Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
Automation Network
7.1k members • Free
AI Automation Club
723 members • Free
AndyNoCode
34.7k members • Free
n8n Templates ⭐️
1.4k members • Free
Brendan's AI Community
25.8k members • Free
n8n ⭐
1.2k members • Free
AI Automation Skool
2.4k members • Free
AI Pioneers
8.5k members • Free
AI Outbound Academy
2.6k members • Free
19 contributions to Brendan's AI Community

7d •
Every n8n builder hits this problem. I just built the solution.
I just shipped my first n8n community node. I built it because workflows that ran perfectly on 10 items kept throwing API rate limit errors on 500. The only workaround most people know is the Wait node where you literally guess a delay and hope it's enough. So I built the Rate Limiter node to fix this properly. Here's how it works: 1️⃣ Check your API docs for the rate limit (Gemini 2.5 Flash = 10 req/min, Airtable = 5 req/sec) 2️⃣ Drop the Rate Limiter node before your API call or HTTP node 3️⃣ Set the exact number, requests per second or per minute 4️⃣ Run your workflow. The node automatically processes each item with the right delay in between, ensuring every single item goes through without hitting the API limit. No more guessing the delay time. Now live on n8n Cloud ✅ To install: Search "Rate Limiter" directly in your n8n canvas and drop it in. For more details, Here is the npm link 👇 https://www.npmjs.com/package/@divyanshu00

0 likes • 7d
@Brendan Jowett Thanks
18d •
Shipped: A Chrome Extension That Transfers Your AI Context to Any LLM in One Click
Last week I shared how Claude's usage limit was blocking me mid-project. Today ContextShift is officially live on the Chrome Web Store. 🎉 For anyone who missed the story: I kept hitting Claude's usage limit mid-project. Instead of accepting it, I built ContextShift. A Chrome extension that captures your full AI conversation and transfers it to any LLM in one click. Claude. ChatGPT. Gemini. Never lose your context again. Install it here 👇 https://chromewebstore.google.com/detail/contextshift/klfncokllkgddppfmnfikdnepikkkkbo
0 likes • 18d
If anyone here is exploring n8n, AI agents, or workflow automation and wants help building production-style automations, I am offering mentorship/calls around: → n8n workflows → AI agent systems → automation architecture → real client implementations Happy to help fellow builders 🚀 You can connect with me here: topmate.io/divyanshubistudio
25d •
I replaced hours of manual lead research with one n8n workflow. Here's how it works.
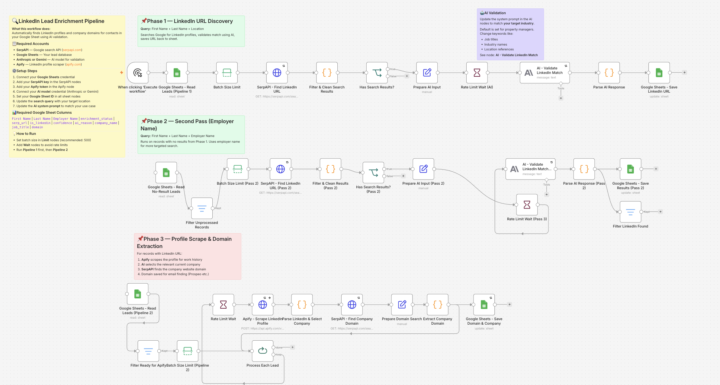
Finding someone's LinkedIn profile, company domain, and verified business email manually takes hours. Multiply that by thousands of contacts, it becomes a full-time job. To explore this problem, I built an automated Lead Enrichment Pipeline in n8n that: ✅ Discovers professional LinkedIn profiles via SerpApi ✅ Validates profile matches using Claude Haiku ✅ Extracts relevant company info by scraping profiles via Apify ✅ Identifies business domains using Google Knowledge Graph ✅ Enriches contact data with verified emails via Prospeo ✅ Validates email deliverability using ZeroBounce ✅ Produces an outreach-ready dataset in Google Sheets The interesting part wasn't connecting APIs, it was handling the edge cases: → Multiple people with the same name → Incomplete professional profiles → Multiple current employers → Company name variations → Missing or outdated information A large portion of the work went into building decision logic that improves data quality before enrichment even happens. Projects like this remind me that automation isn't just about moving data between tools, it's about creating reliable workflows that can make intelligent decisions at scale. I'm publishing this as a free n8n template soon. What are the most challenging data quality issues you've encountered while building enrichment or outreach workflows?
May 30 •
Claude Kept Hitting Its Limit. So I Shipped the Fix 🚀
If you use Claude daily — you know this pain. You're deep in a conversation. Claude knows your project inside out. Architecture. Requirements. Every decision. Then — ⚠️ Usage limit reached. And now you have two terrible options: → Wait for the limit to reset and lose all momentum → Switch to ChatGPT and re-explain everything from scratch I got tired of it. So I built ContextShift — a Chrome extension that carries your full conversation context to any LLM the moment you hit the limit. Here's what it does: → Auto detects Claude, ChatGPT and Gemini → Captures your full chat session in one click → Saves it to your personal context library → Transfers it to any LLM instantly → Never lose your context again I built this while learning Claude Code. The tool that caused the frustration — helped me build the solution. Watch the full demo here 👇 https://youtu.be/2vKo1q6THNo?si=HPsq4Pv5Tgflgk-k Not on the Chrome Web Store yet. DM me if you want early access. 🚀
0 likes • May 30
💡 One more thing — Beyond building tools, I help professionals automate their workflows using AI. Free discovery call — we'll identify exactly where AI can save you the most time. No pitch. Just value. Book your free session here 👇 https://topmate.io/divyanshubistudio
0 likes • 29d
@Samadh Khatri yes it does that
May 20 •
5 n8n tips most beginners never figure out (free carousel)
Expressions → Triggers → Error Handling → AI Agents → Shortcuts. All in one deck. Drop a comment if you want the full breakdown on any of these.
1-10 of 19

@divyanshu-gupta-6220
A space for creators, builders, and automation lovers. Learn how to combine AI + automation to create tools that save hours every day.
Active 1h ago
Joined Mar 23, 2026
Powered by