Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI Studion Sverige
82 members • Free
6 contributions to AI Studion Sverige

Feb 9 •
Hur gillar du det när du jobbar?
- 1️⃣ total tystnad - 2️⃣ musik i lurarna - 3️⃣ halvkaos + kaffe - 4️⃣ annat?

2 likes • Feb 10
2

Feb 4 •
How I use AI and an IDE in my development workflow -Love to hear your work flows!
My process usually starts as if I’m talking to the owner of a development company. First, we do a system brief. Outcomes, constraints, what the system must achieve. That brief usually goes through one, two, sometimes three iterations until it’s clean. From there, I move into a senior-level architectural discussion between me and the AI. We go back and forth, refining ideas, pressure-testing assumptions, and turning rough concepts into structured thinking. Out of that comes real documentation often 10 to 20 documents in total. Some short, some long. System briefs, architecture outlines, infrastructure designs, domain models, boundaries, ingestion and validation flows, human-in-the-loop reviews if AI is involved, and so on. A key part of this is canon. I always define canonical documents: a system brief canon, sometimes a domain canon, sometimes something more specific. These are single sources of truth. The AI understands what “canonical” means, and when things drift, I can always pull it back with “read the canon first.”All of this happens before I touch an IDE. With human developers, this usually happens implicitly they ask the right questions and create the documentation themselves. AI doesn’t do that. It has no long-term memory. So I create the structure for it. That way, when it starts to hallucinate or wander, I can anchor it instantly instead of re-explaining everything from scratch. Only after that foundation is in place do I move into the IDE and let the agent work. The documentation isn’t overhead it’s the control system. So… what do the rest of you do? Or Am I just being overly fucking anal? One thing I forgot to mention: once I move into the IDE—Visual Studio Code, Antigravity, or both that’s where prompting really matters. I don’t just start prompting and hoping for the best. Before any code happens, I create what I call System Specification Documents. I catalogue them and explicitly require the agent to read every single one in detail. To make sure it hasn’t just skimmed them, I ask the agent to explain the project back to me the purpose, constraints, goals, and boundaries. No coding is allowed at this stage. No output. Just comprehension. If it misunderstood something, or if I missed something, we fix that immediately.
1 like • Feb 7
Awesome - Great post — and no, you’re not being overly anal.What you describe is basically the missing “control layer” that makes AI-assisted development actually usable over time. I’ve ended up with a very similar workflow: - Start with a system brief (outcomes + constraints + boundaries) - Iterate until it’s clean and stable - Do architecture discussion before touching the IDE - Produce canonical docs (“source of truth”) that the AI must always read first - Require the agent to explain the system back before any code changes - Only then allow implementation work The key insight is exactly what you said: documentation isn’t overhead, it’s the control system.Without canon, the agent will drift, hallucinate, or “solve” the wrong problem. I’ve also found it helps to formalize the hierarchy of truth, something like: Intent → Contracts → Tests → Code (artifact) Meaning: contracts enforce behavior, tests enforce reality, and code is replaceable as long as the constraints remain intact. Prompt design outside the IDE is underrated too — I do the same “meta prompting” step to figure out the safest instructions before unleashing the agent. Curious: do you enforce contract tests / schema validation as part of your canon, or is your canon mostly narrative docs?
Feb 3 •
OpenAI kontrar med Codex-appen! Ska vi testa den? 😃
Bara för några timmar sedan släppte OpenAI sin nya Codex-app för Mac. Det här ser ut att vara deras direkta svar på Anthropic's Claude Code & Google's Antigravity och det vi håller på med här i studion. Jag har kört lite inledande research via NotebookLM och bilden här visar vad jag hittat hittills. Det verkar som att OpenAI nu satsar stenhårt på just det vi pratar om, nämligen att ha ett helt team av agenter (Multi-agent) som styrs av en central "Orchestrator". Det som ser mest spännande ut för oss: - Skills: Möjligheten att låta agenterna prata direkt med våra andra verktyg som GitHub och Figma. - Säkerhet: De kör allt i en sandlåda så att man kan känna sig trygg när AI:n börjar flytta runt filer. - Parallella trådar: Att kunna ha flera agenter som jobbar med olika delar av projektet samtidigt. Jag är själv helt ny på just OpenAI's Codex-miljö men jag är sjukt sugen på att se hur den står sig mot Antigravity Kit 2.0 som vi precis börjat köra med. Vad säger ni? Är det någon här inne som har hunnit testa Codex i andra sammanhang? Om ni vill så installerar jag appen direkt, filmar hela förloppet och gör en ordentlig "vibe check" åt oss här i Classroom. Ska jag trycka på knappen och börja filma? 👇
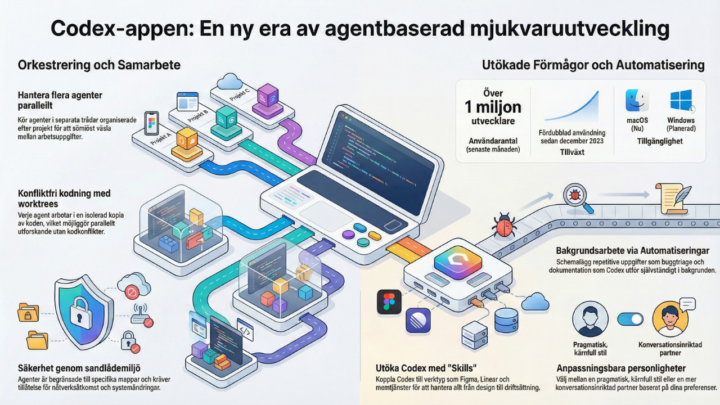
2 likes • Feb 3
I ChatGPT Web så fick jag ett meddelande om att anmäla mig till waitlist för Codex-appen och välja mellan Linux/Windows. Jag anmälde mig för Linux (har ingen Windows-dator just nu). Ni som har Codex-appen i Mac, vet ni om det skiljer mycket jämfört med Codex i ChatGPT Web?
Feb 2 •
Ibland går det fel...
Jag tänkte dela ett exempel på när AI och jag inte alls jobbade så bra tillsammans. Jag försökte lägga till ytterligare en källa för jobbannonser i ett system där en källa redan fungerade stabilt. Det som hände var att den nya källan inte bara strulade – utan till slut slutade även den gamla, fungerande källan att fungera. Vi byggde vidare, justerade, testade igen, byggde lite till… i nästan två dagar. Resultatet blev mest stress, förvirring och känslan av att helt tappa kontrollen över systemet snarare än att komma framåt. Till slut fick det ett lyckligt slut – inte genom någon smart fix, utan genom att backa allt och återställa från backup. Då fungerade allt direkt igen. I efterhand var det ändå en erfarenhet rikare och ganska tydligt vad som saknades: - vi borde ha jobbat i egen branch för större förändringar (jag visste dock inte att det skulle vara så stort/komplicerat när vi började) :-) - Git hade inte hjälpt oss i just det här läget eftersom vi aldrig skapade den branchen - vi saknade automatiserade tester (smoke tests) som snabbt hade kunnat säga: “nu har något grundläggande gått sönder” Lärdomen blev rätt enkel men viktig: - minst en automatisk backup per dag (den körs varje dag automatiskt men bara första gången när jag öppnar terminalen) - alltid branch vid större ändringar - komplettera med enkla automatiserade tester som bara kollar att helheten fortfarande hänger ihop Nu är jag igång igen med ett nytt försök – men den här gången med bättre skyddsräcken. (Detta jobbar vi med nu.) Nu är planen att göra ett nytt försök. Förhoppningsvis går det lite lugnare och bättre för AI och mig den här gången 🙂
2 likes • Feb 2
# ACTIVE_CONTEXT (Community version – sanerad) Detta dokument är en sanerad community-version av mitt ACTIVE_CONTEXT. Syftet är att visa hur jag använder ACTIVE_CONTEXT i samarbetet mellan människa och AI – inte att dela mitt faktiska nuläge. --- ## Vad är ACTIVE_CONTEXT? ACTIVE_CONTEXT är ett styrdokument för pågående arbete. Det definierar: - vad projektet "får" göra just nu - vad som är "förbjudet" - vilka antaganden som gäller - hur nya förslag ska utvärderas För mig är det ett sätt att undvika att: - bygga för mycket på en gång - tappa kontroll när AI är “för hjälpsam” - glida bort från ursprunglig arkitektur --- ## Varför behövs detta när man jobbar med AI? AI är väldigt bra på att: - föreslå lösningar - optimera lokalt - vara positiv och snabb AI är sämre på att: - förstå långsiktig intention - minnas vad som är “off limits” - bromsa när något inte borde byggas ACTIVE_CONTEXT fungerar som "en broms och ett kontrakt". --- ## Hur ACTIVE_CONTEXT används i praktiken - Varje ny AI-session börjar med att ACTIVE_CONTEXT delas - Om kontext saknas → inget nytt arbete påbörjas - Vid osäkerhet → arbetet pausas och kontext uppdateras - Dokumentet ändras "oftare än arkitektur", men mindre ofta än kod --- ## Typiska sektioner (abstraherat) ACTIVE_CONTEXT brukar innehålla: - Scope & authority - Låsta begrepp och terminologi - Aktiv fas (vad vi fokuserar på – inte hur långt) - Invariants som inte får brytas - Non-goals (saker vi medvetet inte gör) - Branch- eller arbetsfokus - Exit criteria för aktuell fas Innehållet är alltid "kort, normativt och tydligt". --- ## Viktig princip: Stoppa hellre än anta En regel jag följer strikt: > Om AI eller jag själv är osäkra på om något är tillåtet – > då är svaret automatiskt "nej" tills ACTIVE_CONTEXT är uppdaterad. Det har räddat mig från mer kaos än någon “smart lösning”. --- ## Tillsammans med CODE_INDEX - CODE_INDEX = hur systemet "ser ut" - ACTIVE_CONTEXT = hur systemet "får förändras just nu" Tillsammans gör de det möjligt att:
2 likes • Feb 2
Där mycket av jobbet med CODE_INDEX, ACTIVE_CONTEXT och AI faktiskt händer i min minimalistiska “AI-studio”. Lugnt tempo, men tydliga ramar + Chromebook och ett försök att jobba metodiskt med AI. 😁
Feb 1 •
🕯️ Söndagsutmaning: AI på 2 minuter
Tänk dig att din internetuppkoppling försvinner imorgon, men du får behålla ett enda AI-verktyg och en enda prompt. Det du väljer ska hjälpa dig i vardagen, jobbet eller ditt skapande. 👉 Min är: Verktyg: ChatGPT Prompt: “Hjälp mig tänka klarare, inte snabbare. Ställ tre frågor som gör att jag förstår mitt problem bättre innan du ger något förslag.” Nu är jag nyfiken på er: 1. Vilket verktyg behåller du? 2. Vad är din “livsprompt”? Bonuspoäng om du berättar varför du valde just den. 👀
2 likes • Feb 2
Jag är lat och bad ChatGPT svara åt mig - fick följande som jag kan hålla med om: 1. Vilket verktyg behåller du? ChatGPT - ...oväntat😆 2. Vad är din “livsprompt”? Hjälp mig se helheten, skydda det som fungerar och föreslå nästa minimala steg. Varför: För att de flesta problem inte löses med fler features, utan med bättre omdöme.
2 likes • Feb 2
@Birgir Birgisson Ja, ...och det tycker jag är helt 100% rätt. 👍
1-6 of 6

@johan-lundgren-7119
Jag bygger strukturerade AI-pipelines och datadrivna system med fokus på reproducerbarhet, arkitektur och kontrollerad AI-engineering.
Active 13d ago
Joined Jan 31, 2026
INFJ
Mölndal