
Write something

6d •
Can competitor research be a valid source of test hypotheses?
Most of what we talk about in experimentation circles starts with your own data. Heatmaps, session recordings, post-purchase surveys, customer interviews. The idea being: if you want to test something that moves the needle for your brand, start with your customers. @Andy Costes pushed back on that last week on Live with Intelligems. His take: your competitors are running their own experiments too. They have different teams, different budgets, different areas of focus. And when you watch what they ship and keep for two to three months, across multiple brands, you start to see patterns worth questioning. Not copying. Forming hypotheses. Curious where you land on this: - Do you actively do competitor research as part of your testing process? How? - How do you decide if something a competitor is doing is worth testing for your own brand? - Is there a risk of optimizing toward the wrong benchmark?
0
0
May 11 •
How much has your workflow actually changed with AI?
Attached is what a rigorous CRO workflow looked like at my old agency a few years back. Every step had a dedicated human. Research, ideation, technical feasibility, documentation, design, coding, QA. If anyone was slow or busy, the whole thing stalled. And this is assuming the team actually had time to go through all of it — sometimes you had to cut corners just to keep the program moving. Last week @Victor Paytuvi and I went live to talk about how much this has changed. Full replay here if you missed it: How AI is Reshaping Ecomm Optimization Workflows — Live with Intelligems A few things that came up: - Automated test reporting was both of our first real AI use case (~2023). The mechanical part of writing up results doesn't need a human. That time goes back to strategy. - Prototyping with AI closed the communication gap between CRO strategists and designers. Days of back-and-forth became hours. - AI-coded variants are no longer science fiction. One practitioner at Jones Road is running his entire program solo today. We also talked about what won't change: the contextual judgment that comes from knowing a brand deeply, its customers, its history, what's keeping the founder up at night. That's still on us. Curious where this community is at. What's the first step in that process you stopped doing manually?
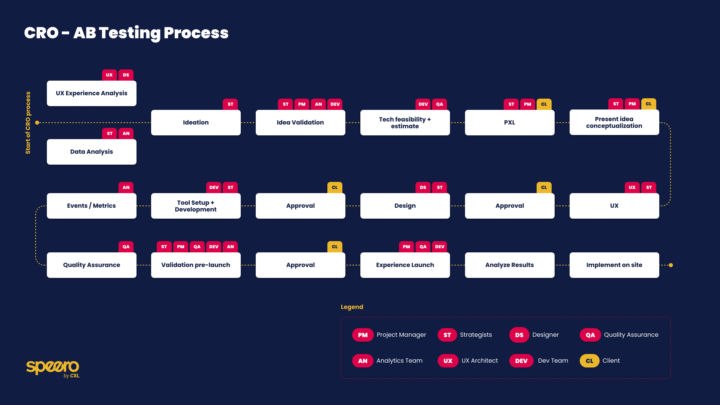
21d •
Naming conventions: the most boring thing that makes experimentation programs scale
It blows my mind how many companies run experimentation without a naming convention. Not an imperfect one. None. Tests called "homepage revamp" or "Q2 pricing," somewhere in a spreadsheet or just inside Intelligems, with no structure, no ID, no way to find them six months later without scrolling through 40 rows trying to remember what was actually being tested. And I think it's a hard way to scale an experimentation program. The fix is simple: give every test a unique ID and a structured name before you do anything else. The ID part is what I'm most emphatic about. Something as simple as #1, #2, #3. Or more structured: EXP-23. Looks bureaucratic. Feels unnecessary on your first few tests. But here's what I noticed when I was on the agency side: stakeholders started referencing the IDs in their own conversations. Instead of "that price test from March," they'd say "test 47." That moment, when a client uses a test ID unprompted in a meeting, that's when you know the program has actually landed. They're thinking in experiments now, not in one-off projects. It just makes everyone's lives easier. Stakeholder updates, Slack threads, QA handoffs, everything gets cleaner when there's a shared shorthand. And when you need to iterate on a test, same hypothesis, new variant, you just add a suffix: Ex47a, Ex47b. No confusion, no "wait, which version of that test are we talking about?" Beyond the ID, a naming structure worth trying: 'Ex[#] | Surface | Short Name | Date' Example: 'Ex47 | PDP | Anchor Price Removal | May 2026' The best part: this is trivial to auto-generate with a formula in whatever tool you're using, Notion, Airtable, Google Sheets. One formula column that builds the name from your existing fields. You fill in the surface and a short description, the ID increments automatically, and the full experiment name writes itself. One line. You know what number it is, where it ran, and what changed. A year from now you can look back across your test library and actually see patterns, which surfaces you've tested most, which hypotheses keep winning, where you've put a lot of effort with not much to show for it.
0
0
May 4 •
Does A/B testing hurt CACs? Let's talk about this openly
My take: the concern is valid, but "therefore stop testing" is the wrong conclusion. The criticism has a legitimate core. The testing industry has been slow to reckon with acquisition costs. If your test "wins" on conversion rate but the winning experience makes your CAC worse, you might have won nothing — that's a real blind spot. But every single change you introduce might affect your CACs; stopping to measure their impact is not a solution. What's actually going on in most cases: paid media and on-site testing run on completely different clocks. Meta sees a 5% CAC shift and someone acts that day. A valid on-site test usually needs weeks of traffic. They're measuring different things in different places, and when paid wobbles during a test window, it's easy to blame the test. But there's something many people miss: if your numbers hurt a little while the test runs, but you walk away knowing something you'll use for the next 6, 12, 18 months... that's not a loss. That's the cost of learning something real. A temporary CAC spike that teaches you the right price point is a bargain. What I'm curious to hear from you: - Have you seen any true correlation between running tests and CAC spikes? What did you do about it? - Has this changed how you structure your program at all? - How are you handling this conversation with stakeholders? Our gut says the CAC impact is probably overstated... but that's not always how it reads in the room. How do you navigate that?

Jan 29 •
I want to hear from the GEM community...
What's the most impactful or interesting test you all are running currently?
1-5 of 5

skool.com/gem
A free community where e-commerce teams learn to test beyond the page. If you want to validate business decisions with confidence, this is for you.
Leaderboard (30-day)
1

+2
2

+1
Powered by