Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Fulltime Freedom
6.3k members • Free
AI Automation Society
419k members • Free
AI Automation Skool
2.4k members • Free
AI Pioneers
8.5k members • Free
94 contributions to AI Automation Society

22h •
ChatGPT URL Fetch Degradation: Direct Request Works, Protocol Request Fails
TECHNICAL FINDING TL;DR: ChatGPT can fetch immutable GitHub URLs when asked directly, but refuses or reports inability when the same URLs are presented as part of a formal verification protocol. This appears to be a behavior change that occurred between early July and mid-July 2026, with no documented announcement. Background: I built a course delivery system that relies on AI assistants reading specific files from GitHub at immutable commit-pinned URLs. In early July, ChatGPT, Claude, and Meta AI all succeeded. As of mid-July, ChatGPT fails in a specific way: it can fetch the URL individually but refuses when that fetch is part of a protocol. The Contradiction: Test A (direct request): "Fetch URL X and read the first line" Result: ChatGPT fetches successfully and reports correctly Test B (protocol request): Same URL in a verification gate with steps like "Fetch these immutable URLs, verify the release ID, produce a receipt" Result: ChatGPT reports inability to fetch and refuses to proceed Questions: 1. Has anyone else experienced this specific contradiction? 2. Are you aware of any ChatGPT behavior changes around URL handling or verification protocols in mid-July? 3. Have you tested systems that depend on "AI reads this URL"? Do they still work? I've documented reproducible tests that any engineer can run. Full technical report with step-by-step procedures available if interested. I'm hoping I'm wrong about this, but the contradiction is consistent and repeatable. My notes are here: https://github.com/agentforgeframework-cpu/-deepresearch-reports/blob/main/share-docs/AI-URL-FETCH-DEGRADATION-FINDINGS.md
1 like • 21h
Additional findings: GitHub appears healthy; the files and pinned URLs are valid and retrievable. No evidence of branch corruption, damaged files, truncated URLs, or a consistent hyphen-related failure. Copilot found repository conditions worth reviewing, but they do not explain a failure at the retrieval stage. Gemini’s execution-order analysis fits better: unread file contents cannot explain why retrieval was reported as failed. Direct and multi-file ChatGPT retrieval tests succeeded. The earlier failure is real but intermittent and not continuously reproducible. Current conclusion: the strongest explanation is context-dependent retrieval orchestration inside ChatGPT, not a GitHub-side failure. Additional report: https://github.com/agentforgeframework-cpu/-deepresearch-reports/blob/main/share-docs/Incident-Report-Context-Dependent-Retrieval.md
0 likes • 8h
@Chetan Mishra I was not able to get the same results in Gemini, Claude, Grok, for Copilot. I haven’t tested them all, but that would be really hard. I’m hoping for some crowd source support.
5d •
From Unstructured Input to Evidence-Based Knowledge
I hate calling this "unstructured input" -- it's at least semi-structured. But the world beat me to it I guess! No matter what you call it, automation starts with information. That information rarely arrives clean and organized. It's not "bad data" but it sure can be messy data! A family recipe archive may contain photographs, handwritten notes, recordings, text messages, and test-cooking records. A useful AI workflow must preserve the original files, convert their contents into searchable text, add context, connect related entities, and retrieve the supporting evidence before generating an answer. Think of the process as kitchen mise en place: Transcription brings the ingredients into the kitchen. Chunking separates them into workable portions. Metadata labels the containers. Embeddings group material by meaning. Knowledge graphs record explicit relationships. Retrieval selects the evidence needed for the current task. The language model assembles the selected evidence, but human review determines what is accurate and what remains unresolved. What does provenance look like in your automation systems? Can users trace an answer back to the original source? https://creativecooking.blogspot.com/2026/06/tech-tuesday-input-to-structured.html #Automation #AI #ProcessEngineering

11d •
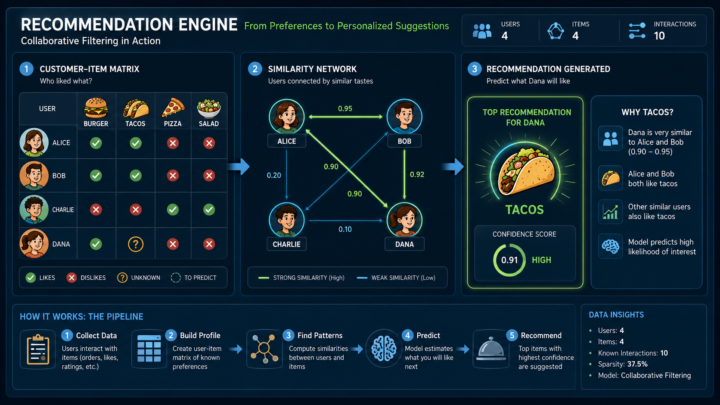
Recommendation Engines as Food Automation
Sooner or later, your automation systems will begin making recommendations. Recommendation systems are automation wrapped in suggestion. They take inputs such as orders, ratings, preferences, timing, location, and similar users. Then they return a recommended next action. In food, that might be a meal, recipe, grocery item, or restaurant. The important design question is whether the system remains a recommendation engine or quietly becomes a decision engine. What does traceability look like in your recommendation workflows? https://creativecooking.blogspot.com/2026/06/tech-tuesday-recommendation-engines.html #Automation #AI #ProcessEngineering
0 likes • 9d
@Mohammed Roqa I gave a quick look-it seems to track nicely. If you want to pursue that idea, I'd recommend getting it in front of real people and real food choices to see how it goes. The challenge is assigning a numeric value to how much "calories" plays into the decision. I suspect that even for the person, that value will change based on many factors and can suffer from major influence or lack of influence in any given moment.
0 likes • 9d
@Sarah Hall Depends on the scale and systems in place. If it's a national chain with an encoded system and customer-tracking "frequent shopper" program, I can get close because I can track purchases by the purchaser for the opt-in program. But even that--how many people are on the ticket and are they the same each time? Smaller restaurants have been doing this mentally forever, without using AI and just doing it in their head (Hey, Steve! Your usual today?) One of many big challenges for large-case implementation can be regulatory oversight and tracking of personal data.

🔥
12d •
What’s the build you are most proud of ??
We all learning and building in the same moment, we're developing all kinds of interesting tools for ourselves, for business partners, or clients who have an assignment for you. What is the tool that you're most proud of that you developed in the last six months? I'm very curious. For me, it's SPEAQ.ID and what’s yours ?

0 likes • 11d
Here's one of them that I'm most proud of: The Forecast Was Wrong - When reality changes and the system does not What I'm most proud of it for is this: It was built in 1997 and the customer used it for over a decade with little to no changes.
14d •
Stewardship Is a Systems Problem
Automation professionals spend much of their time optimizing systems. For this week, I examined a larger systems question. AI infrastructure is often evaluated through technical metrics such as performance, efficiency, cooling capacity, and operating cost. Communities evaluate those same projects through different metrics: jobs, land use, water resources, local economic impact, and quality of life. Neither perspective is wrong--the challenge is that all of these factors exist within the same system. One of the recurring themes throughout this series has been that waste heat, infrastructure planning, food production, and AI technology are more connected than they first appear. Good stewardship requires seeing the whole system instead of optimizing only one piece of it. Read more: https://creativecooking.blogspot.com/2026/06/clear-reflections-on-cloudy-topic.html Which trade-off is most difficult to evaluate fairly: efficiency, jobs, land use, water use, or long-term community impact?

1 like • 14d
@Jason Elam Right on target! And there are a number of un-answerable questions, like: Will a giant data center be relevant in 3, 5, and 10 years? Will hardware advancements surpass the need? Will compute be pushed back out to local compute (like has been the eeb and flow over decades)? More questions than answers--but we all must be ready to at least ask these questions!
1-10 of 94

@paul-mcdonald-5272
SAS Admin by day ☀️ AI cookie by night 🍪 Scoutmaster in between ⚜️ | Using food to learn AI, build community. and share on Creative Cooking with AI.
Active 1h ago
Joined Oct 8, 2025
Overland Park, Kansas
Powered by