Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
The AI Laboratory
44 members • Free
1 contribution to The AI Laboratory

Apr 14 •
PEP past paper generator
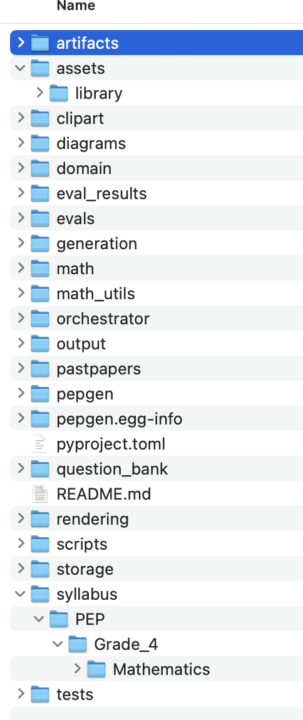
I have a son preparing for his grade 4 PEP exams, and I wanted a way to generate past-paper-like multiple-choice math questions for him to practice. Plain ChatGPT struggles at this. It cannot do math notation, it often provides incorrect or duplicate multiple-choice solutions, and the question quality is pretty low standard and uncreative. Not to mention the fact that almost half of the questions in the real exam come with diagrams and follow a certain question format. After about 3 cumulative days of coding and 25% of my $200 Cursor usage tokens, I'm able to produce a reasonable level of quality past paper. I am even able to use compact mode so I can print it on less sheets of paper to save ink. See attached paper and answer sheet as well as the codebase structure. It uses AI and prewritten templates to generate, evaluate, and validate questions before creating a paper. I plan to extend it to an online tool soon, right now it's a Python application with about 30 command-line interface commands.
1 like • Apr 15
There are so many parts to this that if I try to respond, I know I'll miss out on something, so I asked Cursor to give you a response. Words in { } are mine. I use a structured generation + validation pipeline, not freeform prompting. 1) "Why no Codex/Claude Code?" - For coding workflow, I do use an IDE agent setup (Cursor-style workflow) to build the system. { If you mean why I use Cursor over Claude, #1 is that I have a lot of customizations in this harness, and I like the Developer Experience. My initial trials of vanilla Claude Code didn't feel like I was getting better outcomes and I like the deep VS Code integration of Cursor, at the last time I tested Claude, I didn't get most of these } - For runtime question generation, I call models through a Python AI client with role-specific models (via LiteLLM + Instructor), so model choice is swappable per role. - Current default role split is: - generate: anthropic/claude-sonnet-4-6 - validate: anthropic/claude-opus-4-6 - vision QA: gpt-4.1 {can't seem to get later models for OpenAI, didn't spend too much time on it} - image generation: openai/dall-e-3 - So practically, this is not tied to one assistant UX; it is model-orchestrated infrastructure. 2) On DeepSeek for math - Agree it is worth testing. The architecture supports this easily because generation/validation models are config-driven. - I can A/B it in two places: - generation model (creative drafting quality + schema reliability) - validation/judge model (answer-consistency + pedagogical filtering) - I would not swap blindly; I'd run controlled evals on the same dataset/bank slice and compare pass rates by scorer, not just anecdotal output quality. 3) "What evaluation/guardrails are you doing?" This is where most of the work went. There are two layers: A) Production validation gate (used before questions are accepted) - Structural gate: - exactly 4 options (A/B/C/D) - exactly one correct answer key - duplicate/equivalent option detection
1 like • Apr 15
I’ll check out dspy Haven’t had much issues with token usage. LLM is only used for question generation. Generated 100 questions including validation and it cost less than $2. Will still give the Chinese a try. Right now Im dogfooding this app, shared the final generated papers with some other parents. Nobody requested the app just yet. In any case I have 2.5 more years of PEP past papers to generate till my boy gets to grade 6. It should be fire by then
1-1 of 1
Active 79d ago
Joined Mar 3, 2026