Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI Automation Vault
18.7k members • Free
Early AI-dopters
1.3k members • $77/month
AI with Apex - Learn AI w/ Max
367 members • Free
AI Accelerator
19.6k members • Free
AI Automation Society
417.7k members • Free
Tech Snack | Vibe Coding & AI
19.4k members • Free
AI Agent Developer Academy
2.8k members • Free
Ai Titus
909 members • Free
AI Workshop Lite
28.8k members • Free
102 contributions to Ai Titus

Apr 4 •
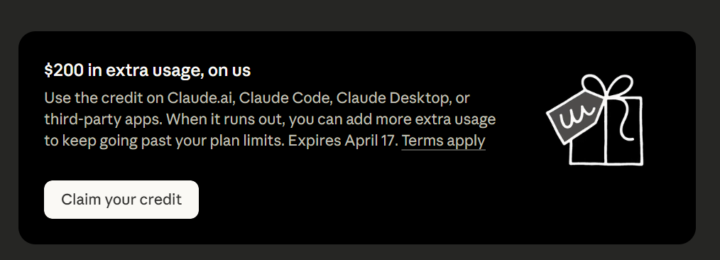
🤑 Free Claude Code Credits!
You might want to log into your Claude dashboard and claim your free credits! https://claude.ai/settings/usage
5
0

Mar 14 •
How I Use Claude to Run My Entire Workday
Turn Claude into a personal operating system that tracks your tasks, scans your tools, and keeps you on target from morning to close. Set it up in 10 minutes. https://aititus.com/content/How_I_Use_Claude_to_Run_My_Entire_Workday
1 like • Apr 1
@Titus Blair Lovely... thanks. 🙏🏻
Jan 30 •
Clawdbot - OpenClaw - Lobster soup? :P
A post I had to share from @Mišel Čupković (make sure you post here in AiTitus too :P you have great stuff) Who: Jamieson O’Reilly Articles on X: Part I: hacking clawdbot and eating lobster souls Part II: eating lobster souls Part II: the supply chain (aka - backdooring the #1 downloaded clawdhub skill) Part III: eating lobster souls Part III (the finale): Escape the Moltrix Be careful out there people! 🙏🏻
3 likes • Jan 31
@Titus Blair I really have to start pruning communities I'm involved in. 😂 I'll make sure to share more on here. 🙌🏻
0 likes • Feb 19
@Titus Blair ☺️
Feb 9 •
🤖 Shannon is your fully autonomous AI pentester
Fully autonomous AI hacker to find actual exploits in your web apps. Shannon has achieved a 96.15% success rate on the hint-free, source-aware XBOW Benchmark. ❤️ Shannon is open source (AGPL v3) 16.3K ⭐️

1 like • Feb 9
Oopsy, forgot to include the repo. 🙈
1 like • Feb 10
@Henryk Soto 💯
Feb 8 •
🍌🎨 G👀gle PaperBanana
Paper Banana: AI Multi-Agent System for Publication-Quality Diagrams. Unlike single-model approaches, Paper Banana uses 5 specialized AI agents working together to create, critique, and refine technical diagrams with stunning accuracy. How It Works: PaperBanana implements a two-phase multi-agent pipeline with 5 specialized agents: - Phase 1 -- Linear Planning: - Retriever selects the most relevant reference examples from a curated set of 13 methodology diagrams spanning agent/reasoning, vision/perception, generative/learning, and science/applications domains -Planner generates a detailed textual description of the target diagram via in-context learning from the retrieved examples -Stylist refines the description for visual aesthetics using NeurIPS-style guidelines (color palette, layout, typography) - Phase 2 -- Iterative Refinement (3 rounds): Visualizer renders the description into an image (Gemini 3 Pro for diagrams, Matplotlib code for plots) Critic evaluates the generated image against the source context and provides a revised description addressing any issues - Steps 4-5 repeat for up to 3 iterations Open source ❤️ implementation and extension of Google Research’s PaperBanana ***Official code coming soon...
3
0

1-10 of 102

@bili-piton-3689
It's not a bug, it's an unexpected learning opportunity.
Active 2h ago
Joined Aug 19, 2025
INTP
Dubai