Activity
Mon
Wed
Fri
Sun
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
What is this?
Less
More
Owned by Samir
Turn your AI skills into consulting gigs. Build a business where clients come to you—no bro chat, just help with your strategy, marketing & sales.
The friendly Motorsports Tech Club. Giving you straight answers, support & inspiration. Unlimited Q+A on racecar setup, data, driving and more...
Memberships
Business AI Alliance
8.4k members • Free
AI Automation Society Plus
3.1k members • $94/month
Synthesizer
33.6k members • Free
AI with Apex - Max aka Mosheh
150 members • Free
LION Mentality
324 members • Free
AI Automation Society
227.8k members • Free
AI Automation Agency Hub
281.5k members • Free
AI Developer Accelerator
10.9k members • Free
5minAI
2.9k members • Free
2 contributions to 5minAI

Jun '25 •
⚠️ I'm closing free community
Hi everyone, I’m reaching out to let you know that I’m going to close this community. When I started this group, I was intoxicated by the success of other creators. I wanted to make a lot of money like my competitors and switch from working to teaching because I love it. I thought my huge experience would help me with that—but that was a mistake. During this six-month chase, I realized a lot—mainly that I was focused on the wrong things and had the wrong goals. All these overcrowded communities focus on producing content and getting more members, instead of sharing REAL knowledge. Of course, they share some tips that might seem very good for any non-tech newbie, but professionals in this niche clearly see how far the solutions shared in these communities are from what they actually do daily. Nobody cares about researching technologies and building something reliable and scalable, because it’s very hard and complex work. I’ve been in the no-code niche for five years and know that most no-code agencies focus on MVPs, because 95% of them die after launching. It’s easy money: you build something for a few months, get $15k, and then it dies—nobody will find your bugs, the client will never know that this solution can’t scale beyond 30 users, and you never need to maintain that mess. At the same time, there’s a parallel market for real solutions—usually businesses smart enough to avoid scammy agencies. They collaborate with proven professionals and work with them for years. In this situation, you barely need to make content or share cases, which is why it’s so hard to find such professionals and real information online—they’re busy working. Only a few of them have time to share deep insights. I’m working too—I can’t afford to stop working and just teach because technologies move very fast, and to answer questions, you need to keep gaining new experience, researching new approaches, etc. Otherwise, your knowledge is outdated in just a few months. So I found it very hard to combine content generation and actual work, as both take huge resources to produce high-quality results.

1 like • Jun '25
Sorry to hear this buddy but great you tried to get this going. Best of luck with Pro
Feb '25 •
🧠 Building Smarter RAG Agents – Key Strategies
Many businesses are struggling to build truly smart RAG agents that can efficiently process large knowledge bases with hundreds (or even thousands) of files. The basic vector search approach is too weak—it often retrieves irrelevant chunks, lacks deeper context, and struggles with large datasets. To improve accuracy, additional steps are needed to enrich the context before answering user queries. So I started researching ways to enhance RAG systems and whether these strategies could be implemented in N8N. One of my initial ideas was pre-filtering the data before vector search. Instead of blindly searching across the entire database, we could first categorize files, add metadata links, and apply tag-based filtering to narrow down the search scope before retrieving relevant vector chunks. During my research, I came across a presentation from a LlamaIndex employee (they specialize in RAG for large enterprises) and discovered three practical techniques for improving RAG performance: 1️⃣ Context Expansion Instead of pulling only the most relevant vector, the system can retrieve adjacent vectors (e.g., 2 before and 2 after) to preserve context rather than extracting isolated fragments. ✅ Extra Idea: AI validation can be used to check if the expanded context is useful—if not, it can refine the search and output only the truly relevant chunk. 2️⃣ From Small to Big: Layered Search Instead of running vector search on raw chunks, add metadata summaries, tags, and categories to chunk metadata or a separate table. Then: 🔹 Step 1: Run a vector search only on the metadata layer to identify the most relevant sections. 🔹 Step 2: Retrieve the actual data only from these filtered sections. 📌 This approach requires well-structured metadata summarization based on common user queries and niche specifics. For example, in legal cases, metadata might include facts, dates, names, and key arguments. 3️⃣ Multi-Agent System Instead of retrieving a static dataset, the system can break down the query into multiple sub-questions and distribute them across different AI agents (or loop them iteratively).
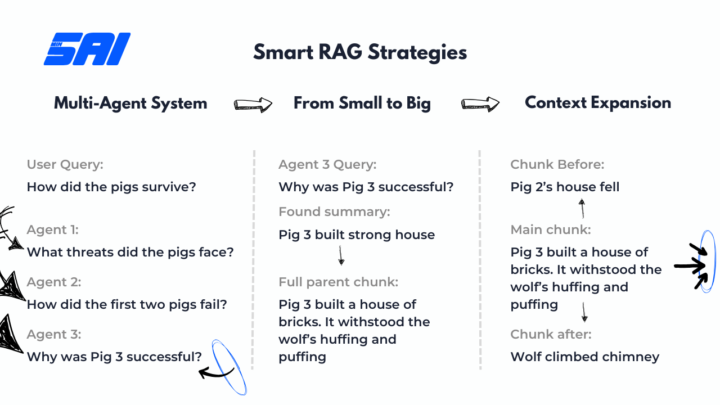
2 likes • Feb '25
Have you actually got this working in n8n? The metadata filtering is broken as far as I can work out - esp if you need the LLM to give the filter details.
1 like • Feb '25
@Mark Shcherbakov Oh fascinating. I've struggled to get access to the LLM request but I guess if you put it in a called workflow you can then have a little more control over this. Thanks - you've just given me an idea! See you've posted this in a few groups I'm a member of so best of luck. A robust solution here is really very over due. If someone could recreate the Document Store in Flowise, that would be even better!
1-2 of 2

@samir-abid
Race Engineer | Ai Strategist
Skools:
- Motorsport Skool
- Ai Freelancer
Active 5h ago
Joined Feb 6, 2025