Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
AI Automation Society
419.1k members • Free
AI Automation Society Plus
3.8k members • $99/month
47 contributions to AI Automation Society

Feb '25 •
Self-Generating N8N Instance Documentation
Hey Everyone! 👋 New to the forum here. Awesome to meet you all and I'm pumped to connect. I have an N8N case I'm curious to get people's take on. I'm trying to dynamically generate documentation of my entire N8N instance and wanted to see if people had successfully done implementations of this. I can see this being a real rabbithole with a billion different types of possible implementations I could do so I'm looking to lean on the wisdom of the community here 🧠 What I'm thinking is something along the lines of: - Pull all N8N workflow configs for workflows I want to document (N8N GET /workflows node) - Run each config through a GPT node that will generate documentation markdown - Run each config through some type of node (TBD - would love inspo here) that will take in an N8N config file and spit out a workflow diagram (possibly .html/.vsdx) - Push the markdown and visualization into a page within Notion/Readme I would then refresh this for all production grade automations I have in the instance probably 1x/day. If anyone has a go-to implementation for this and is willing to share some specs let me have em! If not I'll take any and all ideas folks have particularly for the step that creates the visualization step dynamically. Thanks all! Happy Monday.

1 like • Feb '25
Sorry, my suggestion is to see what package / service it uses. Then use that service to create the workflow.
1 like • Feb '25
It uses Mermaid

Feb '25 •
Newsletter Trigger Based on a Schedule
My Question: How can I build a trigger in n8n that checks the planning and starts the workflow only if a topic is scheduled for today? I want to automate my newsletter based on a planning schedule stored in a Google Sheet. The newsletter consists of sections and each one contains diff topics scheduled... How the Automation Should Work: - Every day, the workflow should read the schedule. - If a topic is planned for today’s date, proceed with the automation. - If no topic is planned, stop the workflow. Any guidance or examples would be greatly appreciated!
1 like • Feb '25
@El maatouki Mohamed I have mocked up the flow. -- Have a trigger that is based on a schedule. -- When it runs it checks your google sheet. I have assumed you may have lots of rows in the sheet each with a 'run date' column -- Loop through the rows and check IF today's date = the 'run date'. If TRUE run the newsletter workflow. If FALSE do nothing. -- NB: I have assumed you loop through all the items in case you have 2 or more news letters that day.
0 likes • Feb '25
@El maatouki Mohamed Sorry, I did not save it - I was just doing it so I could take a screenshot. In future I will include the JSON 🤦♂️

Feb '25 •
[resolved] Memory for Ai agent
Hello! When i used "Window Buffer Memory" i always have this message - "No session ID found" how i can repair this?
![[resolved] Memory for Ai agent](https://assets.skool.com/f/b51c57150c70495899bf4bc8aaee8166/0143064bf47d40a1a3ab0453edaf20da905a0d35e1974bf9a1f6a5814fdd67c2)
2 likes • Feb '25
@Evgeny Korytny if you provide screenshots of the node set up.
1 like • Feb '25
@Evgeny Korytny Can you please update this to have a prefix of [RESOLVED]. The fix was to upgrade to the latest version of N8N. But also if you look at the screenshots the sessionId was not being correctly referenced.

Feb '25 •
Chunk size & text splitting
Hi guys At the moment I'm working extensively with large transcripts from ±2 hour Zoom recordings. The formats of the recordings tend to differ; sometimes it's workshop style with multiple speakers; sometimes module style with a single speaker; sometimes interview style with two speakers. End-result is a ±200k vtt text file with a free-flowing, time-stamped conversation. Very little context if one chunked it but overall it make sense. I'm wondering what's the best or more effective way embed this type of data within a RAG like Pinecone? There are several options: 1. As is: each transcript as a huge text blob with specific transcript meta-data. 2. Chunk it into 10/20/100 text blobs; try and add meta-data but it will all probably share the source's meta-data. 3. Pre-process the transcript into logical blocks (topics or categories) and add these as chunks as vectors. It just seems to me that whatever text-splitting algo is available I'll be ripping out all context of the transcript before I embed it if I don't natively embed things.. But maybe I don't know enough.. I've obviously been through the related RAG videos but they all talk about the process and less so about how to ensure the inputs are good enough to get great results from the output. PS - see attached for a sample transcript. I have a couple 100 of 'em...
1 like • Feb '25
Hello @Alan Alston I would NOT recommend to upload a hugh text blob - that would not work in a vector DB. This is what I would do -- Pre-process your transcript. At the moment there is too much noise as each sentence has its own timestamp. So, I would turn that into longer sections (say 1000 - 1500 charactrers) and have your timestamp reworked so it was the start of the first sentence and the end time of the last sentence per section. -- Then upload those chunks in the vector DB. In your meta data you would put the name of the transcript (so you could group an entire transcrip together) and start / end timestamp of the file. You may also want to put speaker etc into the meta data. That way you would get retain the entire transcript and have the ability to sew it back together to have the entire transcript. You may want to do try summarising into topcis / categories. However, if you do that you will lose the concept of the transcript. So, maybe you could do both. Do the summary / categories and store that + then use some of that for meta data for the raw (but preprocessed as per above) chunked transcript.

Feb '25 •
telegram error
hey guys super new to ai automations and n8n tried making a chat bot with telegram im facing this error....need help from all the smart minds in here
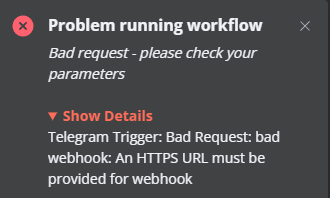
2 likes • Feb '25
@Bill Morio Two elements: -- Logon Screen - you could lock that down to your local IP as you are the only person who will be using it. Further, implement 2FA/MFA - https://docs.n8n.io/user-management/two-factor-auth/ -- Webhooks - you can add authenitcation to your webhooks. That means the calling system will need to be authenticated in order to use them.
1-10 of 47

@peter-hollis-6355
Running my company by day ... building for fun in the evenings.
Active 126d ago
Joined Dec 17, 2024
Powered by