Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI SEO Engine
40 members • $47/month
212 contributions to Master AI Automation

9d •
👋 Let's connect beyond Skool!
Drop your Instagram, LinkedIn, Facebook, X, YouTube, or wherever you're most active in the comments so we can stay connected and support each other's journey. And while you're at it, answer this: What's one thing you're building, learning, or excited about right now? I always enjoy seeing what members of this community are working on, and it's a great way for all of us to stay connected, share ideas, and celebrate wins together. Looking forward to connecting with you all!


2 likes • 8d
I don't do social media but I do have a YouTube channel (that I hope to grow one day!!!) youtube.com/@growthenablers
10d •
New challenge; how to cluster 1000+ records
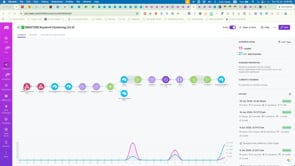
Following my challenge of semantically grouping 1000+ records I now have a follow-up challenge where I need to cluster a sub-set of the semantic relevance output. As before my current scenario appears limited to processing a few hundred records. (In the video, I show how it processed 238 just 7 days ago and made me think it's done and dusted). But I just tried using the same scenario to process 1300 records and the agent didn't even try; it processed 0 records (effectively giving up before it even began). So this time I want to be proactive and not get myself in the mess that caused me to consume 17000 credits in less than an hour! Thanks to @Aashiya Bi for helping me come up with a 2-part scenario I think will work for large-scale semantic relevance processing. But how do I do something similar for this follow-up scenario. What do I need to change to my current scenario or LLM so that the scenario can execute. Any ideas up front will be most welcome. cc. @Mohamed Jahar
0 likes • 10d
@Aashiya Bi Thank you. Here is an update... Scenario name: 🧪 [TESTING] Keyword Clustering [v2.1] Scenario URL: https://us2.make.com/93886/scenarios/5403076/edit - Swapped out the AI Agent for a chat completion module - Swapped out the LLM to see if it could handle higher context; now using openai/gpt-5-mini The result was the chat completion 'appeared' to do better. For example, it retained the desired JSON structure. But it still failed to execute the desired result: 1. It only processed 754 records out of the 1318 it found 2. It doesn't look like it actually followed the instructions. In the screenshot comparison between 2.0 and 2.1 you'll see version 2.0 clearly marks different keywords as either: Primary, Secondary or Supplementary. And where it's secondary or supplementary, you can see there is a difference between record ID and the Primary Record ID. In contrast, 2.1 has marked EVERY keyword as Primary Keyword. This means NO clustering is actually happening. (I didn't open all 754 but I opened a lot and not one keyword came up as a secondary or supplementary).
0 likes • 9d
@Aashiya Bi It's definitely to do with large volume of data. I don't understand how the group by will work as the LLM needs to see the whole list to be able to group them in clusters. A filter is no good as we've already filtered and got all the records we want. What about using a text string instead of an array? Can an LLM read a text string (CSV?) easier than an array?). If so, how do I map/process the array to join the be joined into a long text string as we only need the record ID and the keywords.
16d •
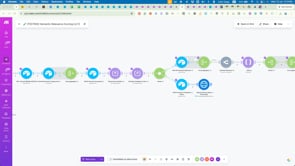
OUCH! OUCH! OUCH! 17000 records burned by runaway Make scenario
OMG! Did I just get burned. Easily my biggest ouch in the 18 months I've been using Make. I apologise in advance for the poor quality video, (a lag between my voice and screen) but hope you can hear my frustration and start to see my problem. In a nutshell, how do you get a scenario to process batches (of Airtable data) and then end cleanly when it's iterated through all the records. Alternatively, what AI Agent or AI model/LLM could I use (via OpenRouter) that would process 1000s of records). That would be the easiest solution.
0 likes • 10d
PS. @Aashiya Bi I think I answered my own question... I changed the limit to 50 and tested it on 76 records. They all got updated in Airtable via just two runs of the second scenario. The operations count and execution time seem reasonable and feels like a nice balance of limits and operations. I will likely test this on a few hundred next. I even restructured the data structure to pass through more variables from 2.2A so that 2.2B didn't need as many variables. This also helps to reduce the operations count if 2.2B needs to multiple batch (x50) runs. Here are the current iterations of the blueprints as they are named and working: ✅ [TESTED] Semantic Relevance Scoring [v2.2A] [https://us2.make.com/93886/scenarios/5392459/edit ] ✅ [TESTED] Semantic Relevance Scoring [v2.2B] https://us2.make.com/93886/scenarios/5392468/edit Any concerns or have we cracked the solution?
0 likes • 10d
PPS. I ran it on 549 records and this was the result! Scenario A produced 11 output operations: - 10 operations with collection arrays of 50 items - One operation with a collection array of 49 items Scenario B successfully executed 11 times and processed each payload of keys!
21d •
Website owners: what platform are you using right now? 👇
Just drop one word in the comments: WordPress, Shopify, Webflow, Wix, Framer, Custom, or None Let's see which platform wins. 🏆

1 like • 15d
@Mohamed Jahar What led to that decision? How easy or difficult was the migration process?
1 like • 14d
@Mohamed Jahar Awesome. If you need help with SEO side of things, please let me know. We've got some real solid frameworks workflows in place with improving SEO and restructuring content. While many claim SEO is dead, that is not our experience!
14d •
AI-Drafted Email Replies in Your Own Voice (Claude + Gmail)
The Problem: Busy professionals spend 1+ hour daily replying to emails. Most replies follow predictable patterns - same tone, same structure, yet still get written manually one by one. The Solution: Connect Gmail to Claude, teach it your writing style as a reusable Skill, and let it draft replies automatically every morning. How It Works: 1️⃣ Connect Gmail - Use the official Gmail connector in Claude Desktop (Customize → Connect Your Apps → Gmail). 2️⃣ Create a Skill from your writing style - In a new chat, prompt: "Go through my emails from the last 30 days, learn how I reply, and turn that into a skill." Claude reads your sent mail and extracts your patterns - greeting style, tone, length, sign-off, even how you negotiate or escalate. 3️⃣ Save the Skill - Claude packages everything into a .skill file. Click Save Skill and it's stored permanently. This is the key step: a Skill is a reusable instruction file Claude loads automatically whenever it's relevant. You build it once, no re-explaining your style in every chat. 4️⃣ Schedule it - In Claude Cowork, create a daily scheduled task: "Go through all of my unread emails every day at 8 AM and draft responses using my Gmail reply skill." The Result: Every morning, draft replies are waiting in your Gmail Drafts folder — written in your voice. You review and send in minutes instead of an hour. Why Skills Matter Here: Without a Skill, Claude drafts generic replies. With a Skill, every draft sounds like you and the same Skill works across future automations too (follow-ups, client updates, proposals). Key Design Decision :Keep it draft-only. Nothing is auto-sent without review. Approving a good draft takes seconds; an auto-sent bad reply can damage a client relationship. Setup time: ~10 minutes | Tools: Claude (Pro) + Gmail | Code required: None
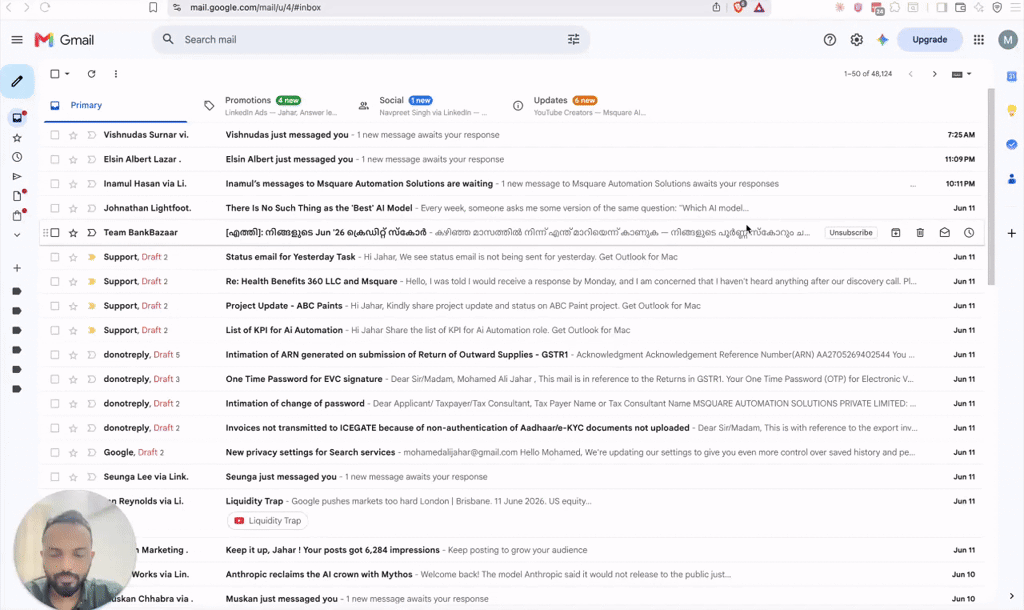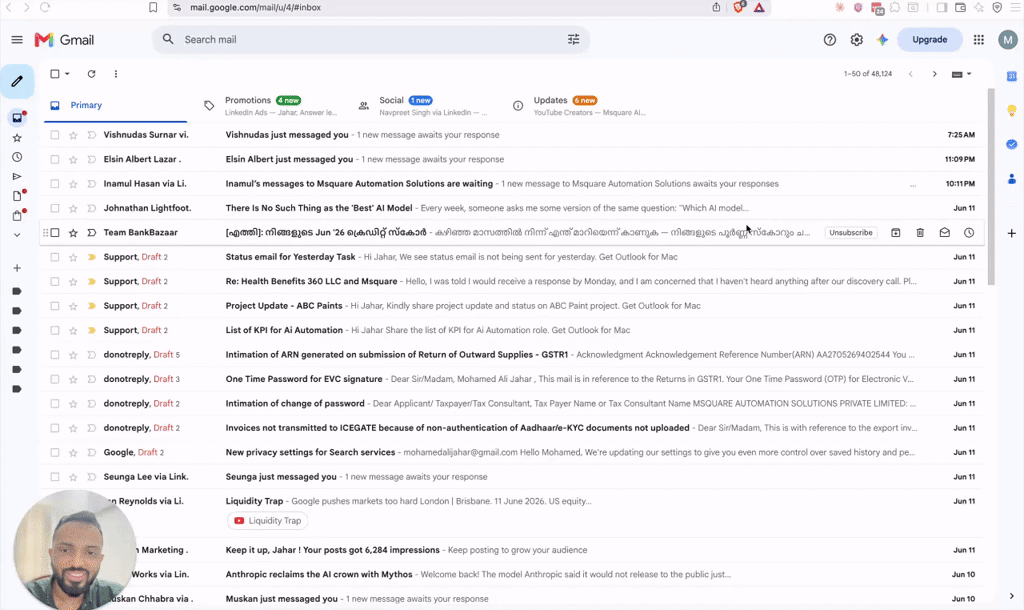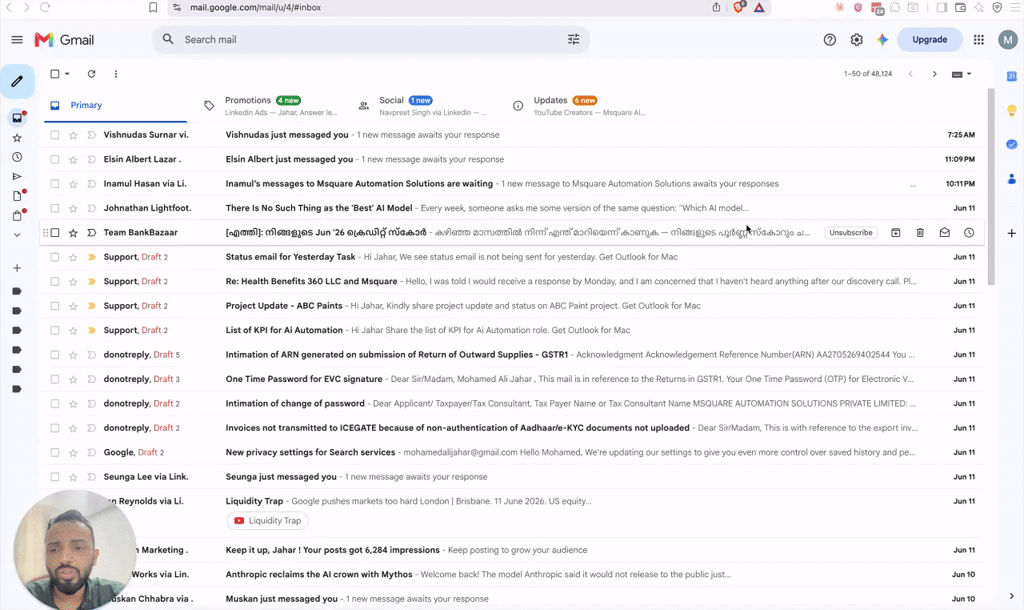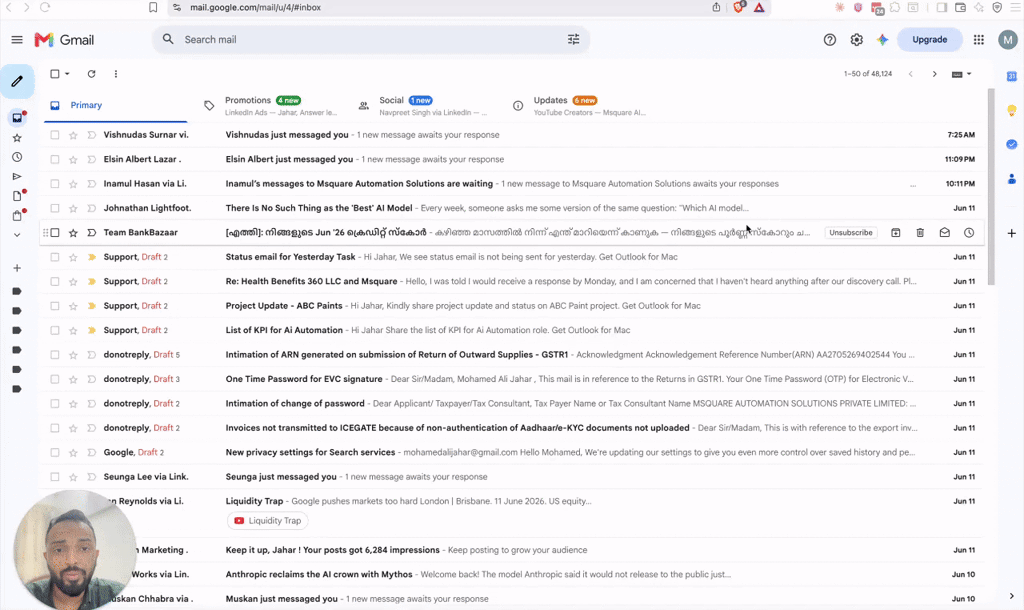
3 likes • 14d
Love this!!!
1-10 of 212
@colin-clapp-1624
Growth enabler behind the 'one-click' SEO/AEO/GEO philosophy: Systemised content optimization that compounds content ROI 🚀
Active 8d ago
Joined Apr 28, 2025
Powered by