Activity
Mon
Wed
Fri
Sun
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
What is this?
Less
More
Memberships
Inteligencia Artificial México
2.5k members • Free
1 contribution to Inteligencia Artificial México

21d •
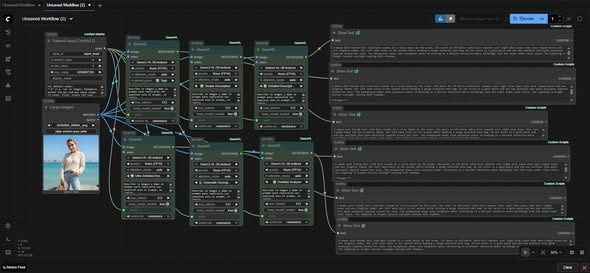
🤖✨ QwenVL: la nueva mente visual dentro de ComfyUI
¡Ahora tu ComfyUI puede entender imágenes como un humano! Con el nodo QwenVL, la IA analiza, describe y genera prompts automáticamente a partir de cualquier imagen ¿Qué puede hacer? Describe imágenes con detalle (ropa, fondo, estilo, emociones). Analiza video frame a frame. Crea prompts listos para Stable Diffusion. Responde preguntas sobre lo que ve. Modos de descripción Simple – breve y directa. Detailed / Ultra Detailed – descripción completa. Cinematic – estilo de película. Analysis – enfoque técnico y preciso. Modelos compatibles Qwen3-VL-2B hasta Qwen3-VL-32B, con versiones FP8/FP16 según tu GPU. Cuanto más grande el modelo, más natural y detallado el resultado. Imagina esto: Subes una foto → QwenVL la describe → el texto se convierte en prompt para tu siguiente generación. Automatiza tu creatividad con inteligencia visual.

2 likes • 6d
Hello
1-1 of 1
