Activity
Mon
Wed
Fri
Sun
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
What is this?
Less
More
Memberships
AI Developer Accelerator
11.2k members • Free
1 contribution to AI Developer Accelerator

Feb '25 •
Open AI cost Optimization
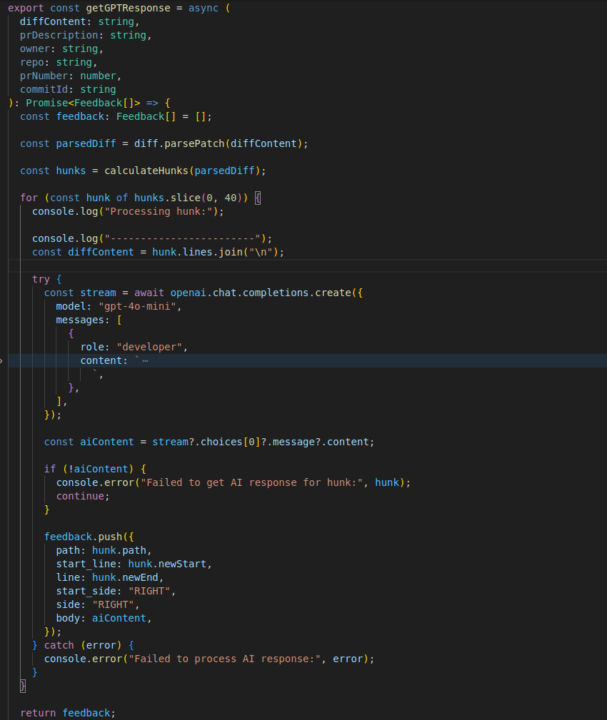
Hey everyone! I use AI to review my diff files for pull requests. My goal is to review each hunk of the diff file, so I want the review from AI to be specific to each hunk. Currently, I loop over the hunks, and for each one, I make a request and then save the feedback with the hunk data. This approach is costly. I’m looking for a solution to reduce the number of AI requests while still getting feedback from the AI that is specific to each hunk.
1-1 of 1

@abdelwahab-amged-2765
I'm a developer who wants to learn more about AI
Active 321d ago
Joined Feb 3, 2025
Powered by