Activity
Mon
Wed
Fri
Sun
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
What is this?
Less
More
Memberships
AI Workshop Lite
44.3k members • Free
Autonomee: Claude Code Pro
257 members • $97/month
Subscribr
1.9k members • Free
Chase AI Community
73.9k members • Free
The RoboNuggets Community
1.1k members • $97/month
Openclaw Labs
2.3k members • Free
Agent Zero
2.7k members • Free
Claude Code Pirates
323 members • Free
Agentic Labs
649 members • $29/m
9 contributions to Agent Zero

Mar 21 •
My "perfect" model setup
This setup has been working great for me. The chat and web browser models are both using the Ollama cloud. This is about as good as it gets, I think, without paying the Frontier model pricing. Chat: qwen3.5:cloud Web Browser Model: qwen3-vl:32b-cloud Embedding: sentence-transformers/all-MiniLM-L6-v2
1 like • Apr 2
@Justin Brown right they are solid.
0 likes • Apr 27
@Sean Branch good grief, don't be that guy
Mar 31 •
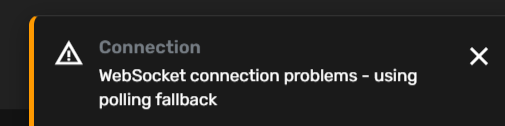
Bug in v1.5 - websocket errors
I keep getting this error after I upgraded to v1.5. Can you share how I might be able to troubleshoot this or is this is a bug in 1.5? I am running on a Hostinger VPS with Dokploy and Ubuntu.
1 like • Mar 31
@Theo Wilson sorry if this is a dumb question but which plugin?
0 likes • Apr 1
@Alessandro Frau these seemed like it self-resolved. Apparently just a glitch in the matrix.

Mar 20 •
Connecting AgentZero to Signal
Hi guys, I'm just strating with A0 and I wanted to know if there's a way to connected it to the signal cli. Even if it's not a native way inside of agent zero
0 likes • Mar 21
@Satomune Mie spammer
Mar 13 •
LM Studio Gurus
Does anyone here happen to be a guru with LM Studio, especially when it comes to optimizing different models? Windows (unfortunately ) with an NVIDIA RTX PRO 4500 Blackwell 32 GB GPU. I want to run the best models I can for A0 locally. It's working but I just have a feeling I could optimize LM Studio more.
Mar 4 •
Agent Zero Stalling
I have two different instances of A0, one on my desktop and one on a vps. Both are running different models. The desktop is running a local model through Ollama. I see BOTH stalling out and even with nudges, they struggled to move along. Is that normal? I am assuming it is something I am doing.
0 likes • Mar 4
@Daniel ITwizard Thanks! I started getting LM Studio installed again, but there was something I was doing that was being blocked by LM Studio. Of course, I can't recall what it is. I will look at Try a mixture of experts model like the Qwen3.5-35B-A3B
0 likes • Mar 5
@Alessandro Frau , @Joshua Cunningham @Jan Tomášek - is it possible to remove and block this bot?
1-9 of 9

@dale-thomas-9967
AI explorer. Father. BBQ guy. Founder of APIMonitor.io, real-time cost tracking for AI agencies who want margins, not just revenue numbers.
Active 2h ago
Joined Feb 28, 2026
Powered by