
Write something
Pinned

Dec '25 •
I'm shutting down this community
I started this community over two years ago with a simple goal: to create a free place to learn, share knowledge, and help people get started with Python and data. For a long time, that worked well. Many of you showed up with exactly that mindset, and for that I am genuinely grateful. Unfortunately, the reality today is very different. Over time, the community has been taken over by spam, scams, and people trying to sell to or profit from others. At this point, most of the activity no longer has anything to do with learning or knowledge sharing. Keeping a free community like this healthy would require constant, active moderation. Since Skool does not have an API, that would mean someone on my team manually clicking through spam messages all day. That is not something I want anyone spending their time on. To be fully transparent, I have let this community run on autopilot for the past year. That is not fair to the people who are here with good intentions. Because of that, I have decided to shut down Data Alchemy. Going forward, all of our communities will be private and actively moderated. That is the only way to create a high quality, safe environment where people can actually learn and connect without dealing with scammers or noise. This does not mean the end of learning or staying in touch. I will continue to be active on YouTube, especially in the community feed and comment sections. Those are the best places to keep learning, ask questions, and stay connected without having to worry about spam or people trying to take advantage of you. And in case you have not seen it yet, I recently updated a full Python introduction course on YouTube. It covers everything I wanted to share in this free community, and more, in a single five hour video. Thank you to everyone who showed up, shared knowledge, asked good questions, and contributed in a positive way. I truly appreciate the time and energy you put into this community.
66
0

Dec '25 •
Why your data pipeline feels busy but still doesn’t help decisions
I see this a lot in teams working with data + AI. Pipelines are busy. Events flowing. Running analysis and nurturing. Dashboards updating. Yet when a real decision needs to be made, people still ask: “Can someone look into this?” That’s a signal something’s off. A busy pipeline doesn’t mean a useful pipeline. Here’s the common issue, in simple terms: Most pipelines are built to move data, not to support decisions. They focus on: • ingesting everything • transforming everything • storing everything But they forget to ask one basic question early: 👉 What decision is this data supposed to help us make? When that’s unclear, pipelines become noisy. A healthier pipeline looks like this: Decision first Example: “Do we intervene when user churn risk increases?” Minimal signals Only ingest data that actually affects that decision(not everything you can track). Clear thresholds At what point should the system alert, act, or stay quiet? Simple output Not a dashboard. A recommendation, alert, or action. This is where AI actually helps —by filtering noise, summarizing context, and pointing to what matters now. Busy pipelines move data fast. Good pipelines move understanding fast. Data alchemy isn’t about making pipelines bigger. It's about making them calmer, clearer, and decision-ready.

Dec '25 •
Power BI Modeling MCP Server: Revolutionize Your Data Analysis
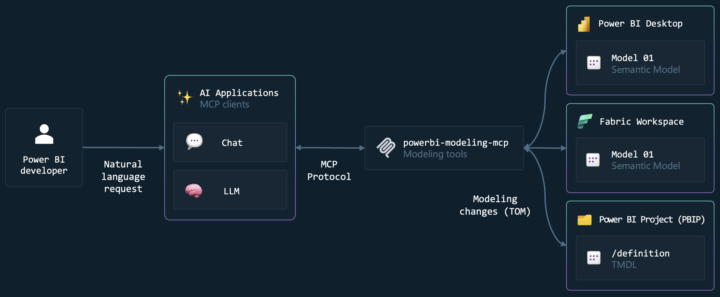
30 minutes instead of 3 hours. Yes, you read that right. I discovered Power BI Modelling MCP Server and it completely changed how I analyze data. Context: Analyzing the downloads data of my ebook "The AI & Data Alphabet 2025" ➤ Before: 2-3h manual cleaning + DAX measures creation ➤ After: 30 minutes flat What changed: ✓ Automated data cleaning ✓ Intelligently generated DAX measures ✓ Optimized relational model effortlessly Result? I can finally focus on : → Design → Visualization → The story my data tells No more time wasted on repetitive tasks. AI handles the technical work, I focus on insights. Need to analyze your Excel or Google Sheets data to save precious time? Comment "MCP" or contact me directly here:eufyves@gmail.com See the demo here : https://www.linkedin.com/posts/sikati-yves-joseph-039215330_powerbi-mcp-dataanalytics-activity-7405983959383293952-FufT?utm_source=share&utm_medium=member_desktop&rcm=ACoAAFNTSu0BMmAIuDsPU-opNQXNfJE12Ba-Vg4 and follow me on on my socila media availble here : https://bit.ly/m/yvesvirtuel #share #entrepreneur #AI #africa #education
Dec '25 •
🚨 Good news for fans of Ollama and open-source LLMs!
👉 Ollama has just launched its Cloud version🚀 📚 To access the documentation, just click [https://www.notion.so/Yves-Virtuel-IA-Data-Automatisation-2b072d336c2e81d4842cf76cc24cf403?source=copy_link#2d872d336c2e80229512e86b5d6862f2]. 🔧 For integration with n8n or Python, feel free to reach out to me here if you run into any issues. 📲 I’ve also launched my WhatsApp channel check it out via this link: [https://whatsapp.com/channel/0029Vb6fWEdCcW4hXGiJyR3b]

Dec '25 •
The missing layer in most data stacks: decision memory
Most data stacks are excellent at answering: “What happened?” Very few are good at remembering: “Why did we decide this?” That’s a massive blind spot. Every meaningful decision creates context: • assumptions • confidence level • alternatives considered• time pressure And then… it disappears. High-maturity data systems include decision memory. Here’s what that looks like: 1️⃣ Decision Logging Not just outcomes, but: • what signals triggered action • what thresholds were crossed • who (or what) made the call 2️⃣ Assumption Tracking Every decision is tied to assumptions. When assumptions change, the system flags it. 3️⃣ Outcome Attribution Did the decision Help ?Hurt? Have no effect? Most teams track results but not causality. 4️⃣ Feedback into Models Signals that consistently mislead get down-weighted. Reliable ones gain influence. This turns hindsight into learning. 5️⃣ Retrieval at Decision Time When a similar situation appears, the system surfaces: • past decisions • outcomes • lessons This is institutional memory — automated. Data alchemy isn’t about storing facts. It’s about remembering judgment. The future belongs to systems that don’t just analyze the past, but learn from their own decisions.
1-30 of 4,199

skool.com/data-alchemy-9173
Your Community to Master the Fundamentals of Working with Data and AI — by Datalumina®
Leaderboard (30-day)
1
+68
2
+12
3

+11
4

+11
5

+10
Powered by