Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Testosteron Reload
44 members • Free
Effizienzheld_Automation
177 members • Free
Builders Lab
497 members • Free
AI Academy
127 members • Free
NextAutomation - Sphere
324 members • $49/month
KI Builder
336 members • Free
AI Income Lab
2.9k members • $29/month
KI Automatisierungs Hub
368 members • Free
KI-Agenten & Automationen
321 members • Free
37 contributions to KI Bezirk

Nov '25 •
Bereitstellen von n8n auf Google Cloud Run
Viele Teams wünschen sich eine einfache, skalierbare und kostengünstige Möglichkeit, n8n für ihre KI-Workflows selbst zu hosten, ohne Server verwalten zu müssen. Mit Cloud Run können Sie das offizielle n8n-Docker-Image mit wenigen Befehlen ausführen, es mit Cloud SQL verbinden, um persistente Daten zu erhalten, und Gemini mit Google Workspace verwenden, damit Workflows Dinge wie E-Mails, Kalender und Dateien verarbeiten können. Darüber hinaus eignet sich das gleiche Setup gut für fortgeschrittenere Fälle, z. B. das Überprüfen von GitHub Pull Requests oder das Abrufen von Erkenntnissen aus BigQuery. 👉🏻 Den vollständigen Blogbeitrag von Google Cloud zu diesem Thema finden Sie unter: https://cloud.google.com/blog/topics/developers-practitioners/deploy-n8n-on-cloud-run?hl=en
Nov '25 •
Anthropic Tutorial -Token NICHT verbrennen
Anthropic gerade ein solides Tutorial veröffentlicht, wie man Token NICHT verbrennt. Manchmal verbrennt Ihr KI-Agent 150.000 Token, bevor er Ihre Anfrage überhaupt gelesen hat. Hier ist der Grund: → 50 angeschlossene MCP-Server → 1.000 Tools, die in den Kontext geladen werden → Tabellenkalkulation mit 10.000 Zeilen wurde zweimal durchlaufen, nur um Daten zu kopieren Das ist ein massiver Overhead, der die Effizienz Ihres Agenten beeinträchtigt. Die Lösung? Codeausführung mit MCP. Anstatt alles im Voraus zu laden, schreiben Agenten Code für: → Laden von Tools bei Bedarf → Filtern von Daten in der Ausführungsumgebung → Überspringen Sie das Aufblähen des Kontextfensters Ergebnis: Gleiche Aufgabe, 2.000 Token statt 150.000 Das ist eine Reduzierung der Token-Nutzung um 98,7 %. Anthropic hat gerade das Tutorial veröffentlicht, das genau zeigt, wie das funktioniert. Und das Beste daran? Ihre Agenten können jetzt Tausende von Tools verwalten, ohne ins Schwitzen zu geraten (oder Ihr Budget zu sprengen).
2
0
Nov '25 •
ChatGPT-Tools in n8n
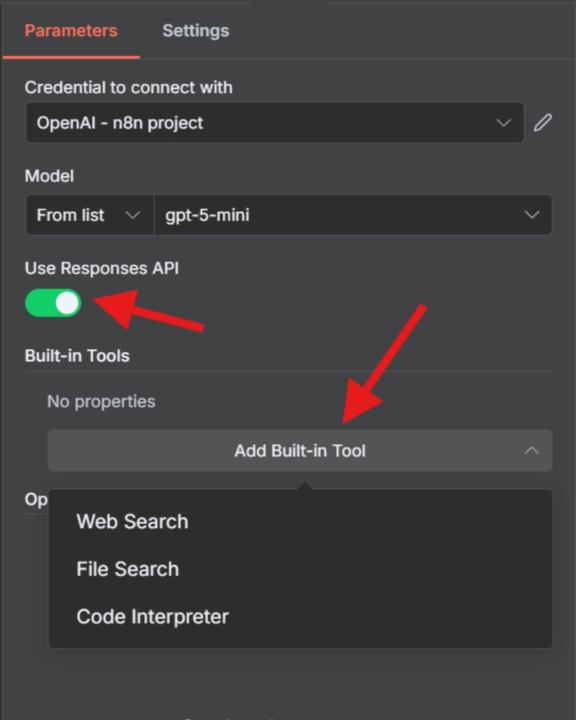
Web Search, File Search und Code Interpreter sind jetzt direkt in n8n verfügbar. Keine zusätzliche Einrichtung, keine externen APIs. Hier ist, was neu 👇 ist WEBSUCHE 🔍 Durchsuchen Sie das Web genau wie ChatGPT. Sie müssen keine eigene Suchlogik erstellen. Wählen Sie zwischen niedriger, mittlerer oder hoher Suchkontextgröße. DATEISUCHE 📝 Haben Sie bereits einen Vektorspeicher in OpenAI? Geben Sie einfach Ihre Shop-IDs ein. Der Knoten verbindet sich automatisch mit Ihrem Vektorspeicher. Es ist kein separates Vektor-Setup oder Einbettungsknoten erforderlich. CODE-INTERPRETER ⚙️ Führen Sie Python-Code in einer Sandkastenumgebung aus. Ideal für Datenverarbeitung, Berechnungen und On-the-Fly-Analysen. Und das ist noch nicht alles... UNTERSTÜTZUNG 💡 DER ANTWORT-API n8n unterstützt jetzt die neue Responses-API von OpenAI, den Next-Gen-Ersatz für Chat-Vervollständigungen. Warum das wichtig ist: - Eingebauter Gesprächsspeicher - Native Tool-Integrationen - Einfachere Zustandsverwaltung Perfekt für mehrstufige Automatisierungen und Workflows im Agentenstil. Es ist nicht erforderlich, den Chatverlauf bei jedem API-Aufruf erneut zu senden.
2
0
Oct '25 •
Anfängerfehler der RAG
Einer der größten Anfängerfehler der RAG: die Verwendung von Vektorspeichern für strukturierte Daten. Traditionelle Vektor-RAG scheitern in der Regel kläglich, wenn sie mit strukturierten Daten aus Tabellenkalkulationen und relationalen Datenbanken konfrontiert werden. Fragen Sie "Wie hoch ist die Summe meiner Bestellungen?" und Sie erhalten zufällige Stücke, die aus dem Kontext gerissen sind. Keine Berechnungen, keine Gruppierung. Nur halluzinierte Antworten. Der klügere Ansatz? Abfrage in natürlicher Sprache (NLQ). NLQ ist extrem leistungsfähig, wird aber bei KI-Agenten heute zu wenig genutzt: Blitzschnelle →: Direkte SQL-Abfragen liefern genaue Ergebnisse in Millisekunden → Keine Halluzinationen beim Rechnen: Echte Daten, echte Berechnungen: kein KI-Rätselraten → Komplexe Vorgänge: Automatische Verknüpfungen, Gruppierungen und Aggregationen über mehrere Tabellen hinweg So funktioniert's: → Benutzer fragt im Klartext → KI versteht Ihre Datenbankstruktur (oder greift auf Tools zu, die dies können) → Führt SQL-Abfragen direkt aus → Gibt fast sofort präzise Berechnungen zurück Tipps zur Umsetzung: - Speichern Sie Tabellenkalkulationsdaten in Ihrer relationalen Datenbank, nicht als Vektoren (JSONB-Schemata verarbeiten praktisch unbegrenzte Schemata) - Verwenden Sie READ-ONLY-Datenbankbenutzer und sperren Sie den Zugriff auf bestimmte Tabellen, um Prompt-Injection-Risiken zu vermeiden - Kombinieren Sie Retrieval-Methoden: Lassen Sie Ihren Agenten SQL für Berechnungen, Vektoren für die semantische Suche, Diagramme für Beziehungen usw. auswählen. Vektordatenbanken sind nicht immer die Antwort. Sie werden oft als die magische Lösung verkauft, aber sie haben ernsthafte Schwächen bei strukturierten Daten. Verwenden Sie das richtige Werkzeug für die jeweilige Aufgabe.
3
0
Oct '25 •
LLM Workflow vs. Agentic Workflow vs. AI Agent
Spannender Kosten/Nutzen Vergleich mit verschiedenen Setups und LLMsund interessante Leanings: - es muss nicht immer der komplexeste Setup sein - und auch nicht immer das teuerste LLM - Kostenoptimierung ist im produktiven Einsatz ein enorm wichtiger Hebel Wer es selbst mal ausprobieren will, kann sich hier den n8n-Workflow runterladen: https://drive.google.com/file/d/1Nts1G5MvwU2UiobPyhNSgO7WcBRLJl_G/view Quelle:https://x.com/PawelHuryn/status/1981036301060096371
2
0
1-10 of 37

@elmir-winn-6837
Digitalisierung-Experte, Prozesssteuerung und KI Automatisierung.
Active 3d ago
Joined Jul 11, 2025