Activity
Mon
Wed
Fri
Sun
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
What is this?
Less
More
Memberships
社畜進化論|Raven AI
135 members • Free
7 contributions to 社畜進化論|Raven AI

May 12 •
我做了 AI 工作流,把每週剪片時間從 2 小時壓到 30 分鐘,用了 8 個步驟
一直以來,拍片就是我比較難跨越的領域。 因為我沒有系統性地學習過該如何拍片,也不知道要如何剪輯影片,所以一直在調整方向。 本來我買了 Filmora 來做影片剪輯,它算是市場上相對比較簡單好用的軟體,價格上也不太貴,一年大約花了一千八百多塊。 當然,雖然說它的功能很強大,但就是要花時間去學習。 對於我們這種把經營自媒體當作副業的人來說,平常下班之後要做研究,然後還要拍片,實在沒有辦法撥出更多時間來學習剪片。 可是我發現,可以使用 Claude 當作核心,並結合一些開源工具建立 AI 工作流,讓整個流程都能交由 AI 來完成最繁雜的剪片工作。 全程幾乎沒有任何技術難度。你只要知道怎麼樣下載 Claude Desktop,然後讓它去幫你操作就可以了。 --- ■ 整套 AI 剪片工作流:八步驟拆解 這套流程串了三個開源工具,加上一個 API。 先看角色分工: - ElevenLabs Scribe:把語音轉成有字級時間戳的逐字稿:雲端 API(scribe (https://elevenlabs.io/speech-to-text)) - video-use:讀逐字稿、決定剪輯點、輸出剪好的影片:github.com/browser-use/video-use (https://github.com/browser-use/video-use) - Remotion:用 React 寫程式碼產生片頭片尾動畫:github.com/remotion-dev/remotion (https://github.com/remotion-dev/remotion) - ffmpeg-full:影片合併、字幕燒入:`brew install ffmpeg-full` video-use (https://github.com/browser-use/video-use) 是 browser-use 團隊出的「**用 Claude Code 剪片**」開源工具。讓 AI 做剪輯、剪贅詞、調色、嵌入字幕,每個剪接點還會自跑一次自我檢查抓跳接和爆音。 Remotion (https://github.com/remotion-dev/remotion) 是「**用 React 寫程式碼做動畫影片**」的開源框架。它給你一個 frame 編號和一張空白畫布,然後去畫每一幀畫面,最後渲染成 MP4。 ffmpeg-full (https://formulae.brew.sh/formula/ffmpeg-full) 是這套流程最後的「組裝工」,負責兩件事:把 cold open、片頭動畫、主體影片、片尾這四段串成一支完整的 mp4;以及把中文字幕嵌進社群短片版本(IG/FB/Threads/Shorts)。 要裝前面三個開源工具,你就直接把 Github 的網址跟 Claude 說,跟它講你要裝這些開源專案,他就會幫你裝好。 但是 ElevenLabs Scribe API 你要自己申請。 ElevenLabs Scribe (https://elevenlabs.io/speech-to-text) 是 ElevenLabs 推出的語音轉文字模型,支援 90 多種語言(含中文)。它會回傳**字級時間戳**和聲音事件標籤(笑聲、停頓),這是後面 video-use 開源專案能精準刪除贅詞的基礎。 價格的話,從每月訂閱費 $6 到 $11 美金,其實也不算太貴。詳情大家可以自己去官網看。 整個流程分八步: ■ 1. 錄影 我用 Filmora 做螢幕錄影,錄完輸出成 mp4 丟到專案目錄。Filmora 在這一步只負責「按下錄影鍵到輸出檔案」這件事。當然也有可能會做一些聲音上的調整,以及稍微加一點素材。 ■ 2. 轉錄 video-use 把音訊抽出來送進 ElevenLabs Scribe,回傳 JSON 含每個漢字的起訖時間、speaker_id、音訊事件標籤(笑聲、停頓)。

1 like • May 17
感謝分享
Apr 7 •
課程影片更新:家庭記帳 App
CH5|Line + Google 試算表 + AI,打造家庭記帳App 後來我昨天又重新修補了,正式上線給家人用。 這裡踩到一個坑,當專案與專案合併時,如果新增的專案會與外部連線,則必須重新取得授權。 不然連錯誤訊息都收不到。 卡了很久,後來讓系統自動產生錯誤資訊,丟到 Google Sheets,然後抓到錯誤資訊,讓 AI 去修補,再進行人工授權。
0 likes • Apr 8
設定Line API可能太精簡 好像有些說明沒放在網頁 搭配claude code處理,webhook測試一直說回傳302非200但自己用都沒事 感謝K大 最後還是部屬成功了!
Dec '25 •
Google 舊客戶如何取得半價優惠
Google AI Pro 提供訂閱一年半價的優惠給新用戶,如果你已經是 Google AI Pro 的訂閱戶,是沒辦法享受這個優惠的。 不過,有個辦法能夠讓你取得半價優惠。 操作過程如下: 1. 創建一個新帳戶,算是你的分身 2. 登入主帳號,在 Google One 找到「管理家庭群組設定」 3. 在主帳號底下,關閉「與家庭成員共用 Google One」 4. 在主帳號底下,把新創的帳號加入家庭群組 5. 登入新創的帳號,用新創的帳號訂閱 Google AI Pro 年約 6. 在新創的帳號底下,開啟「與家庭成員共用 Google One」 7. 回到主帳號,取消 Google AI Pro 訂閱 使用下列方法前請注意: 1. 你與其他帳號的操作地點都要在同個國家。 2. 你本來不是年約訂閱戶 3. 如果你的家庭群組本來就有其他帳號,可以用其他帳號購買,不用創新帳號 上述方法經我實測保證有效,另外提供網路上看到的方法。 登入主帳戶,在 Google 帳戶 -> 資料和隱私權 -> 刪除 Google 服務 -> 刪除 Google One 主帳戶就能夠以新帳戶的身分訂閱了。這招我沒試過,但是許多網友回報有效。 https://myaccount.google.com/deleteservices?gar=WzI2N10&pli=1&rapt=AEjHL4MmTmPtgxwP9nqZX1Z1Yt-9YoY8C8HmMNOK3FAoPY4BilKOGXEb1-MzHNIaIFE-xTroCMQMTDrxfVU0IjMHB1I1fvO3Y_DJPQFE4Lt06pg4jgSpcCU
0 likes • Jan 1
@Kenji Ong 沒問題+1
Nov '25 •
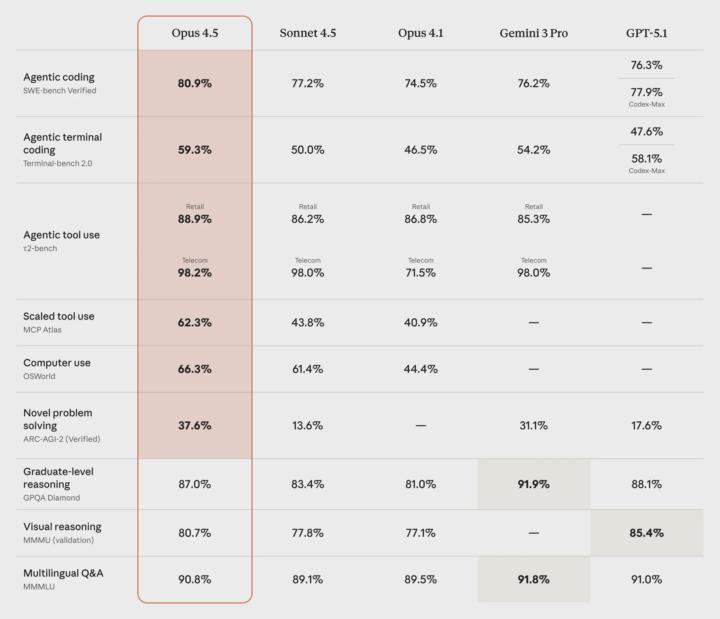
一張圖看懂 Claude Opus 4.5、Gemini 3 Pro 與 GPT-5.1 的真實差距
Anthropic 官方釋出的這張最新評測圖,揭示了 2025 年 AI 三巨頭截然不同的進化樹。 如果你還在問「哪個 AI 最強?」,這張圖告訴我們:答案取決於你要它「做什麼」。 我們不再處於一個通用模型通吃的時代,而是進入了「專長分化」的階段。 1. Claude Opus 4.5:最強的「實作代理人 (Agent)」 寫程式還是得用 Claude。 - 關鍵數據:Agentic Coding (80.9%) & Computer Use (66.3%) 。在 SWE-bench(軟體工程測試)中,它突破了 80% 的大關,大幅領先 GPT-5.1 (76.3%)。更可怕的是 Computer Use 能力,它能像人類一樣直接操作電腦介面。 - 含義: 這是邁向 AGI(通用人工智慧)的重要一步。Claude 不只能寫出程式碼,還能自己去終端機跑測試、Debug、甚至操作你的滑鼠去填表單。它是目前最接近「數位員工」的模型。 2. Gemini 3 Pro:無懈可擊的「學術大腦」 Google 展現了知識深度。 - 關鍵數據:Graduate-level reasoning (91.9%) 在 GPQA(博士級科學問答)測試中,Gemini 3 Pro 拿下了全場最高的 91.9%,狠狠甩開了 Opus 4.5 (87%) 和 GPT-5.1 (88.1%)。 - 含義: 如果你的工作涉及硬科學(生物、物理、化學)或極度複雜的學術考據,Gemini 依然是首選。它的「幻覺」可能最少,邏輯推演最嚴謹,且在多語言(Multilingual Q&A)上保持了傳統優勢。 3. GPT-5.1:視覺王者,但在「新邏輯」上遭遇滑鐵盧? GPT-5.1 的數據在這張圖上呈現了有趣的兩極化。 - 強項:Visual Reasoning (85.4%) 在 MMMU(多模態視覺推理)上,GPT-5.1 奪得冠軍,高出 Opus 4.5 近 5%。這代表它看圖表、理解複雜影像的能力最強。 - 弱點:Novel problem solving (17.6%) , 這是令人震驚的數據差異。在 ARC-AGI-2(抽象推理與新問題解決)測試中,Opus 4.5 拿下了 37.6%,而 GPT-5.1 僅有 17.6%。 - 含義: ARC 測試的是「面對從未見過的邏輯規律」的反應能力,無法靠背誦數據庫得分。這暗示了 GPT-5.1 可能非常擅長處理已知的知識與模式,但在面對完全陌生的情境時,其「舉一反三」的靈活性可能不如 Claude Opus 4.5。 這張圖表打破了「一家獨大」的局面,根據你的需求,選擇會完全不同: ✅ 選 Claude Opus 4.5: 如果你是工程師,或需要 AI 自主完成一連串複雜操作任務(Agentic Workflow)。 ✅ 選 Gemini 3 Pro: 如果你是研究人員、博士生,需要最精準的知識庫與學術推理。 ✅ 選 GPT-5.1: 如果你需要處理大量視覺資訊、圖表分析,或是習慣於處理標準化的通用任務。不過,由於 Gemini 3 Pro 並沒有 Visual Reasoning 的分數,所以還未可知。
2 likes • Jan 1
Gemini3視覺應該也滿強的
Dec '25 •
基礎課程影片改為 Lv2
原本打算採付費制,後來想一想還是直接提供給社群內的人都可以觀看,畢竟是基礎版。 課程影片將採 Lv2 制,請努力與社群互動,晉升 2 級。 影片更新時程請見 https://www.skool.com/decode-ai-ai-2667/classroom/afaf661a?md=197a30779e714ed5bb8dfc7d3323214b PS: 請注意影片更新時程可能會修改。
2 likes • Jan 1
感謝分享
1-7 of 7
