. 6. Recording and learning: Logging, post-incident reviews, and updating documentation or code to prevent recurrence. Technical best practices - Clear error contracts: Define standard error formats and codes for APIs and services (e.g., HTTP status + structured body with code, message, and correlation ID). - Graceful degradation: Provide reduced functionality instead of total failure (e.g., cached data if a live service is down). - Context-rich logging: Log enough context (what was attempted, identifiers, environment) to debug without logging sensitive data in plain text. - Isolation and containment: Use timeouts, bulkheads, and circuit breakers so one failing component does not cascade across the system.
1 like • Mar 9
@Nashwa Elfaroug حاااضر يا نشوى وبشكرك جدا على تعليقك البناء ده يا جميله 🤩

Mar 9 •
From Prompt to Production
Using NotebookLM to Generate a Guide for Creating Professional Visual Content with Generative AI These materials provide comprehensive guidance on utilizing generative AI models and fundamental graphic design principles to create professional visual content. The documentation for Nano Banana and Nano Banana Pro explains how to choose between high-speed image editing and complex, reasoning-heavy tasks like typography and infographic layout. Similarly, the guide for Veo 3.1 introduces advanced workflows for video generation, focusing on cinematic controls, synchronized audio, and maintaining character consistency. To ensure high-quality output, the sources also outline essential design foundations, such as alignment, contrast, and proximity, which provide the structural discipline needed for effective communication. Together, these sources teach users how to combine strategic prompting with established artistic rules to produce polished, intentional media. By: Ali Atabani

0 likes • Mar 9
مهما اوصف الابجاع في الانفوغرافيكس والملف تصميمو يفوق حد الخيال كعادتك مستر علي 🤩🤩دائما بتبهرنا بالاشياء الجميله دي .. جزاك الله خيرا على نشر مثل هذا المعلومات

Mar 4 •
ChatGPT مناسب للمهام الأكاديمية، والبرمجة، وكتابة التقارير المتقدمة.
Google Bard مناسب للبحث السريع والحصول على معلومات محدثة. Claude مناسب للتحليل اللغوي العميق والمهام النصية الطويلة.
0 likes • Mar 5
موفقه يا ايمان
0 likes • Mar 5
صراحه اول مره اسمع ب Google Bard
1-10 of 33
