Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Henry
Memberships
Maker School
2.2k members • $184/m
AI Automation Agency Hub
313.4k members • Free
Accelerator
9k members • Free
AI Automation Society
346.3k members • Free
AI Architects
5.1k members • Free
Ecom Automation Hub
154 members • Free
WeScale Free Course
29k members • Free
Nao AI For Business (free)
242 members • Free
Voice AI Alliance
3.4k members • Free
29 contributions to AI Automation Society

Sep '25 •
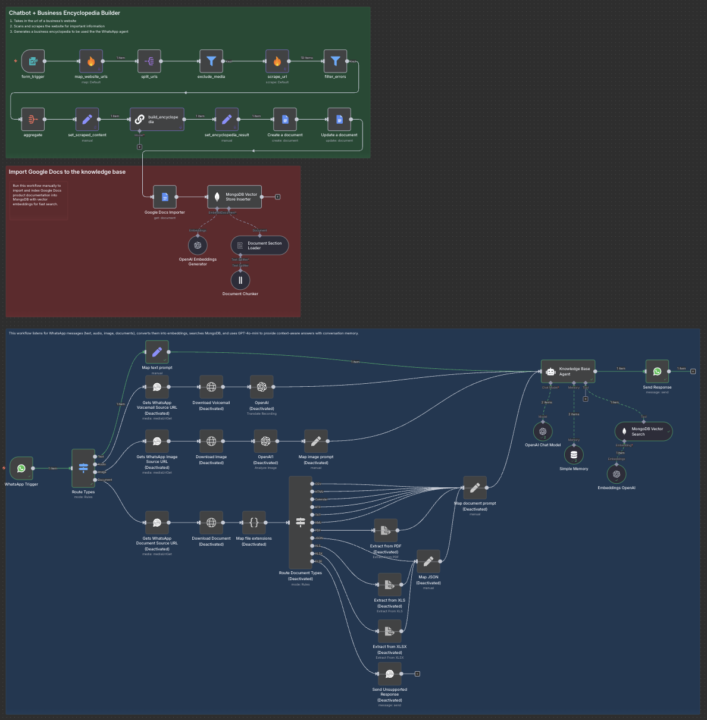
Turning a website into a WhatsApp chatbot
A client recently asked me if I could make all the info from their website instantly available inside WhatsApp. So I explored a RAG chatbot setup and built the following flow in n8n: - Create a form to collect the website URL. - Scrape the site with Firecrawl. - Send all the content into a Google Doc. - Push it into a MongoDB vector DB (create an index). - Connect it to WhatsApp (the trickiest part with Meta). It got me thinking back to my travels in South America & Asia, where WhatsApp is the default, this kind of setup could be a huge value-add for hotels and service businesses. Also, for more control over the conversation flow, I’d recommend layering Voiceflow on top of this. Curious if anyone else has tried something similar or sees other use cases for this stack?
1 like • Oct '25
@Julio Mancero sure !
1 like • Jan 21
@Yesim Saydan you are welcome! Don’t hesitate if you need help

💎
⭐
Jan 19 •
🚀New Video: I Built an AI System That Automates My Proposals (n8n + Gamma)
In this video, I walk through how I built an AI-powered system using n8n and Gamma’s API to automatically turn meeting recordings into professional business proposals and slide decks. The workflow takes a recorded call, transcribes it, and passes it to an AI agent that analyzes the conversation and generates a full proposal based on the client’s needs, goals, and context. That proposal is then sent to Gamma, which creates a clean, professional slide deck filled with the right business details and structure. The finished deck is automatically delivered back for review so you can make quick edits and send it straight to the client. This is a full behind-the-scenes build showing how to automate one of the most time-consuming parts of client work. GOOGLE SHEET TEMPLATE
5 likes • Jan 21
Great stuff @Nate Herk thanks a lot
Jan 15 •
Chunking for RAG: What Actually Works in Production
While doing a lot of Upwork applications for my business outreach, I keep seeing the same question come up again and again in RAG-related projects: “How do you handle chunking properly?” So I spent time designing a clean, production-ready chunking strategy in n8n, and this is the approach I now use. The goal: Give the LLM chunks that are meaningful, well-sized, and aware of where they come from in the document. Here’s the 3-step strategy. 1. Smart Markdown chunking (content-first) Instead of splitting text by character count: • Split by Markdown headings first (#, ##, ###) • Recursively split large sections using paragraphs, code blocks, sentences • Merge tiny chunks to avoid low-signal embeddings • Keep chunk sizes stable for embeddings Result: chunks that still make sense when read alone. 2. Extract document hierarchy (structure-first) Chunking alone loses structure, so I separately extract: • Section titles • Heading levels • Parent → child relationships • Full section paths (e.g. Docs > API > Auth) Then I map each section back to the chunks it spans. Result: I know exactly which chunks belong to which section. 3. Enrich chunks with section context (retrieval-first) Finally, I merge both worlds: • Each chunk keeps its text • Plus metadata like: • Section range • Parent section range • Page numbers (if PDF-based) Result: every chunk “knows” its place in the document. Why this matters for RAG • Better retrieval accuracy • Easier citations (“this answer comes from section X”) • Ability to retrieve full sections, not just isolated chunks • Cleaner UX for chatbots and agents Mental model Markdown → Smart chunks → Hierarchy → Hierarchy-aware chunks → Vector DB Since applying this, retrieval quality has been far more stable on long docs, knowledge bases, and websites. Curious how others here approach chunking for RAG. Do you keep it simple, or have you already hit the limits of naive splitting?
0 likes • Jan 15
@Hicham Char I agree, thanks for your message

Aug '25 •
Please Help Out This Beginner!
Hey everyone, I recently joined to Liam Ottley’s AI Automation Agency Hub and finished the AAA Model. It’s been incredibly valuable and eye-opening, though I noticed most of it is very agency-focused. I also went through the AI Foundations part in Liam’s classroom—it was really well-organized and gave me a solid understanding of the basics. Here’s my situation: I’m not fully committed to starting an agency right away. I do dream of building an agency eventually, but for now, my focus is to learn AI automation thoroughly, earn through automation, get clients, and build a strong foundation for the future. My main question: Which content should I focus on first as a beginner? I’ve seen creators like Nate Herk and Nick Saraev, who focus more on earning and freelancing with AI automation. Should I start with their approach, stick with the agency-focused content, or combine both? How can I structure my learning to start earning while building a strong foundation? I’d really appreciate advice from anyone who has walked this path. Liam’s guidance has been incredible so far, and I’m grateful for this community—I just want to make sure I start on the right track. Thanks a lot for any guidance you can share 🙏
0 likes • Jan 15
@Shafi Ul great, how are you doing with it ?
0 likes • Jan 15
@Shafi Ul same on my side

Nov '25 •
Voice to Text that Nate Uses on his videos
Hey guys, does anyone know what software Nate uses for Voice to text? Would this work on Windows? For example in this video at 28:52 mark. https://www.youtube.com/watch?v=zWLZ3bVVwD8&list=PLPvKjjMeYqEr2PpQz097GC9ms-aoOInlC&index=92
1 like • Nov '25
I think elevenlabs
1-10 of 29

@henry-buisseret
I help B2B SaaS scale revenue and efficiency with AI: Lead gen, proposal automation, chatbots, prospect research
Active 4h ago
Joined Jul 3, 2025
INFP
Belgium
Powered by