Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Entrepreneur Oasis MENA
61 members • Free
AI Automation Society
418k members • Free
103 contributions to AI Automation Society

6d •
From Words to Worlds - SYNTHARA
Most RPGs are scripted. Synthara isn't. Every NPC interaction in Ashenfall runs through a live AI pipeline — in real time, every time: Hermes reads your intent → Vault retrieves your history → Nemotron 3 reasons and responds → Stripe settles the transaction → Codex writes the tactic to your permanent record No branching trees. No pre-written dialogue. Just intelligence, automated. Watch the whole pipeline fire.

0 likes • 4d
@Ahmad Khan Thanks for your insight! Please email I will send the full guide after the hackathon deadline. Thanks! mr@mroqa.site
0 likes • 1h
@Teja Kanuri thank you and appreciate your kind words!
2d •
How Actually My Profile Value!?
I write on LinkedIn about "The 5 Profile Core Valuation Models" . This applied to any-like platform. You will also read about 𝑻𝒐𝒑 40 𝑮𝒍𝒐𝒃𝒂𝒍 𝑰𝒏𝒏𝒐𝒗𝒂𝒕𝒊𝒐𝒏𝒔 + 10 𝑮𝒍𝒐𝒃𝒂𝒍 𝑰𝒏𝒏𝒐𝒗𝒂𝒕𝒊𝒐𝒏𝒔 𝒕𝒐 𝑾𝒂𝒕𝒄𝒉 by BDMT Global Pick one you favourite and let's know why? 👇🏻

1 like • 14h
@Chetan Mishra This is master piece of thought. Thanks!
0 likes • 1h
@Ahmad Khan Thanks, Any technical or economy leader who do difference in our life Reid Hoffman Satya Nadella, Barak Obama, Rafael Nadal, Krestalina Georgieva, Fahad bin Salman, Eric Schmidt, Paige Baily, George Westerman, Bill Gates, Abdallah Alsawaha, Borge Ekholm.
3d •
MolmoMotion: Language-Guided 3D Motion Model
Machines have become remarkably good at perceiving motion. Many of the systems and applications we want to build need to look forward instead. A robot reaching for a cup has to anticipate how the cup will move before it touches it. This idea was the motivation behind MolmoMotion: https://huggingface.co/collections/allenai/molmomotion What would you like to build with it💡
0
0

4d •
Why Most AI Agents Should NOT Be Built
AI agents are having a massive hype moment. Right!? 🧲 Every tech presentation, LinkedIn post, and product roadmap seems to promise that a fleet of autonomous AI agents will soon handle everything for your business🔹But if you look under the hood of what actually delivers value, you’ll find a surprising truth: 𝑴𝒐𝒔𝒕 "𝒂𝒈𝒆𝒏𝒕𝒔" 𝒔𝒉𝒐𝒖𝒍𝒅 𝒏𝒆𝒗𝒆𝒓 𝒃𝒆 𝒃𝒖𝒊𝒍𝒕 𝒊𝒏 𝒕𝒉𝒆 𝒇𝒊𝒓𝒔𝒕 𝒑𝒍𝒂𝒄𝒆. 𝑰𝒏𝒔𝒕𝒆𝒂𝒅, 𝒘𝒉𝒂𝒕 𝒚𝒐𝒖 𝒂𝒄𝒕𝒖𝒂𝒍𝒍𝒚 𝒏𝒆𝒆𝒅 𝒊𝒔 𝒂 "𝒘𝒐𝒓𝒌𝒇𝒍𝒐𝒘" ✅ 𝐓𝐡𝐞 𝐔𝐧𝐧𝐞𝐜𝐞𝐬𝐬𝐚𝐫𝐲 𝐀𝐠𝐞𝐧𝐭 𝐓𝐫𝐚𝐩 It’s easy to fall into the trap of over-engineering. When faced with an automation problem, many teams immediately jump to extreme flexibility. They ask, "𝘊𝘢𝘯 𝘸𝘦 𝘣𝘶𝘪𝘭𝘥 𝘢𝘯 𝘢𝘨𝘦𝘯𝘵 𝘵𝘩𝘢𝘵 𝘧𝘪𝘨𝘶𝘳𝘦𝘴 𝘰𝘶𝘵 𝘵𝘩𝘦 𝘦𝘯𝘵𝘪𝘳𝘦 𝘱𝘢𝘵𝘩 𝘰𝘯 𝘪𝘵𝘴 𝘰𝘸𝘯?" But unless your business goal is completely undefined or highly chaotic, you don't need an agent wandering around trying to find its own way. Workflows are predictable, reliable, and highly efficient. You define the task, map the decision steps, and set a clear path. Agents, on the other hand, enter high-cost, high-risk, and unpredictable error territory because they are constantly trying to reinvent the wheel. ✅ 𝐓𝐡𝐞 80%+ 𝐑𝐮𝐥𝐞: 𝐀𝐠𝐞𝐧𝐭𝐬 𝐁𝐮𝐫𝐧 𝐓𝐨𝐤𝐞𝐧𝐬, 𝐖𝐨𝐫𝐤𝐟𝐥𝐨𝐰𝐬 𝐂𝐚𝐩𝐭𝐮𝐫𝐞 𝐕𝐚𝐥𝐮𝐞 Data shows that in over 80% of business use cases, a structured workflow captures the full value of the project. When you deploy a full AI agent for a simple, repeatable task, you aren't building innovation you're just burning budget. Agents require massive token overburn as they continuously "think," plan, and recalibrate. If a workflow can do the job faster and cheaper, let it. ✅ 𝐓𝐡𝐞 𝐄𝐬𝐬𝐞𝐧𝐭𝐢𝐚𝐥 𝐅𝐞𝐚𝐬𝐢𝐛𝐢𝐥𝐢𝐭𝐲 𝐂𝐡𝐞𝐜𝐤𝐥𝐢𝐬𝐭 Before you let your engineering team dive into building an autonomous agent, run the problem through this quick 4-question 1️⃣ 𝘊𝘢𝘯 𝘵𝘩𝘦 𝘸𝘩𝘰𝘭𝘦 𝘥𝘦𝘤𝘪𝘴𝘪𝘰𝘯 𝘵𝘳𝘦𝘦 𝘣𝘦 𝘮𝘢𝘱𝘱𝘦𝘥 𝘶𝘱 𝘧𝘳𝘰𝘯𝘵? 𝘐𝘧 𝘵𝘩𝘦 𝘢𝘯𝘴𝘸𝘦𝘳 𝘪𝘴 "𝘠𝘦𝘴", 𝘴𝘵𝘰𝘱 𝘳𝘪𝘨𝘩𝘵 𝘵𝘩𝘦𝘳𝘦. 𝘉𝘶𝘪𝘭𝘥 𝘢 𝘸𝘰𝘳𝘬𝘧𝘭𝘰𝘸. 𝘐𝘧 𝘕𝘰, 𝘵𝘩𝘦𝘯 𝘺𝘰𝘶 𝘮𝘪𝘨𝘩𝘵 𝘣𝘦 𝘦𝘯𝘵𝘦𝘳𝘪𝘯𝘨 𝘢𝘨𝘦𝘯𝘵 𝘵𝘦𝘳𝘳𝘪𝘵𝘰𝘳𝘺. 2️⃣ 𝘐𝘴 𝘵𝘩𝘦 𝘵𝘢𝘴𝘬 𝘸𝘰𝘳𝘵𝘩 𝘵𝘩𝘦 𝘵𝘰𝘬𝘦𝘯 𝘤𝘰𝘴𝘵? 𝘐𝘧 𝘺𝘰𝘶 𝘢𝘳𝘦 𝘳𝘶𝘯𝘯𝘪𝘯𝘨 𝘢 𝘧𝘢𝘴𝘵, 𝘴𝘪𝘮𝘱𝘭𝘦 𝘵𝘢𝘴𝘬 𝘰𝘯 𝘢 𝘵𝘪𝘨𝘩𝘵 𝘣𝘶𝘥𝘨𝘦𝘵 (𝘦.𝘨., ~$0.10), 𝘢𝘯 𝘢𝘨𝘦𝘯𝘵'𝘴 𝘦𝘹𝘱𝘭𝘰𝘳𝘢𝘵𝘪𝘰𝘯 𝘭𝘰𝘰𝘱𝘴 𝘸𝘪𝘭𝘭 𝘲𝘶𝘪𝘤𝘬𝘭𝘺 𝘰𝘷𝘦𝘳𝘴𝘩𝘰𝘰𝘵 𝘺𝘰𝘶𝘳 𝘮𝘢𝘳𝘨𝘪𝘯𝘴.

4d •
The Best Teams Automate Systems ⭐
How I think about tools like Zapier turning attendee data into qualified leads and timely follow-ups that's where revenue actually lives turning-webinars-into-revenue-pipelines. The same logic applies to every workflow you own. Zapier's automation content reveals a maturity curve most practitioners never finish climbing: Level 1 — Task automation If this, then that. One trigger, one action. Most teams start here and stop here. Level 2 — Workflow automation Multi-step Zaps with conditional logic. Leads routed by source. Transcripts summarized into action items. This is where productivity compounds. Level 3 — System orchestration AI agents operating across thousands of apps with governed access. A two-person SEO shop managing 12 clients in 30 min/month. A system pulling from Salesforce and Atlassian to generate weekly growth reports — autonomously. Most automation advice teaches Level 1 and calls it a strategy. Zapier identifies 5 workflow categories that look like productivity improvements on the surface. Underneath, they're pipeline stages: 1. Lead notification — the moment a lead enters your ecosystem, the right person knows instantly (with filters so it's a signal, not noise) 2. Lead messaging — AI-generated, personalized follow-up fires before your sales rep sees the notification 3. Calendar & meeting management — every touchpoint creates a searchable, structured record automatically 4. Data consolidation — your CRM, Airtable, or Sheets reflects reality in real time, not yesterday 5. Content distribution — one piece of content, every platform, zero manual publishing These aren't five separate tools. They're one connected pipeline. The minimal viable stack to prove it: → New lead → Slack alert (with quality filter) → New lead → ChatGPT → personalized Gmail → New lead → Google Sheets row → New Calendly booking → HubSpot contact → Meeting transcript → AI summary → Notion action items
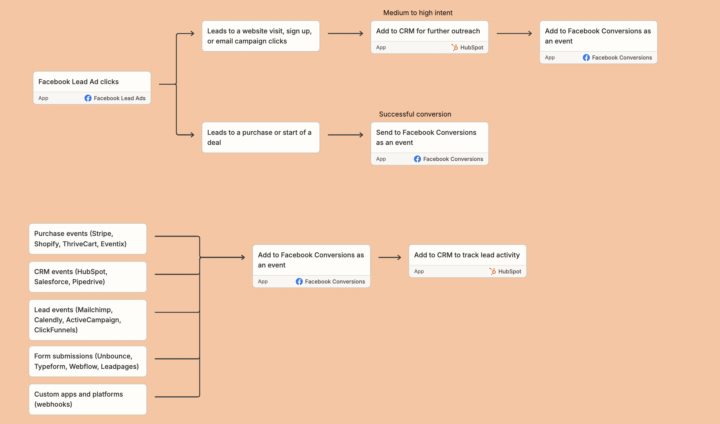
1 like • 4d
@Dionny Chejito How we could solve this issue?
1-10 of 103

@mohammed-roqa-7379
Solutions Architect integrating technology with organizational expansion. Proficient in AI/automation, cloud computing & enterprise-level solutions.
Active 4m ago
Joined Jan 20, 2026
INTJ
Powered by